

Napsáno
Tým Perplexity
Publikováno
Search API: Lepší extrakce, dynamické benchmarky
V září jsme publikovali technický přehled architektury Perplexity Search API a vydali search_evals, náš open-source evaluační rámec pro benchmarkování vyhledávacích API v agentních pracovních postupech. Od té doby směřovala nejvýznamnější investice do kvality snippetů, optimalizované ve dvou dimenzích: relevance a velikost. Vrácení správného obsahu ve správném rozsahu přímo určuje přesnost následných odpovědí a efektivitu tokenů. Práce potřebná k dosažení tohoto cíle zahrnovala vybudování nových systémů pro extrakci, označování na úrovni spanů a vyhodnocování, zejména pipeline pro označování spanů, která určuje, které segmenty zdrojového dokumentu odpovídají danému dotazu.
Vyhodnocování snippetů na úrovni spanů
Abychom snippety systematicky zlepšovali, navrhli jsme nový evaluační systém. Pro daný dotaz a dokument systém identifikuje a označuje spany v dokumentu podle jejich vztahu k dotazu: „klíčové“ spany, které musejí být zahrnuty do snippetu, různé třídy „irelevantních“ spanů, které by měly být vyloučeny, duplicity a další kategorie. Toto označování na úrovni spanů nám umožňuje vyhodnocovat kvalitu snippetů s mírou přesnosti, která dříve nebyla možná, a měřit jak to, co bylo správně zahrnuto, tak to, co bylo správně vynecháno.
V praxi nám tato zlepšení umožňují generovat menší snippety, které jsou pro dotaz relevantnější. Naše samovylepšující pipeline pro porozumění obsahu nyní zvládá širší škálu formátů strukturovaných dat, včetně tabulek, vnořených seznamů a dynamicky vykreslovaného obsahu, který dřívější sady pravidel nedokázaly spolehlivě parsovat.
