

Napsáno
AI tým
Publikováno
Zrychlení Sonaru prostřednictvím spekulací
Spekulativní dekódování zrychluje rychlost generování Velkých jazykových modelů (LLM) tím, že používá rychlý a malý návrhový model k vytvoření kandidátů na dokončení, které jsou ověřovány větším cílovým modelem. V rámci tohoto schématu, místo aby drahý cíl vyprodukoval jediný token, jsou emitovány více tokenů v jednom kroku. Zde představujeme detaily implementace různých druhů spekulativního dekódování, aplikovaných na Perplexity k redukci latence mezi tokeny na modelech Sonar.
Spekulativní dekódování
Spekulativní dekódování využívá strukturu přirozených jazyků a autoregresivní povahu transformátorů ke zrychlení generování tokenů. I když větší modely, jako Llama-70B, nesou více znalostí než menší, jako Llama-1B, v některých jednodušších úlohách vykonávají podobně. Tento překryv naznačuje, že určité sekvence jsou lépe generovány levnějšími modely, zatímco složité problémy zůstávají pro větší modely. Výzvou je určit, které dokončení jsou lepší a zda generování menšího modelu je stejné kvality jako to větší.
Naštěstí, LLM jsou autoregresivní transformátory: když je dána sekvence tokenů, vydávají pravděpodobnostní rozdělení pro následující token. Navíc, logity odvozené z meziproduktových rysů spojených s tokeny v vstupní sekvenci také naznačují, jak pravděpodobné je, že model vydá přesně tyto tokeny. Tato vlastnost umožňuje spekulaci: pokud je sekvence tokenů generována menším modelem začínajícím od vstupního prefixu, může být spuštěna skrze větší model, aby se zjistilo, jak dobře se shoduje s cílovým modelem. Každý prefix kandidátů je ohodnocen pravděpodobností a nejdelší, který je nad akceptačním prahem, je vybrán. Jako bonus, cílový model také poskytuje následný token zdarma: pokud návrhový model generuje n tokenů, až n + 1 může být emitováno v jednom kroku.
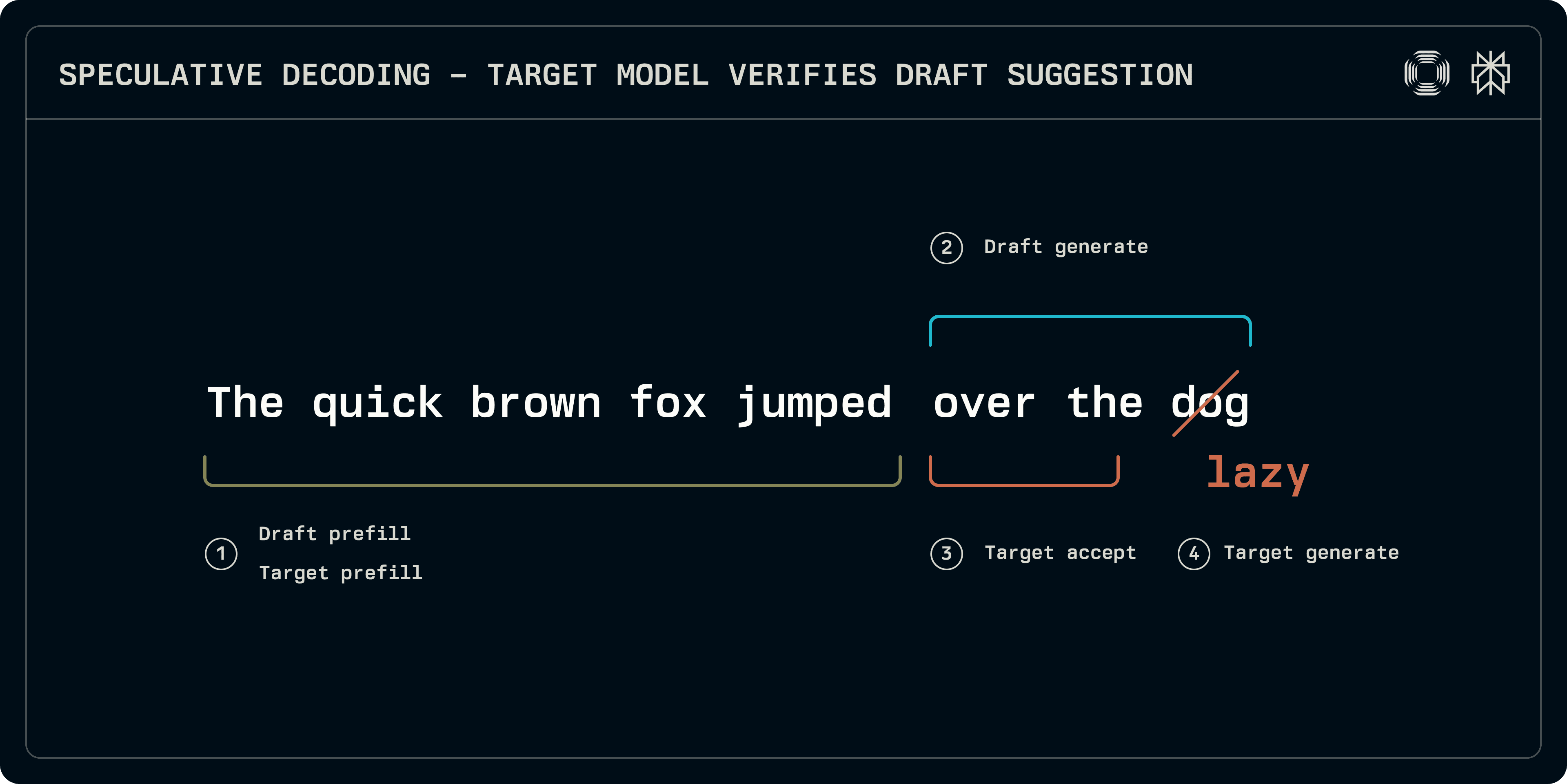
V čase inference může být spekulativní proces vzorkování rozdělen do přibližně 4 fází:
