

Napsáno
AI tým
Publikováno
Upozorňujeme: Níže uvedené položky byly pro aktuální modely vyřazeny. Zjistěte více o našich API
S radostí oznamujeme pplx-api, navržené jako jeden z nejrychlejších způsobů přístupu k modelům Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b. pplx-api vývojářům usnadňuje integraci špičkových open-source LLM do jejich projektů.
Naše pplx-api nabízí:
Snadné použití: vývojáři mohou používat nejmodernější open-source modely ihned a začít během několika minut s důvěrně známým REST API.
Bleskově rychlou inferenci: náš promyšleně navržený inferenční systém je efektivní a dosahuje až 2.9x nižší latence než Replicate a 3.1x nižší latence než Anyscale.
Ověřenou infrastrukturu: pplx-api je prokazatelně spolehlivé a obsluhuje provoz na produkční úrovni jak v našem Perplexity answer engine, tak v našem Labs playground.
Komplexní řešení pro open-source LLM: náš tým se věnuje přidávání nových open-source modelů ihned, jakmile jsou k dispozici. Například jsme modely Llama a Mistral přidali během několika hodin od spuštění bez předběžného přístupu.
pplx-api je ve veřejné beta verzi a pro uživatele s předplatným Perplexity Pro je zdarma.
Používejte pplx-api pro neformální víkendový hackathon nebo jako komerční řešení pro vytváření nových a inovativních produktů. Prostřednictvím tohoto vydání se chceme dozvědět, jak mohou lidé s naším API vytvářet skvělé a inovativní produkty. Pokud máte obchodní případ použití pro pplx-api, kontaktujte prosím api@perplexity.ai . Budeme rádi, když se nám ozvete!
Výhody pplx-api
Snadné použití
Nasazení LLM a inference vyžadují značné infrastrukturní úsilí, aby bylo poskytování modelů výkonné a nákladově efektivní. Vývojáři mohou naše API používat ihned, bez hlubokých znalostí C++/CUDA nebo přístupu ke GPU, a přesto využívat špičkový výkon. Naše LLM inference také abstrahuje složitost a nutnost správy vlastního hardwaru, čímž dále zvyšuje snadnost použití.
Bleskově rychlá inference
LLM API Perplexity je pečlivě navrženo a optimalizováno pro rychlou inferenci. Abychom toho dosáhli, vybudovali jsme proprietární infrastrukturu LLM inference nad technologií NVIDIA TensortRT-LLM, která běží na GPU A100 poskytovaných společností AWS. Více se dozvíte v části Přehled infrastruktury pplx-api. Výsledkem je, že pplx-api patří mezi nejrychlejší komerčně dostupná API pro Llama a Mistral.