Tato zlepšení vzešla z našich vlastních produkčních systémů. Jak náš interní výzkum posouval relevanci a velikost snippetů kupředu, interní evaluace odhalily, že menší rozpočty na obsah po sérii zlepšení kvality ve skutečnosti přinášely přesnější výsledky. Upravili jsme některé naše výchozí konfigurace tak, aby odrážely tato zjištění, čímž jsme snížili velikost payloadu odpovědi a latenci a zároveň poskytli užitečnější obsah na jeden výsledek. Pro vývojáře se menší a relevantnější snippety přímo promítají do nižších nákladů na tokeny a lepší správy kontextu pro následné LLM.
SEAL: benchmarkování časově citlivého retrievalu
Benchmark SEAL testuje, zda retrievalový systém dokáže odpovídat na otázky, jejichž správná odpověď se v čase mění. Spolehlivé zodpovídání vyžaduje čerstvost indexu v reálném čase, chytřejší extrakci snippetů z různých průběžně aktualizovaných datových zdrojů a parsování, které dokáže identifikovat aktuální hodnotu namísto historické.
Když jsme spustili search_evals na vydání SEAL z 22. února s použitím Claude Sonnet 4.5, skóre Perplexity vzrostlo, zatímco skóre ostatních poskytovatelů v benchmarku SEAL-Hard kleslo:
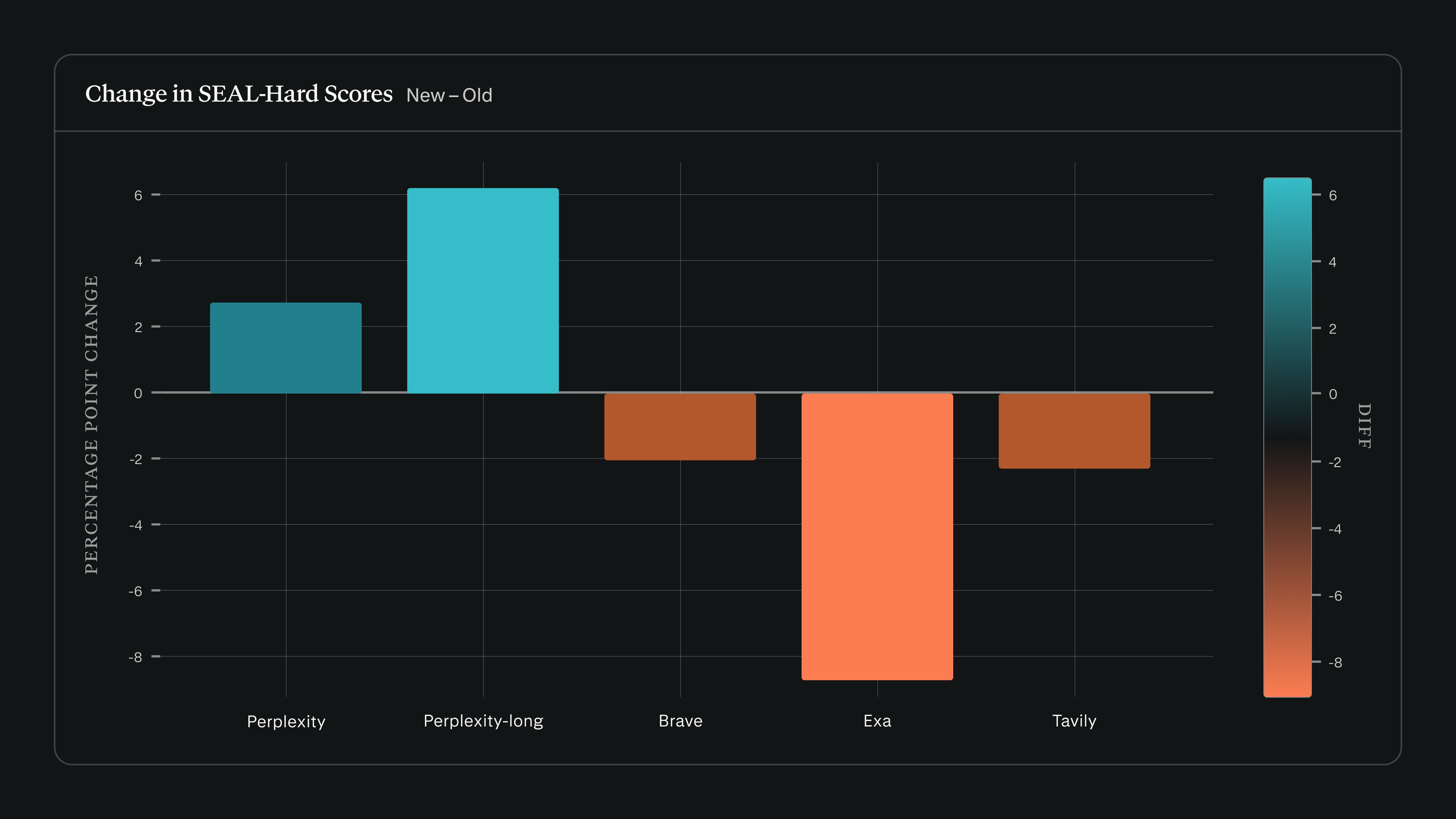
Náš rámec search_evals jsme rozšířili tak, aby vedle benchmarků uvedených v našem zářijovém příspěvku zahrnoval také SEAL. Aktualizované výsledky a metodika jsou k dispozici v aktualizovaném repozitáři na GitHubu.
Podpora více dotazů
API nyní podporuje až 5 dotazů v rámci jednoho požadavku. Výsledky se vracejí seskupené podle dotazu ve stejném pořadí, v jakém byly odeslány. To snižuje počet round tripů u aplikací, které potřebují paralelně zadávat související vyhledávání, například agentů, kteří rozkládají složitou otázku na více dílčích úloh retrievalu.
Rozšířené filtrování
Kromě filtrování podle domény (allowlist a denylist, až 20 domén) a filtrování podle aktuálnosti nyní API podporuje filtrování podle jazyka pomocí kódu ISO 639-1 a regionální vyhledávání pomocí kódu země ISO. Tyto možnosti lze kombinovat pro přesné vymezení výsledků, například omezení na anglickojazyčné výsledky z německých domén.
SDK a dostupnost
Python SDK (pip install perplexityai) nyní poskytuje nativní podporu pro Search API vedle Agent API a Sonar API.