Předvyplnění: jak target, tak návrhové modely musí být spuštěny na vstupní sekvenci, aby zaplnily položky v KV cache. Zatímco některé schémata, jako Medusa, používají jednodušší husté vrstvy pro predikci, v tomto příspěvku se zaměřujeme na transformátorové návrhy, které potřebují své vlastní KV cache.
Generování návrhu: návrhový model iteruje, aby vytvořil určitý počet pevných tokenů. Návrhová sekvence může být lineární nebo model může zkoumat stromovou strukturu až do dané hloubky (EAGLE, Medusa). Zde se zaměřujeme na lineární sekvence.
Akceptace: cílový model běží na návrhové sekvenci, vytváří logity odpovídající každému návrhovému tokenu. Určuje se délka nejdelší přijatelné sekvence.
Generování cíle: protože cílový generuje logity, na nesouladné pozici nebo na konci sekvence logity odpovídají následujícímu tokenu. Tyto logity mohou být vzorkovány, aby poskytly robustní token z cíle, uzavřující sekvenci.
Existuje několik metod pro implementaci spekulativního dekódování. V tomto příspěvku se zaměříme na schémata, která jsme použili k urychlení modelů Sonar pomocí našeho interního modelu 1B, stejně jako na predikční mechanismy, které budujeme pro zrychlení modelů na úrovni DeepSeek.
Cíl-Návrh
Spekulativní dekódování může být dosaženo spojením existujícího malého LLM jako návrhového modelu s cílovým modelem za účelem generování sekvencí kandidátů. V produkci jsme urychlili Sonar pomocí modelu Llama-1B, který byl jemně doladěn na stejném datasetu jako cíl. I když tento přístup nevyžadoval trénink návrhu od nuly, malý model stále využívá značnou kapacitu KV cache a zavádí mírnou režii při předvyplnění, což zvyšuje TTFT.
V rámci tohoto schématu dekodér spekuluje pouze na dávkách určených pouze k dekódování, generuje tokeny prostřednictvím standardního vzorkování během předvyplnění nebo na smíšených dávkách předvyplnění-dekódování. V předvyplňovací fázi jsou cílové logity okamžitě vzorkovány, aby také předvyplnily nově generovaný token v KV cache návrhu. Návrh není zatím vzorkován, ale logity, které produkuje, jsou přeneseny do fáze dekódování.