Abychom provedli srovnání se stávajícími řešeními, porovnali jsme latenci pplx-api s jinými knihovnami pro LLM inferenci. V našich experimentech dosahuje pplx-api až 2.92x nižší celkové latence oproti Text Generation Inference (TGI) a až 4.35x nižší latence první odpovědi. Pro tento experiment jsme porovnávali TGI a inferenci Perplexity v režimu jednoho proudu i serverovém scénáři na 2 GPU A100 s modelem Llama-2-13B-chat rozděleným mezi obě GPU. V režimu jednoho proudu server zpracovává jeden požadavek za druhým. V serverovém scénáři klient odesílá požadavky podle Poissonova rozdělení s různou intenzitou požadavků, aby emuloval proměnlivou zátěž. Pokud jde o intenzitu požadavků, provedli jsme malé prozkoumání až do maxima 1 požadavku za sekundu, což je maximální propustnost udržená TGI. Použili jsme data z reálného provozu s různými délkami vstupních i výstupních tokenů, abychom simulovali chování v produkci. Požadavky mají v průměru ~700 vstupních tokenů a ~550 výstupních tokenů.
Při použití stejných vstupů a odesílání jednoho proudu požadavků jsme také změřili průměrné latence API služeb Replicate a Anyscale pro tentýž model, abychom získali výkonnostní základnu vůči dalším existujícím API.

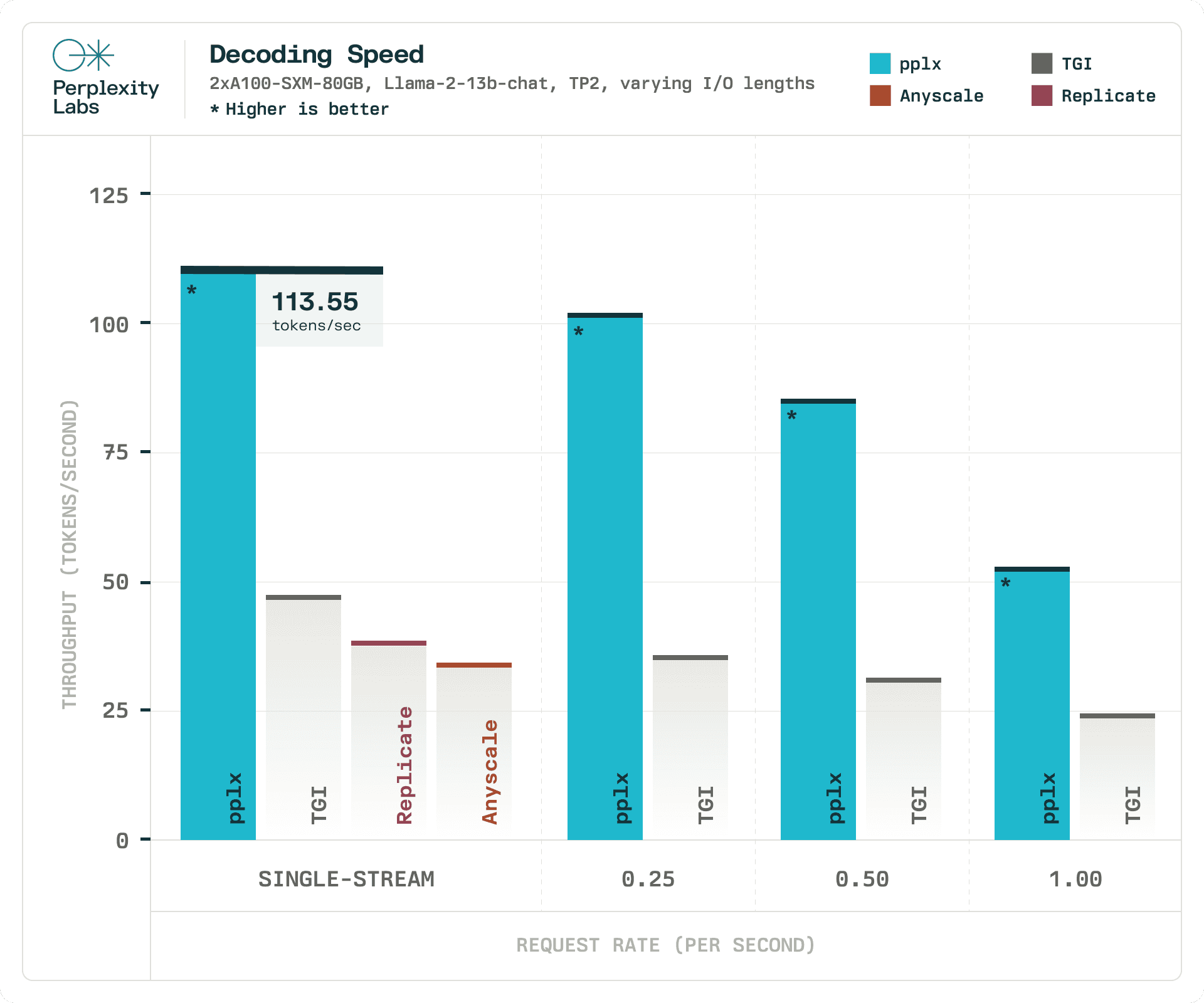
Při použití stejného experimentálního nastavení jsme porovnali maximální propustnost pplx-api vůči TGI, přičemž rychlost dekódování byla omezením latence. V našich experimentech pplx-api zpracovává tokeny 1.90x-6.75x rychleji než TGI a TGI zcela nedokáže splnit naše přísnější latanční omezení při 60 a 80 tokenech za sekundu. TGI vyhodnocujeme za stejných hardwarových a zátěžových podmínek, jaké jsme použili pro vyhodnocení pplx-api. Srovnání této metriky s Replicate a Anyscale není možné, protože nemůžeme kontrolovat jejich hardware a faktory zátěže.
Pro orientaci: průměrná rychlost lidského čtení je 5 tokenů za sekundu, což znamená, že pplx-api dokáže poskytovat výstup rychleji, než jej lze číst.
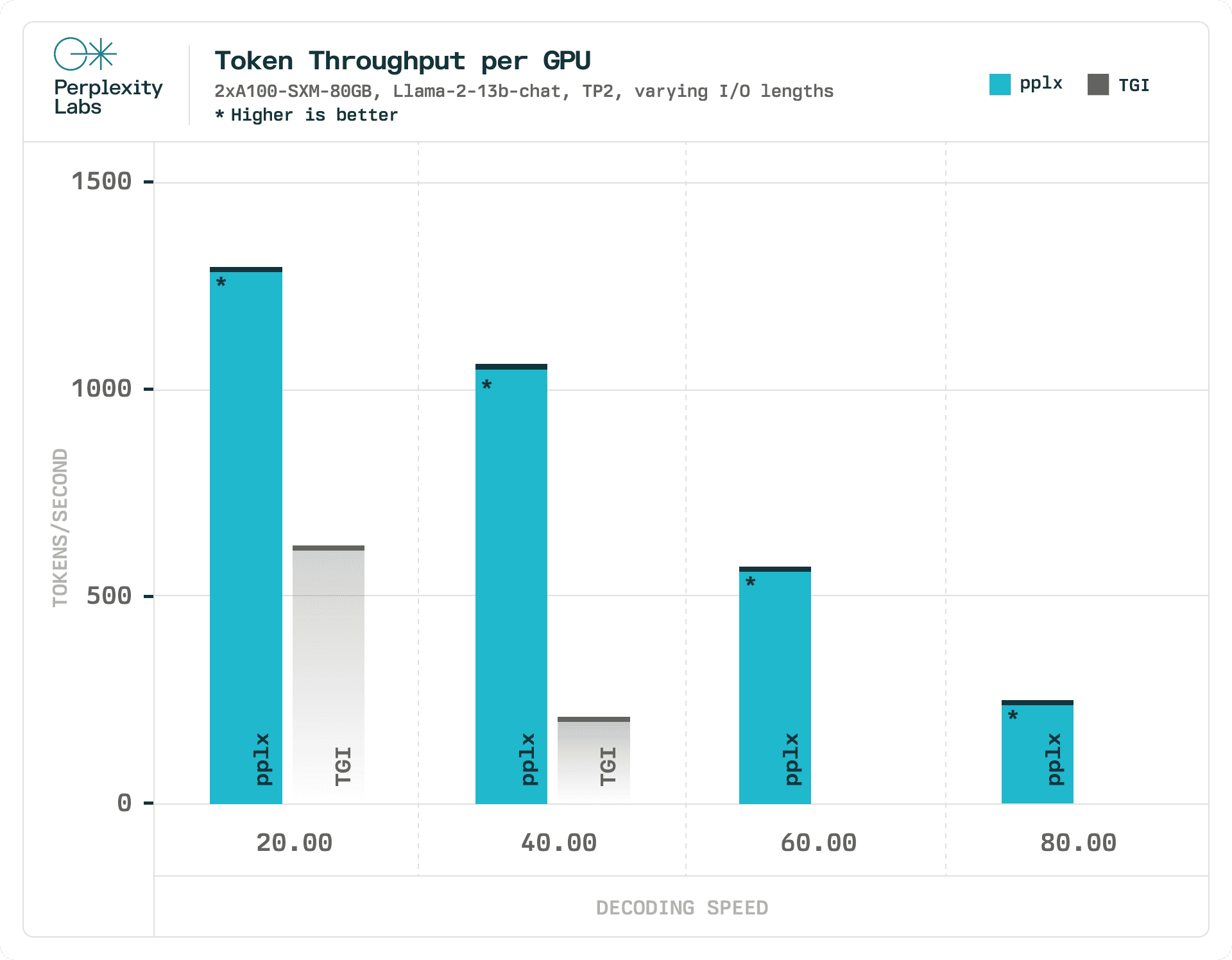
Přehled infrastruktury pplx-api
Dosažení těchto hodnot latence vyžaduje kombinaci nejmodernějšího softwaru a hardwaru.