Úplná dokumentace je na docs.perplexity.ai
Search API: Lepší extrakce, dynamické benchmarky
V září jsme publikovali technický přehled architektury Perplexity Search API a vydali search_evals, náš open-source evaluační rámec pro benchmarkování vyhledávacích API v agentních pracovních postupech. Od té doby směřovala nejvýznamnější investice do kvality snippetů, optimalizované ve dvou dimenzích: relevance a velikost. Vrácení správného obsahu ve správném rozsahu přímo určuje přesnost následných odpovědí a efektivitu tokenů. Práce potřebná k dosažení tohoto cíle zahrnovala vybudování nových systémů pro extrakci, označování na úrovni spanů a vyhodnocování, zejména pipeline pro označování spanů, která určuje, které segmenty zdrojového dokumentu odpovídají danému dotazu.
Vyhodnocování snippetů na úrovni spanů
Abychom snippety systematicky zlepšovali, navrhli jsme nový evaluační systém. Pro daný dotaz a dokument systém identifikuje a označuje spany v dokumentu podle jejich vztahu k dotazu: „klíčové“ spany, které musejí být zahrnuty do snippetu, různé třídy „irelevantních“ spanů, které by měly být vyloučeny, duplicity a další kategorie. Toto označování na úrovni spanů nám umožňuje vyhodnocovat kvalitu snippetů s mírou přesnosti, která dříve nebyla možná, a měřit jak to, co bylo správně zahrnuto, tak to, co bylo správně vynecháno.
V praxi nám tato zlepšení umožňují generovat menší snippety, které jsou pro dotaz relevantnější. Naše samovylepšující pipeline pro porozumění obsahu nyní zvládá širší škálu formátů strukturovaných dat, včetně tabulek, vnořených seznamů a dynamicky vykreslovaného obsahu, který dřívější sady pravidel nedokázaly spolehlivě parsovat.
Tato zlepšení vzešla z našich vlastních produkčních systémů. Jak náš interní výzkum posouval relevanci a velikost snippetů kupředu, interní evaluace odhalily, že menší rozpočty na obsah po sérii zlepšení kvality ve skutečnosti přinášely přesnější výsledky. Upravili jsme některé naše výchozí konfigurace tak, aby odrážely tato zjištění, čímž jsme snížili velikost payloadu odpovědi a latenci a zároveň poskytli užitečnější obsah na jeden výsledek. Pro vývojáře se menší a relevantnější snippety přímo promítají do nižších nákladů na tokeny a lepší správy kontextu pro následné LLM.
SEAL: benchmarkování časově citlivého retrievalu
Benchmark SEAL testuje, zda retrievalový systém dokáže odpovídat na otázky, jejichž správná odpověď se v čase mění. Spolehlivé zodpovídání vyžaduje čerstvost indexu v reálném čase, chytřejší extrakci snippetů z různých průběžně aktualizovaných datových zdrojů a parsování, které dokáže identifikovat aktuální hodnotu namísto historické.
Když jsme spustili search_evals na vydání SEAL z 22. února s použitím Claude Sonnet 4.5, skóre Perplexity vzrostlo, zatímco skóre ostatních poskytovatelů v benchmarku SEAL-Hard kleslo:
Náš rámec search_evals jsme rozšířili tak, aby vedle benchmarků uvedených v našem zářijovém příspěvku zahrnoval také SEAL. Aktualizované výsledky a metodika jsou k dispozici v aktualizovaném repozitáři na GitHubu.
Podpora více dotazů
API nyní podporuje až 5 dotazů v rámci jednoho požadavku. Výsledky se vracejí seskupené podle dotazu ve stejném pořadí, v jakém byly odeslány. To snižuje počet round tripů u aplikací, které potřebují paralelně zadávat související vyhledávání, například agentů, kteří rozkládají složitou otázku na více dílčích úloh retrievalu.
Rozšířené filtrování
Kromě filtrování podle domény (allowlist a denylist, až 20 domén) a filtrování podle aktuálnosti nyní API podporuje filtrování podle jazyka pomocí kódu ISO 639-1 a regionální vyhledávání pomocí kódu země ISO. Tyto možnosti lze kombinovat pro přesné vymezení výsledků, například omezení na anglickojazyčné výsledky z německých domén.
SDK a dostupnost
Python SDK (pip install perplexityai) nyní poskytuje nativní podporu pro Search API vedle Agent API a Sonar API.
Úplná dokumentace je na docs.perplexity.ai
Sdílejte tento článek