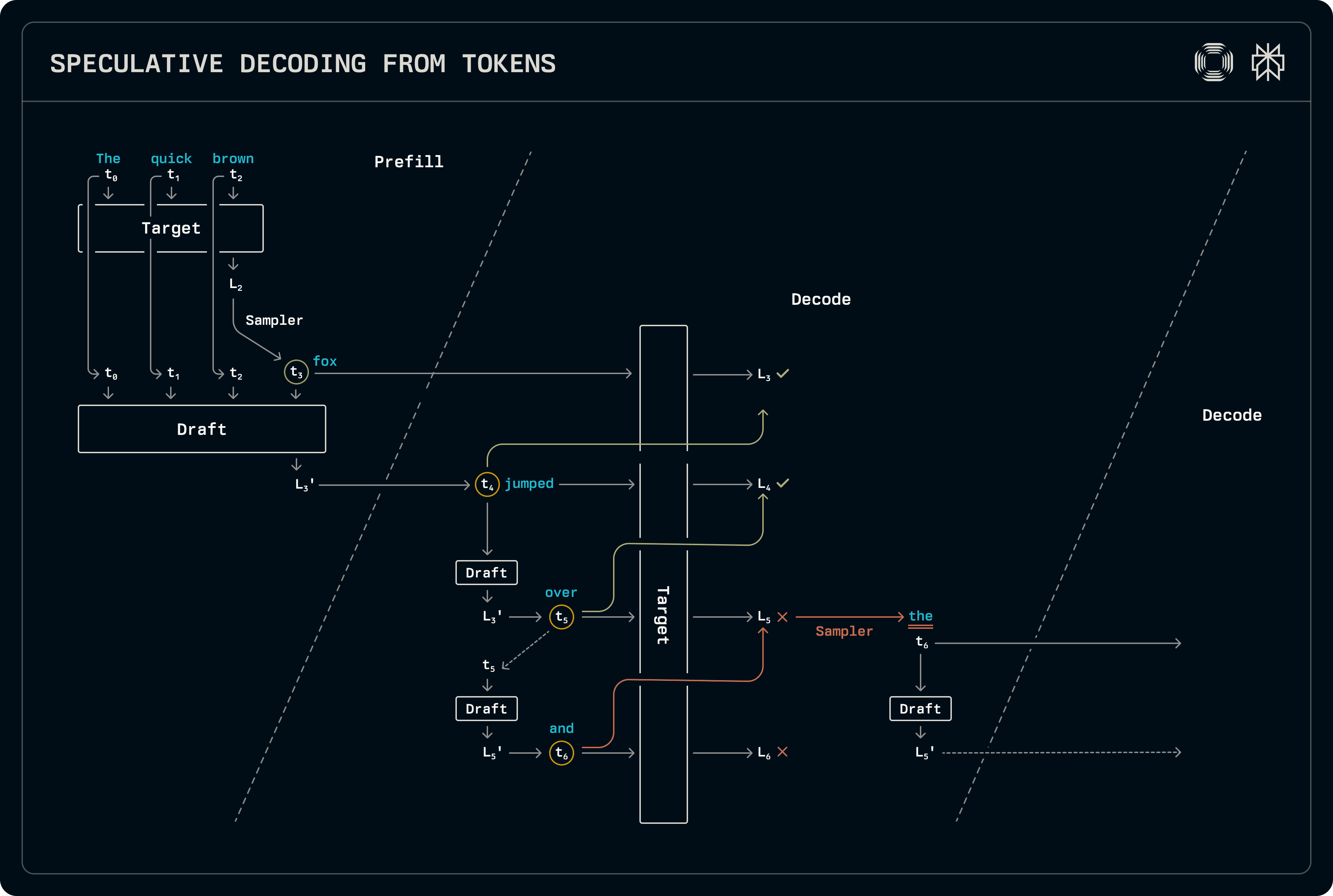
Při dekódování je návrhový model posunut dál, vzorkováním nejlepšího tokenu v každé fázi. Jakmile je dosaženo požadované délky návrhu, tokeny jsou spuštěny skrze cílový model k vytvoření logitů, na jejichž základě vzorkovač identifikuje přijatou délku sekvence. Akceptace je určena porovnáním plných pravděpodobnostních rozdělení z návrhu a cíle. Protože cíl vždy vytváří jednu sadu logitů navazující na akceptovanou sekvenci návrhu, to je vzorkováno, aby se vyprodukoval další výstup. Protože návrhový model zatím neviděl ten akceptovaný token, je znovu spuštěn, aby zaplnil odpovídající položky KV cache na přípravu pro další krok dekódování, opět přenášející logity.