Instance AWS p4d poháněné GPU NVIDIA A100 představují nejvýhodnější a nejspolehlivější možnost pro škálování GPU s nejlepšími taktovacími frekvencemi ve své třídě.
Aby software mohl tento hardware využít, provozujeme NVIDIA TensorRT-LLM, open-source knihovnu, která akceleruje a optimalizuje LLM inferenci. TensorRT-LLM staví na deep learning compileru TensorRT a zahrnuje nejnovější optimalizovaná jádra vytvořená pro špičkové implementace FlashAttention a maskované multi-head attention (MHA) pro kontextovou i generační fázi běhu modelů LLM.
Od tohoto bodu nám páteř AWS a jeho robustní integrace s Kubernetes umožňují elasticky škálovat na více než stovky GPU a minimalizovat prostoje i síťovou režii.
Případ použití: Naše API v produkci
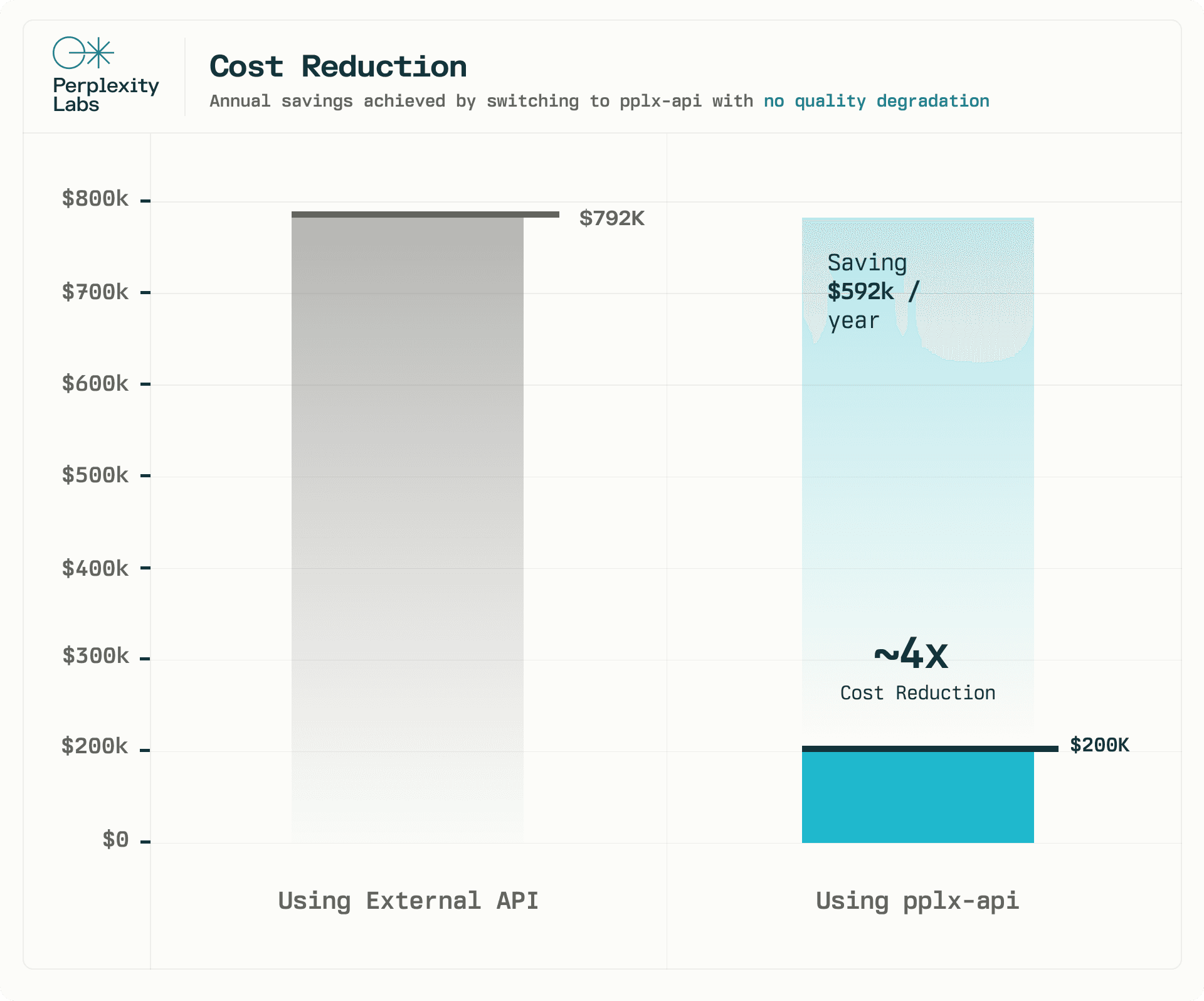
pplx-api v Perplexity: Snížení nákladů a spolehlivost
Naše API již pohání jednu z klíčových funkcí produktu Perplexity. Pouhé přepnutí jedné funkce z externího API na pplx-api vedlo k úspoře nákladů ve výši $0.62M/rok, přibližně 4x snížení nákladů. Prováděli jsme A/B testy a monitorovali infrastrukturní metriky, abychom zajistili, že nedojde ke zhoršení kvality. Během 2 týdnů jsme v A/B testu nepozorovali žádný statisticky významný rozdíl. pplx-api navíc dokázalo udržet denní zátěž přesahující jeden milion požadavků, celkem téměř jednu miliardu zpracovaných tokenů denně.
Výsledky tohoto počátečního zkoumání jsou velmi povzbudivé a očekáváme, že pplx-api bude postupem času pohánět více funkcí našeho produktu.
pplx-api v Perplexity Labs: Ekosystém open-source inference
Také používáme pplx-api k provozu Perplexity Labs, našeho modelového playgroundu nabízejícího různé open-source modely.
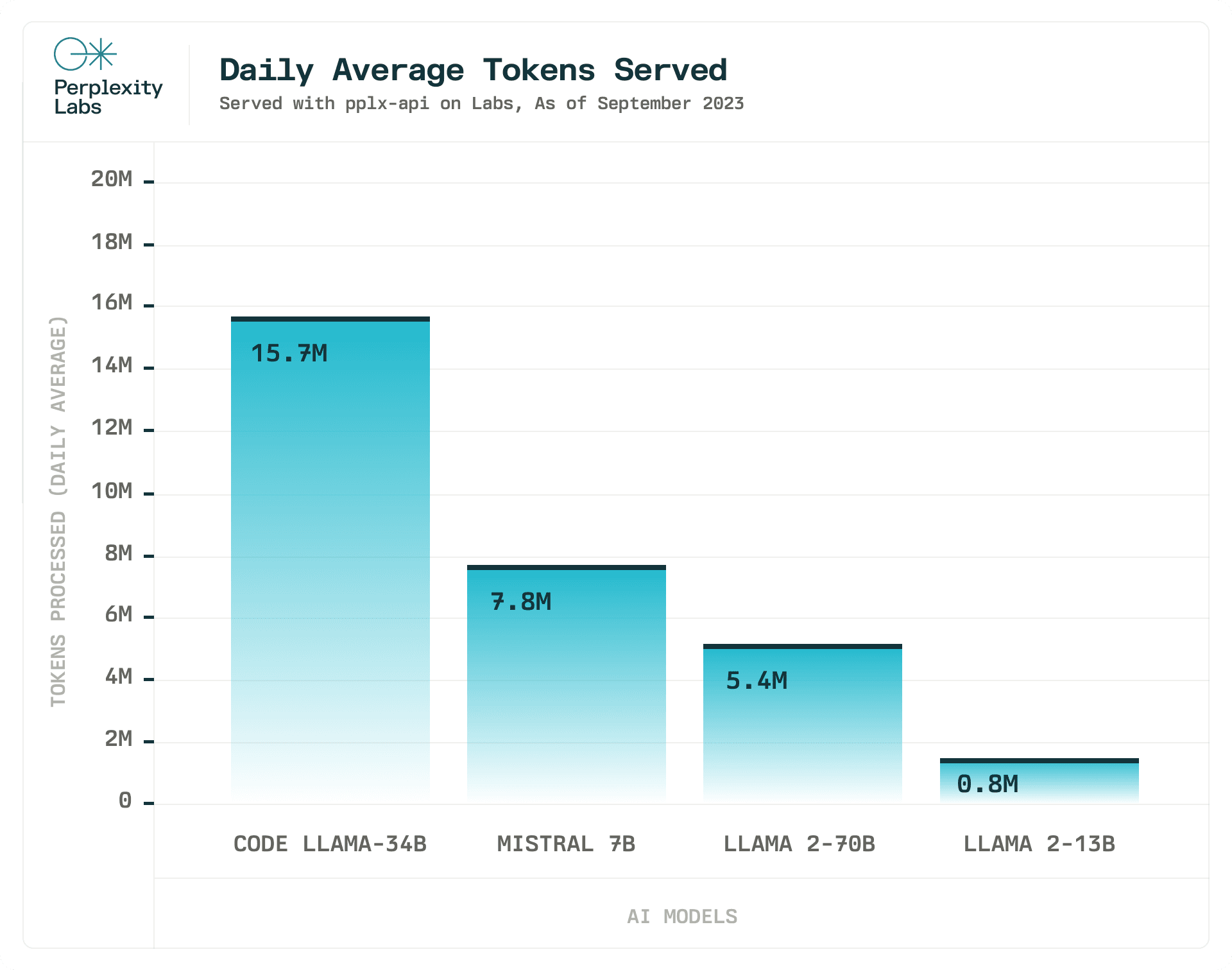
Náš tým se zavázal poskytovat přístup k nejnovějším špičkovým open-source LLM. Modely Mistral 7B, Code Llama 34b a všechny modely Llama 2 jsme integrovali během několika hodin po jejich vydání a plánujeme v tom pokračovat, jakmile budou k dispozici schopnější a open-source LLM.
Začněte s AI API od Perplexity
K REST API pplx-api můžete přistupovat pomocí požadavků HTTPS. Autentizace do pplx-api zahrnuje následující kroky:
Vygenerujte API klíč prostřednictvím Perplexity Account Settings Page. API klíč je dlouhodobý přístupový token, který lze používat, dokud není ručně obnoven nebo smazán.
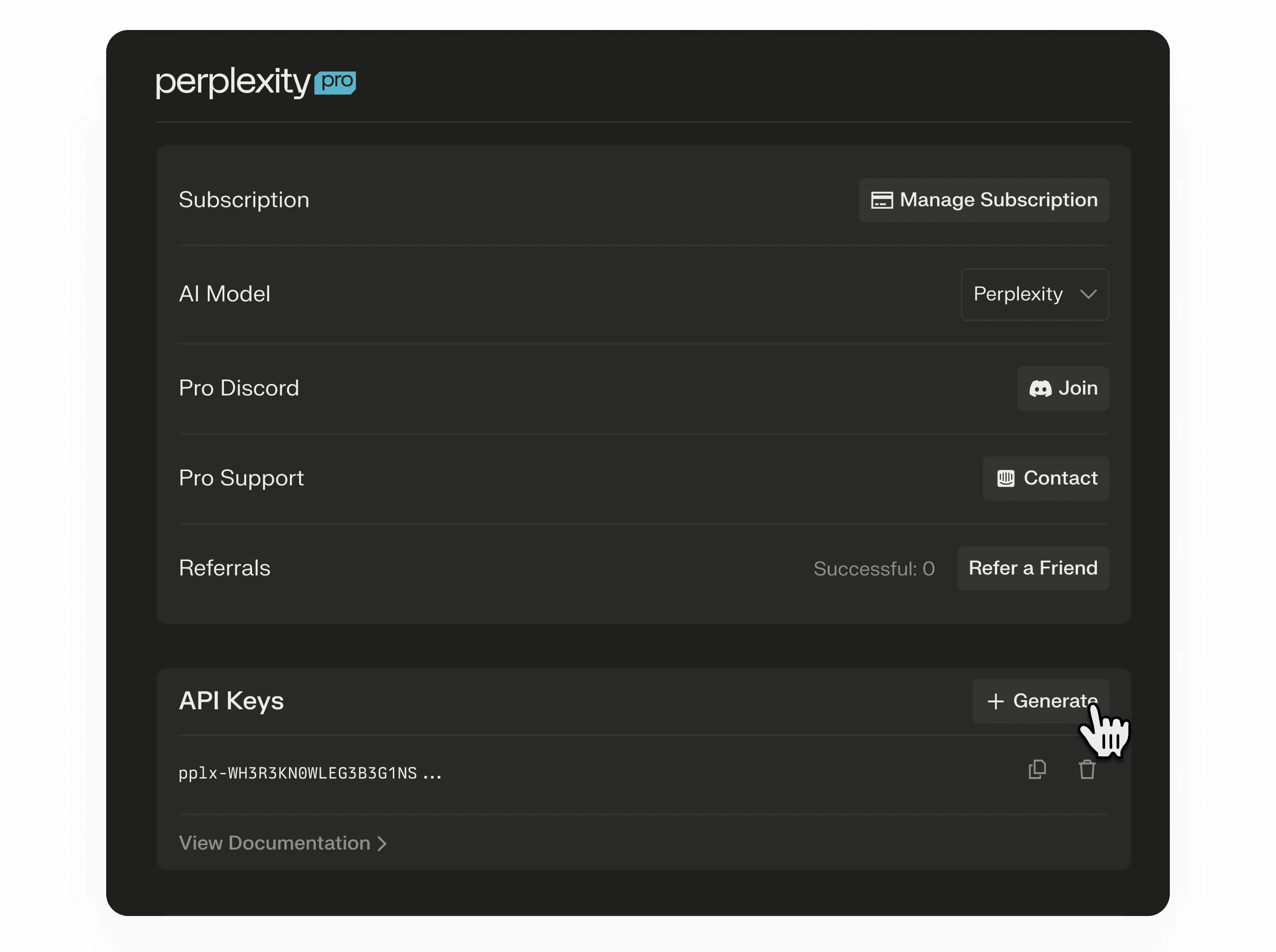
Odesílejte API klíč jako bearer token v hlavičce
Authorizations každým požadavkem pplx-api.