EAGLE
EAGLE je spekulativní dekódovací schéma, které prozkoumává více návrhových sekvencí, generovaných prostřednictvím stromového průchodu pravděpodobných návrhových tokenů. Pevný (EAGLE) nebo dynamicky tvarovaný (EAGLE-2) strom je prozkoumáván pomocí po sobě jdoucích provedení návrhových tokenů, přičemž zvažuje Top-K kandidátů na každém uzlu namísto sledování nejvyššího skórovacího tokenu v lineární sekvenci. Sekvence jsou poté hodnoceny a nejdelší vhodná je vybrána pro pokračování, přičemž také přidává další token z cíle.

Aby bylo dosaženo přesnější predikce, EAGLE návrhový model predikuje nejen na základě tokenů, ale také pomocí cílových rysů (skryté stavy poslední vrstvy) cílového modelu. Nevýhodou EAGLE je potřeba trénovat vlastní, malé návrhové modely, které jsou dostatečně přesné pro generování vhodných kandidátů v rámci rozpočtu nízké latence. Typicky je návrhový model jediná vrstva transformátoru, identická dekódovací vrstvě původního modelu, která je těsně spojena s cílem tím, že se váže na jeho vektory a lm_head projekce. Protože to vyžaduje méně kapacity KV cache, EAGLE má nižší paměťovou náročnost.
Abychom ověřili stromové sekvence v cílovém modelu, musí být použity vlastní masky pozornosti. Bohužel, použití vlastní masky pozornosti pro celou sekvenci výrazně zpomaluje pozornost pro realistické délky vstupů (až o 50 %), což ruší část zrychlení, kterého je možné dosáhnout prostřednictvím spekulace. Z tohoto důvodu jsme ještě nenasadili plné prozkoumávání stromu do produkce, ale místo toho se zaměřujeme na zvláštní případ predikce jednoho tokenu pomocí schémat podobných MTP, která jsou představena v technické zprávě DeepSeek-V3.
MTP
Toto schéma je podobné dekódování návrhu-cíle, s výjimkou použití skrytých stavů spolu s tokeny pro predikci. Musí být provedena trochu více práce v obou fázích předvyplnění a dekódování ve srovnání se standardní spekulací návrhu-cíle. Návrhový model používá jak tokeny, tak skryté stavy: token t_{i+1} je vzorkován z logitů L_i odpovídajících tokenu t_i, které jsou zase odvozeny od skrytých stavů H_i. V důsledku toho musí být vstupní tokenové buffery posunuty o jeden krok doleva vůči vektorům skrytých stavů, které produkuje cíl. Obrázek níže označuje shody použité pro trénink, stejně jako posun během inference.