V následujícím příkladu je PERPLEXITY_API_KEY proměnná prostředí navázaná na klíč vygenerovaný podle výše uvedených pokynů. Pro odeslání požadavku na dokončení chatu se používá CURL.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Což vrátí následující odpověď s hlavičkou content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Zde je příklad volání v Pythonu:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
V současnosti podporujeme Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B a API je pro snadnou integraci se stávajícími aplikacemi plně kompatibilní s klientem OpenAI.
Další informace naleznete v naší dokumentaci API a v Příručce rychlého startu.
Co bude dál
V blízké budoucnosti bude pplx-api podporovat:
Vlastní LLM od Perplexity a další open-source LLM.
Vlastní embeddingy od Perplexity a open-source embeddingy.
Vyhrazenou cenovou strukturu API s obecnou dostupností po ukončení veřejné beta verze.
Perplexity RAG-LLM API s groundingem pro fakta a citace.
Ozvěte se na api@perplexity.ai, pokud Vás zajímá kterýkoli z těchto případů použití.
Toto je také začátek série příspěvků na našem Perplexity Blog. V našem příštím příspěvku se podělíme o podrobný rozbor srovnání výkonu A100 vs H100 pro LLM inferenci. Zůstaňte naladěni!
Nabíráme! Pokud chcete s námi pracovat na produktu nasazeném v masivním měřítku a budovat promyšleně navrženou, pečlivě optimalizovanou infrastrukturu pro generativní modely a velké jazykové modely, prosím přidejte se k nám.
Sledujte nás na Twitter, LinkedIn a připojte se k našemu Discord pro další diskusi.
Autoři
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Ochrana osobních údajů
Volbou pplx-api můžete využít plný potenciál LLM a zároveň chránit soukromí a důvěru svých uživatelů a zákazníků. Chápeme důležitost ochrany Vašich osobních údajů a jsme odhodláni zachovávat bezpečnost a soukromí našich uživatelů. Data API jsou automaticky mazána po 30 dnech a nikdy netrénujeme na žádných datech přenášených prostřednictvím pplx-api. Uživatelé mají v nastavení účtu možnost odmítnout uchovávání dat. Naše zásady ochrany soukromí API naleznete zde.
Upozorňujeme: Níže uvedené položky byly pro aktuální modely vyřazeny. Zjistěte více o našich API
S radostí oznamujeme pplx-api, navržené jako jeden z nejrychlejších způsobů přístupu k modelům Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b. pplx-api vývojářům usnadňuje integraci špičkových open-source LLM do jejich projektů.
Naše pplx-api nabízí:
Snadné použití: vývojáři mohou používat nejmodernější open-source modely ihned a začít během několika minut s důvěrně známým REST API.
Bleskově rychlou inferenci: náš promyšleně navržený inferenční systém je efektivní a dosahuje až 2.9x nižší latence než Replicate a 3.1x nižší latence než Anyscale.
Ověřenou infrastrukturu: pplx-api je prokazatelně spolehlivé a obsluhuje provoz na produkční úrovni jak v našem Perplexity answer engine, tak v našem Labs playground.
Komplexní řešení pro open-source LLM: náš tým se věnuje přidávání nových open-source modelů ihned, jakmile jsou k dispozici. Například jsme modely Llama a Mistral přidali během několika hodin od spuštění bez předběžného přístupu.
pplx-api je ve veřejné beta verzi a pro uživatele s předplatným Perplexity Pro je zdarma.
Používejte pplx-api pro neformální víkendový hackathon nebo jako komerční řešení pro vytváření nových a inovativních produktů. Prostřednictvím tohoto vydání se chceme dozvědět, jak mohou lidé s naším API vytvářet skvělé a inovativní produkty. Pokud máte obchodní případ použití pro pplx-api, kontaktujte prosím api@perplexity.ai . Budeme rádi, když se nám ozvete!
Výhody pplx-api
Snadné použití
Nasazení LLM a inference vyžadují značné infrastrukturní úsilí, aby bylo poskytování modelů výkonné a nákladově efektivní. Vývojáři mohou naše API používat ihned, bez hlubokých znalostí C++/CUDA nebo přístupu ke GPU, a přesto využívat špičkový výkon. Naše LLM inference také abstrahuje složitost a nutnost správy vlastního hardwaru, čímž dále zvyšuje snadnost použití.
Bleskově rychlá inference
LLM API Perplexity je pečlivě navrženo a optimalizováno pro rychlou inferenci. Abychom toho dosáhli, vybudovali jsme proprietární infrastrukturu LLM inference nad technologií NVIDIA TensortRT-LLM, která běží na GPU A100 poskytovaných společností AWS. Více se dozvíte v části Přehled infrastruktury pplx-api. Výsledkem je, že pplx-api patří mezi nejrychlejší komerčně dostupná API pro Llama a Mistral.