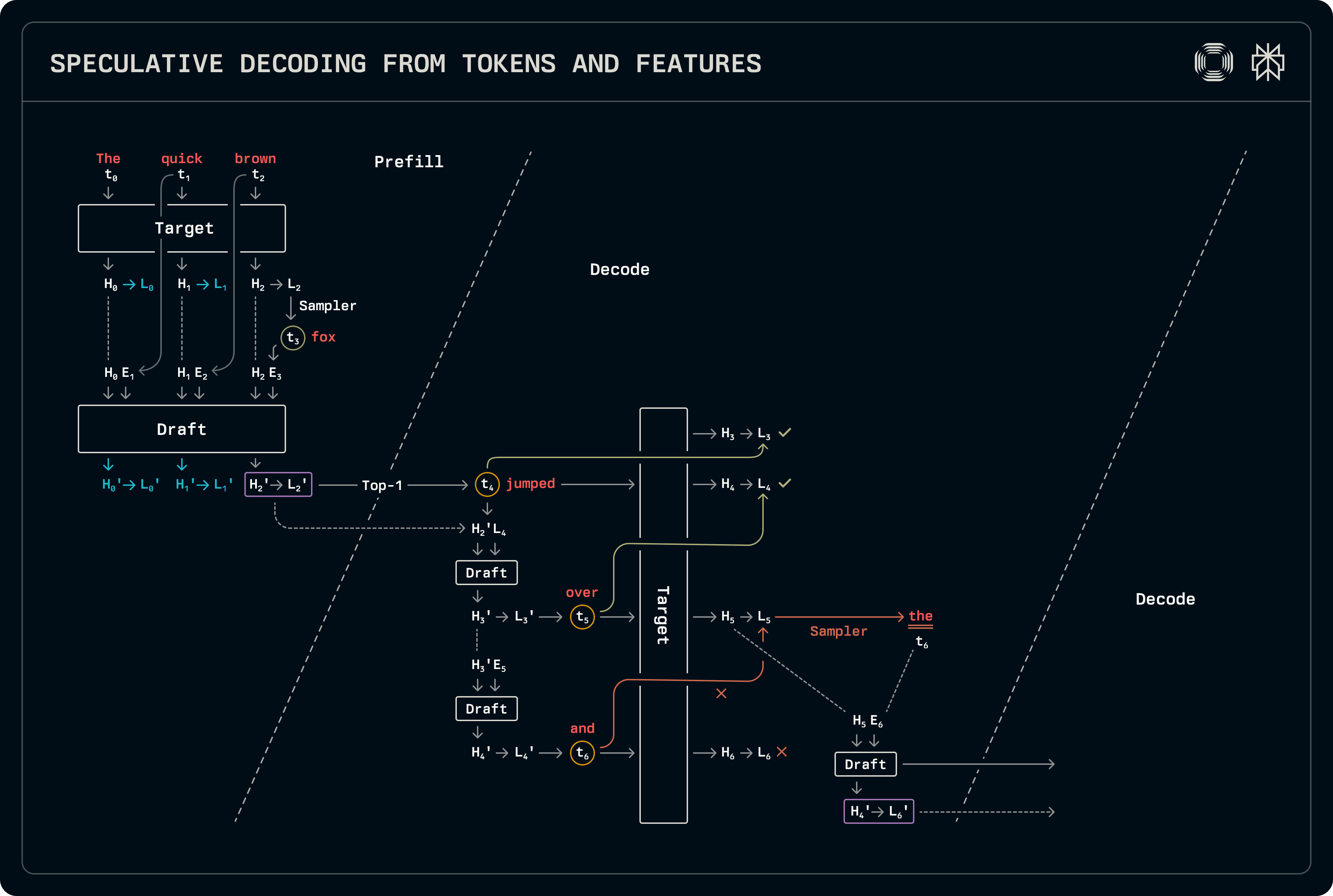
Tok od dekódování je velmi podobný dekódování návrhu-cíle, s výjimkou toho, že jsou přenášeny jak skryté stavy, tak logity. Naše implementace sdílí všechny související vzorkování a zpracování logitů, specializuje se pouze na vyvolání modelu. Když jsou predikována více tokenů, návrhový model používá skryté stavy návrhu pro predikci, čímž také zaplňuje položky KV cache na základě vlastních rysů. V dlouhodobém horizontu to může degradovat přesnost. Následně, když spouštíme návrhový model k naplnění položky KV cache pro cílovou predikci, spouštíme ho na celé sekvenci, bereme přesnější skryté stavy cíle jako vstupy. Protože tyto návrhové modely jsou malé, přidané náklady na zpracování dalších tokenů jsou zanedbatelné.
Trénink MTP hlav
Abychom profitovali z MTP, vybudovali jsme infrastrukturu potřebnou k trénování MTP hlav připojených k našim jemně doladěným modelům na datech Perplexity, běžících na jednom uzlu s 8xH100 zařízeními. Za přibližně jeden den můžeme vybudovat hlavy pro modely od Llama-1B po Llama-70B a DeepSeek V2-Lite. U větších modelů se spoléháme na MTP hlavy vytvořené během procesu jemného doladění.
Cílem tréninku MTP je sladit skryté stavy návrhu a logity extrapolované z cílových skrytých stavů na logity pro následující token a skryté stavy cíle. Protože inference skrytých stavů je nákladná, předem je počítáme pomocí naší implementace cílového modelu optimalizované pro inference, která se používá během tréninku. Abychom však ověřili implementaci inference MTP a zajistili, že číselné rozdíly způsobené kvantizací nebo optimalizacemi nebrání výsledkům, pro odhad ztrát validace a přesnosti plně znovu používáme implementaci inference jak cílového modelu, tak návrhového modelu.
Když se škáluje od datasetu ShareGPT použitého v původním článku na větší vzorky, všimli jsme si, že architektura MTP hlav uvedená a implementovaná v článku EAGLE selhala při trénování pro modely velikosti 70B. Na rozdíl od ShareGPT, který obsahoval vyšší počet kratších sekvencí, trénujeme na o něco menším počtu podstatně delších výzev. Protože původní EAGLE hlavy mírně divergovaly ve struktuře od typického transformátoru, znovu jsme zavedli některé vrstvy RMS normalizace, které byly odstraněny. Zjistili jsme, že to nejen umožnilo tréninku konvergovat, ale také zvýšilo přesnost hlav o několik procentních bodů.

Nejen, že vrstvy normalizace usnadňují trénink, ale znovu zavedení norem je také matematicky intuitivní. MTP hlavy znovu používají vektory a projekce logitů cílového modelu, protože mohou být značné velikosti (asi 2 GB pro Llama 70B). Během tréninku jsou tyto zamrzlé a očekává se, že MTP vrstva se naučí začlenit predikce do stejného vektorového prostoru, jako se naučila projekční vrstva původního modelu během tréninku. Odstraněním norem se očekává, že single MLP se naučí stejnou funkci jako MLP následovaný normou, což brání shodě mezi skrytými stavy návrhu a cílovými modely.
Inference se spekulativním dekódováním
V inferencesním enginu, aby generoval tokeny pro vstupní sekvence, musí být nejdříve seskupeny do přiměřeně velkých dávek, pak musí být přiděleny stránky v KV cache pro další tokeny. Vstupní tokeny a informace o KV stránkách jsou poté zabaleny do vyrovnávací paměti vysílané všem paralelním ranám, které spouští model. Nakonec jsou metadata zkopírována do paměti GPU a model je spuštěn, aby vygeneroval logity, ze kterých je vzorkován následující token.
Na rozdíl od některých implementací, které volně spojují návrh a cílový inference server prostřednictvím wrapperu, který orchestruje požadavky mezi nimi, naše páry návrh-cíl jsou těsně spojené a procházejí generováním v souladu. Rozvržení dávek a přidělení KV stránky je sdíleno mezi modely pro všechny formy spekulativního dekódování: to sjednocuje logiku, která spojuje model s celkovým inferencesním serverem, protože všechny poskytují stejné rozhraní.
Inferencesní runtime na Perplexity je utvářen kolem FlashInfer, který určuje metadata, která musí být vytvořena, aby konfigurovala a naplánovala jadro pozornosti. Vzhledem k tomu, že některé vstupní sekvence tvoří dávku, pro předvyplnění, dekódování nebo ověření je nutné provést práci na CPU, aby se přidělily mezipaměťové buffery a zaplnily určité konstantní buffery používané v pozornosti. Tato práce je navíc k nákladům na rozvržení dávek a přidělení KV stránky, což také vyžaduje latence, které musí být skryty, aby se maximalizovala využitelnost GPU.
I když jsme plně paralelizovali práci na straně CPU a GPU pro inference bez spekulace, zjistili jsme, že rovnováha mezi CPU a GPU pro spekulativní dekódování je složitější. Hlavní výzvou je skutečnost, že počet přijatých tokenů určuje délku sekvence pro následné spuštění, což představuje obtížně se vyhýbající bod synchronizace GPU a CPU. Experimentovali jsme s různými schématy naplánování, abychom co nejlépe skryli latenci práce na CPU.