Abychom provedli srovnání se stávajícími řešeními, porovnali jsme latenci pplx-api s jinými knihovnami pro LLM inferenci. V našich experimentech dosahuje pplx-api až 2.92x nižší celkové latence oproti Text Generation Inference (TGI) a až 4.35x nižší latence první odpovědi. Pro tento experiment jsme porovnávali TGI a inferenci Perplexity v režimu jednoho proudu i serverovém scénáři na 2 GPU A100 s modelem Llama-2-13B-chat rozděleným mezi obě GPU. V režimu jednoho proudu server zpracovává jeden požadavek za druhým. V serverovém scénáři klient odesílá požadavky podle Poissonova rozdělení s různou intenzitou požadavků, aby emuloval proměnlivou zátěž. Pokud jde o intenzitu požadavků, provedli jsme malé prozkoumání až do maxima 1 požadavku za sekundu, což je maximální propustnost udržená TGI. Použili jsme data z reálného provozu s různými délkami vstupních i výstupních tokenů, abychom simulovali chování v produkci. Požadavky mají v průměru ~700 vstupních tokenů a ~550 výstupních tokenů.
Při použití stejných vstupů a odesílání jednoho proudu požadavků jsme také změřili průměrné latence API služeb Replicate a Anyscale pro tentýž model, abychom získali výkonnostní základnu vůči dalším existujícím API.
Při použití stejného experimentálního nastavení jsme porovnali maximální propustnost pplx-api vůči TGI, přičemž rychlost dekódování byla omezením latence. V našich experimentech pplx-api zpracovává tokeny 1.90x-6.75x rychleji než TGI a TGI zcela nedokáže splnit naše přísnější latanční omezení při 60 a 80 tokenech za sekundu. TGI vyhodnocujeme za stejných hardwarových a zátěžových podmínek, jaké jsme použili pro vyhodnocení pplx-api. Srovnání této metriky s Replicate a Anyscale není možné, protože nemůžeme kontrolovat jejich hardware a faktory zátěže.
Pro orientaci: průměrná rychlost lidského čtení je 5 tokenů za sekundu, což znamená, že pplx-api dokáže poskytovat výstup rychleji, než jej lze číst.
Přehled infrastruktury pplx-api
Dosažení těchto hodnot latence vyžaduje kombinaci nejmodernějšího softwaru a hardwaru.
Instance AWS p4d poháněné GPU NVIDIA A100 představují nejvýhodnější a nejspolehlivější možnost pro škálování GPU s nejlepšími taktovacími frekvencemi ve své třídě.
Aby software mohl tento hardware využít, provozujeme NVIDIA TensorRT-LLM, open-source knihovnu, která akceleruje a optimalizuje LLM inferenci. TensorRT-LLM staví na deep learning compileru TensorRT a zahrnuje nejnovější optimalizovaná jádra vytvořená pro špičkové implementace FlashAttention a maskované multi-head attention (MHA) pro kontextovou i generační fázi běhu modelů LLM.
Od tohoto bodu nám páteř AWS a jeho robustní integrace s Kubernetes umožňují elasticky škálovat na více než stovky GPU a minimalizovat prostoje i síťovou režii.
Případ použití: Naše API v produkci
pplx-api v Perplexity: Snížení nákladů a spolehlivost
Naše API již pohání jednu z klíčových funkcí produktu Perplexity. Pouhé přepnutí jedné funkce z externího API na pplx-api vedlo k úspoře nákladů ve výši $0.62M/rok, přibližně 4x snížení nákladů. Prováděli jsme A/B testy a monitorovali infrastrukturní metriky, abychom zajistili, že nedojde ke zhoršení kvality. Během 2 týdnů jsme v A/B testu nepozorovali žádný statisticky významný rozdíl. pplx-api navíc dokázalo udržet denní zátěž přesahující jeden milion požadavků, celkem téměř jednu miliardu zpracovaných tokenů denně.
Výsledky tohoto počátečního zkoumání jsou velmi povzbudivé a očekáváme, že pplx-api bude postupem času pohánět více funkcí našeho produktu.
pplx-api v Perplexity Labs: Ekosystém open-source inference
Také používáme pplx-api k provozu Perplexity Labs, našeho modelového playgroundu nabízejícího různé open-source modely.
Náš tým se zavázal poskytovat přístup k nejnovějším špičkovým open-source LLM. Modely Mistral 7B, Code Llama 34b a všechny modely Llama 2 jsme integrovali během několika hodin po jejich vydání a plánujeme v tom pokračovat, jakmile budou k dispozici schopnější a open-source LLM.
Začněte s AI API od Perplexity
K REST API pplx-api můžete přistupovat pomocí požadavků HTTPS. Autentizace do pplx-api zahrnuje následující kroky:
Vygenerujte API klíč prostřednictvím Perplexity Account Settings Page. API klíč je dlouhodobý přístupový token, který lze používat, dokud není ručně obnoven nebo smazán.
Odesílejte API klíč jako bearer token v hlavičce
Authorizations každým požadavkem pplx-api.
V následujícím příkladu je PERPLEXITY_API_KEY proměnná prostředí navázaná na klíč vygenerovaný podle výše uvedených pokynů. Pro odeslání požadavku na dokončení chatu se používá CURL.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Což vrátí následující odpověď s hlavičkou content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Zde je příklad volání v Pythonu:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
V současnosti podporujeme Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B a API je pro snadnou integraci se stávajícími aplikacemi plně kompatibilní s klientem OpenAI.
Další informace naleznete v naší dokumentaci API a v Příručce rychlého startu.
Co bude dál
V blízké budoucnosti bude pplx-api podporovat:
Vlastní LLM od Perplexity a další open-source LLM.
Vlastní embeddingy od Perplexity a open-source embeddingy.
Vyhrazenou cenovou strukturu API s obecnou dostupností po ukončení veřejné beta verze.
Perplexity RAG-LLM API s groundingem pro fakta a citace.
Ozvěte se na api@perplexity.ai, pokud Vás zajímá kterýkoli z těchto případů použití.
Toto je také začátek série příspěvků na našem Perplexity Blog. V našem příštím příspěvku se podělíme o podrobný rozbor srovnání výkonu A100 vs H100 pro LLM inferenci. Zůstaňte naladěni!