Rozvržení návrhu-cíle
Navzdory tomu, že je menší než cílový model, když je celý LLM použit jako návrh, stále zavádí značnou latenci na GPU, což poskytuje určité místo, které lze skrýt drahé operace CPU. Protože menší modely neprocházejí výhodami tensorové paralelnosti, existuje nesoulad mezi počtem ran, na které je cílový a návrhový model rozdělen. V naší implementaci běží návrhový model pouze na vedoucím uzlu skupiny TP.
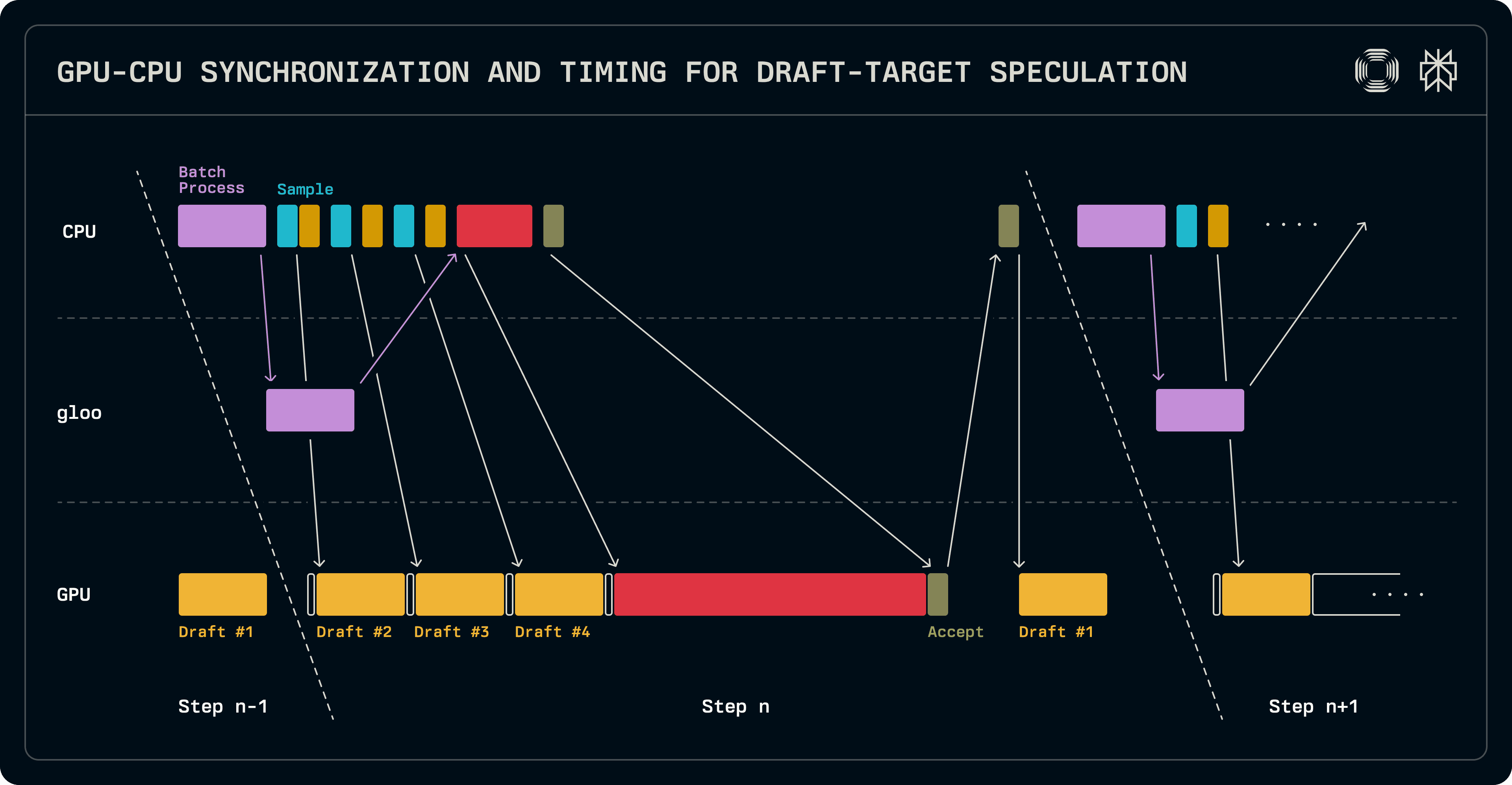
Jak bylo dříve uvedeno, krok dekódování nese logity do následujícího běhu. To nám umožňuje překrýt jedno provedení návrhového modelu s prací na rozvržení dávek na straně CPU. Jakmile je dávka shromážďována, opakované volání na vzorkovač a návrh produkují návrhové tokeny. Současně se dávka pro ověření sestavuje pro cílový model a synchronizuje se s paralelními pracovníky. Cílové logity jsou ověřovány a vzorkovány, aby určili akceptované délky sekvence. V této fázi je nutná synchronizace GPU s CPU, aby bylo možné určit následné délky sekvence. Protože návrhový model je spuštěn pouze na vedoucím uzlu, jeho dávka je nastavena sekvenčně a její provedení je zahájeno, aby zaplnila položky KV cache s dalším tokenem, které cíl vyprodukoval. Logity vytvořené tímto návrhovým během v aktuálním běhu budou použity k vzorkování prvního návrhového tokenu v následném běhu. Nejvíce důležité, zatímco návrh běží, může být naplánována další dávka.