Nabíráme! Pokud chcete s námi pracovat na produktu nasazeném v masivním měřítku a budovat promyšleně navrženou, pečlivě optimalizovanou infrastrukturu pro generativní modely a velké jazykové modely, prosím přidejte se k nám.
Sledujte nás na Twitter, LinkedIn a připojte se k našemu Discord pro další diskusi.
Autoři
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Ochrana osobních údajů
Volbou pplx-api můžete využít plný potenciál LLM a zároveň chránit soukromí a důvěru svých uživatelů a zákazníků. Chápeme důležitost ochrany Vašich osobních údajů a jsme odhodláni zachovávat bezpečnost a soukromí našich uživatelů. Data API jsou automaticky mazána po 30 dnech a nikdy netrénujeme na žádných datech přenášených prostřednictvím pplx-api. Uživatelé mají v nastavení účtu možnost odmítnout uchovávání dat. Naše zásady ochrany soukromí API naleznete zde.
Upozorňujeme: Níže uvedené položky byly pro aktuální modely vyřazeny. Zjistěte více o našich API
S radostí oznamujeme pplx-api, navržené jako jeden z nejrychlejších způsobů přístupu k modelům Mistral 7B, Llama2 13B, Code Llama 34B, Llama2 70B, replit-code-v1.5-3b. pplx-api vývojářům usnadňuje integraci špičkových open-source LLM do jejich projektů.
Naše pplx-api nabízí:
Snadné použití: vývojáři mohou používat nejmodernější open-source modely ihned a začít během několika minut s důvěrně známým REST API.
Bleskově rychlou inferenci: náš promyšleně navržený inferenční systém je efektivní a dosahuje až 2.9x nižší latence než Replicate a 3.1x nižší latence než Anyscale.
Ověřenou infrastrukturu: pplx-api je prokazatelně spolehlivé a obsluhuje provoz na produkční úrovni jak v našem Perplexity answer engine, tak v našem Labs playground.
Komplexní řešení pro open-source LLM: náš tým se věnuje přidávání nových open-source modelů ihned, jakmile jsou k dispozici. Například jsme modely Llama a Mistral přidali během několika hodin od spuštění bez předběžného přístupu.
pplx-api je ve veřejné beta verzi a pro uživatele s předplatným Perplexity Pro je zdarma.
Používejte pplx-api pro neformální víkendový hackathon nebo jako komerční řešení pro vytváření nových a inovativních produktů. Prostřednictvím tohoto vydání se chceme dozvědět, jak mohou lidé s naším API vytvářet skvělé a inovativní produkty. Pokud máte obchodní případ použití pro pplx-api, kontaktujte prosím api@perplexity.ai . Budeme rádi, když se nám ozvete!
Výhody pplx-api
Snadné použití
Nasazení LLM a inference vyžadují značné infrastrukturní úsilí, aby bylo poskytování modelů výkonné a nákladově efektivní. Vývojáři mohou naše API používat ihned, bez hlubokých znalostí C++/CUDA nebo přístupu ke GPU, a přesto využívat špičkový výkon. Naše LLM inference také abstrahuje složitost a nutnost správy vlastního hardwaru, čímž dále zvyšuje snadnost použití.
Bleskově rychlá inference
LLM API Perplexity je pečlivě navrženo a optimalizováno pro rychlou inferenci. Abychom toho dosáhli, vybudovali jsme proprietární infrastrukturu LLM inference nad technologií NVIDIA TensortRT-LLM, která běží na GPU A100 poskytovaných společností AWS. Více se dozvíte v části Přehled infrastruktury pplx-api. Výsledkem je, že pplx-api patří mezi nejrychlejší komerčně dostupná API pro Llama a Mistral.
Abychom provedli srovnání se stávajícími řešeními, porovnali jsme latenci pplx-api s jinými knihovnami pro LLM inferenci. V našich experimentech dosahuje pplx-api až 2.92x nižší celkové latence oproti Text Generation Inference (TGI) a až 4.35x nižší latence první odpovědi. Pro tento experiment jsme porovnávali TGI a inferenci Perplexity v režimu jednoho proudu i serverovém scénáři na 2 GPU A100 s modelem Llama-2-13B-chat rozděleným mezi obě GPU. V režimu jednoho proudu server zpracovává jeden požadavek za druhým. V serverovém scénáři klient odesílá požadavky podle Poissonova rozdělení s různou intenzitou požadavků, aby emuloval proměnlivou zátěž. Pokud jde o intenzitu požadavků, provedli jsme malé prozkoumání až do maxima 1 požadavku za sekundu, což je maximální propustnost udržená TGI. Použili jsme data z reálného provozu s různými délkami vstupních i výstupních tokenů, abychom simulovali chování v produkci. Požadavky mají v průměru ~700 vstupních tokenů a ~550 výstupních tokenů.
Při použití stejných vstupů a odesílání jednoho proudu požadavků jsme také změřili průměrné latence API služeb Replicate a Anyscale pro tentýž model, abychom získali výkonnostní základnu vůči dalším existujícím API.
Při použití stejného experimentálního nastavení jsme porovnali maximální propustnost pplx-api vůči TGI, přičemž rychlost dekódování byla omezením latence. V našich experimentech pplx-api zpracovává tokeny 1.90x-6.75x rychleji než TGI a TGI zcela nedokáže splnit naše přísnější latanční omezení při 60 a 80 tokenech za sekundu. TGI vyhodnocujeme za stejných hardwarových a zátěžových podmínek, jaké jsme použili pro vyhodnocení pplx-api. Srovnání této metriky s Replicate a Anyscale není možné, protože nemůžeme kontrolovat jejich hardware a faktory zátěže.
Pro orientaci: průměrná rychlost lidského čtení je 5 tokenů za sekundu, což znamená, že pplx-api dokáže poskytovat výstup rychleji, než jej lze číst.
Přehled infrastruktury pplx-api
Dosažení těchto hodnot latence vyžaduje kombinaci nejmodernějšího softwaru a hardwaru.
Instance AWS p4d poháněné GPU NVIDIA A100 představují nejvýhodnější a nejspolehlivější možnost pro škálování GPU s nejlepšími taktovacími frekvencemi ve své třídě.