MTP rozvržení pro jeden token
Přestože runtime dosud neposkytuje prozkoumávání stromu ve stylu Eagla, implementovali jsme zvláštní případ tohoto schématu, zvažující lineární sekvenci návrhových tokenů produkovaných modelem velikosti jedné dekódovací vrstvy transformátoru. Toto schéma lze využít pro predikci návrhu, pomocí open-source vah DeepSeek R1. Podpřípad predikce jediného tokenu je zajímavý, protože velké MTP vrstvy dosahují dostatečně vysokých akceptačních sazeb, aby ospravedlnily jejich režii.
Rozvržení MTP je poněkud složitější, protože návrhový model je mnohem rychlejší a skrývá méně latence na straně CPU. Kromě toho je návrh rozdělen spolu s cílovým modelem, což vyžaduje sdílené přenosy paměti pro informace o dávce. Běh začíná přenosem informací o dávce a vzorkováním prvního tokenu z logitů na přenos, podobně jako v předchozím schématu. Poté je cíl spuštěn, aby ověřil tokeny a zpracoval 2 * D tokenů, kde D je velikost dekódovací dávky. To je ideální pro mikro dávkování v Mixture-of-Experts (MoE) modelech přes pomalejší interkonektory jako InfiniBand, protože se dávka rozděluje rovnoměrně na dvě poloviny. Skryté stavy cíle se přenášejí do následujícího běhu návrhu, zatímco logity se předávají vzorkovači pro ověření.

Prováděním omezeného množství další práce na GPU se vyhýbáme synchronizaci mezi CPU a GPU po akceptaci sekvence návrhu. Poté, co jsou vstupní tokeny cílů posunuty, jádro zasune následující cílové tokeny na jejich odpovídající místa. Návrh je poté znovu spuštěn se stejnými informacemi o dávce jako cíl, zaplňuje položky KV cache a vytváří logity a skryté stavy pro následující běh, provádí nějakou redundantní práci na tokenech, které nebyly akceptovány. V těchto situacích je latence nevyužité práce jen stěží měřitelná vzhledem k malé velikosti návrhového modelu. Současně s během návrhu se na CPU určují délky sekvencí a plánování další dávky je zahájeno, aniž by bylo nutné čekat na ukončení práce GPU.
Režie další práce v návrhové vrstvě není v pozornosti nápadná, avšak vrstvy MLP jsou problematičtější. Protože pokyny pro maticové násobení se vyrovnávají na hranici 64 podél rozměru počtu tokenů, pokud zdvojení nevyžaduje citelné více bloků, režie je skryta. U delších návrhových sekvencí je režie nákladnější a schéma používané pro standardní modely návrhu-cíle funguje lépe.
Reference
Rychlá inference z transformátorů pomocí spekulativního dekódování
EAGLE: Spekulativní vzorkování vyžaduje přepracování nejistoty vlastností
EAGLE-2: Rychlejší inference jazykových modelů s dynamickými stromy návrhů
Medusa: Jednoduchý rámec pro zrychlení inference LLM s více dekódovacími hlavami
FlashInfer: Efektivní a přizpůsobitelný pozornostní motor pro inference LLM