Aby software mohl tento hardware využít, provozujeme NVIDIA TensorRT-LLM, open-source knihovnu, která akceleruje a optimalizuje LLM inferenci. TensorRT-LLM staví na deep learning compileru TensorRT a zahrnuje nejnovější optimalizovaná jádra vytvořená pro špičkové implementace FlashAttention a maskované multi-head attention (MHA) pro kontextovou i generační fázi běhu modelů LLM.
Od tohoto bodu nám páteř AWS a jeho robustní integrace s Kubernetes umožňují elasticky škálovat na více než stovky GPU a minimalizovat prostoje i síťovou režii.
Případ použití: Naše API v produkci
pplx-api v Perplexity: Snížení nákladů a spolehlivost
Naše API již pohání jednu z klíčových funkcí produktu Perplexity. Pouhé přepnutí jedné funkce z externího API na pplx-api vedlo k úspoře nákladů ve výši $0.62M/rok, přibližně 4x snížení nákladů. Prováděli jsme A/B testy a monitorovali infrastrukturní metriky, abychom zajistili, že nedojde ke zhoršení kvality. Během 2 týdnů jsme v A/B testu nepozorovali žádný statisticky významný rozdíl. pplx-api navíc dokázalo udržet denní zátěž přesahující jeden milion požadavků, celkem téměř jednu miliardu zpracovaných tokenů denně.
Výsledky tohoto počátečního zkoumání jsou velmi povzbudivé a očekáváme, že pplx-api bude postupem času pohánět více funkcí našeho produktu.
pplx-api v Perplexity Labs: Ekosystém open-source inference
Také používáme pplx-api k provozu Perplexity Labs, našeho modelového playgroundu nabízejícího různé open-source modely.
Náš tým se zavázal poskytovat přístup k nejnovějším špičkovým open-source LLM. Modely Mistral 7B, Code Llama 34b a všechny modely Llama 2 jsme integrovali během několika hodin po jejich vydání a plánujeme v tom pokračovat, jakmile budou k dispozici schopnější a open-source LLM.
Začněte s AI API od Perplexity
K REST API pplx-api můžete přistupovat pomocí požadavků HTTPS. Autentizace do pplx-api zahrnuje následující kroky:
Vygenerujte API klíč prostřednictvím Perplexity Account Settings Page. API klíč je dlouhodobý přístupový token, který lze používat, dokud není ručně obnoven nebo smazán.
Odesílejte API klíč jako bearer token v hlavičce
Authorizations každým požadavkem pplx-api.
V následujícím příkladu je PERPLEXITY_API_KEY proměnná prostředí navázaná na klíč vygenerovaný podle výše uvedených pokynů. Pro odeslání požadavku na dokončení chatu se používá CURL.
curl -X POST \ --url https://api.perplexity.ai/chat/completions \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \ --data '{ "model": "mistral-7b-instruct", "stream": false, "max_tokens": 1024, "frequency_penalty": 1, "temperature": 0.0, "messages": [ { "role": "system", "content": "Be precise and concise in your responses." }, { "role": "user", "content": "How many stars are there in our galaxy?" } ] }'
Což vrátí následující odpověď s hlavičkou content-type: application/json
{ "id": "3fbf9a47-ac23-446d-8c6b-d911e190a898", "model": "mistral-7b-instruct", "object": "chat.completion", "created": 1765322, "choices": [ { "index": 0, "finish_reason": "stop", "message": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." }, "delta": { "role": "assistant", "content": " The Milky Way galaxy contains an estimated 200-400 billion stars.." } } ], "usage": { "prompt_tokens": 40, "completion_tokens": 22, "total_tokens": 62 } }
Zde je příklad volání v Pythonu:
from openai import OpenAI YOUR_API_KEY = "INSERT API KEY HERE" messages = [ { "role": "system", "content": ( "You are an artificial intelligence assistant and you need to " "engage in a helpful, detailed, polite conversation with a user." ), }, { "role": "user", "content": ( "Count to 100, with a comma between each number and no newlines. " "E.g., 1, 2, 3, ..." ), }, ] client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai") # demo chat completion without streaming response = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, ) print(response) # demo chat completion with streaming response_stream = client.chat.completions.create( model="mistral-7b-instruct", messages=messages, stream=True, ) for response in response_stream: print(response)
V současnosti podporujeme Mistral 7B, Llama 13B, Code Llama 34B, Llama 70B a API je pro snadnou integraci se stávajícími aplikacemi plně kompatibilní s klientem OpenAI.
Další informace naleznete v naší dokumentaci API a v Příručce rychlého startu.
Co bude dál
V blízké budoucnosti bude pplx-api podporovat:
Vlastní LLM od Perplexity a další open-source LLM.
Vlastní embeddingy od Perplexity a open-source embeddingy.
Vyhrazenou cenovou strukturu API s obecnou dostupností po ukončení veřejné beta verze.
Perplexity RAG-LLM API s groundingem pro fakta a citace.
Ozvěte se na api@perplexity.ai, pokud Vás zajímá kterýkoli z těchto případů použití.
Toto je také začátek série příspěvků na našem Perplexity Blog. V našem příštím příspěvku se podělíme o podrobný rozbor srovnání výkonu A100 vs H100 pro LLM inferenci. Zůstaňte naladěni!
Nabíráme! Pokud chcete s námi pracovat na produktu nasazeném v masivním měřítku a budovat promyšleně navrženou, pečlivě optimalizovanou infrastrukturu pro generativní modely a velké jazykové modely, prosím přidejte se k nám.
Sledujte nás na Twitter, LinkedIn a připojte se k našemu Discord pro další diskusi.
Autoři
Lauren Yang, Kevin Hu, Aarash Heydari, William Zhang, Dmitry Pervukhin, Grigorii Alekseev, Alexandr Yarats
Ochrana osobních údajů
Volbou pplx-api můžete využít plný potenciál LLM a zároveň chránit soukromí a důvěru svých uživatelů a zákazníků. Chápeme důležitost ochrany Vašich osobních údajů a jsme odhodláni zachovávat bezpečnost a soukromí našich uživatelů. Data API jsou automaticky mazána po 30 dnech a nikdy netrénujeme na žádných datech přenášených prostřednictvím pplx-api. Uživatelé mají v nastavení účtu možnost odmítnout uchovávání dat. Naše zásady ochrany soukromí API naleznete zde.
Sdílejte tento článek