

Geschrieben von
KI-Team
Veröffentlicht am
Beschleunigung von Sonar durch Spekulation
Spekulative Dekodierung beschleunigt die Generierungsgeschwindigkeit von großen Sprachmodellen (LLMs), indem ein schnelles und kleines Entwurfsmodell verwendet wird, um Abschluskandidaten zu erzeugen, die vom größeren Zielmodell verifiziert werden. Bei diesem Schema werden anstelle eines teuren Durchlaufs des Ziels, der ein einziges Token produziert, mehrere Tokens in einem einzigen Schritt ausgegeben. Hier präsentieren wir die Implementierungsdetails verschiedener Arten von spekulativer Dekodierung, die bei Perplexity angewendet werden, um die Zwischen-Token-Latenz auf Sonar-Modellen zu reduzieren.
Spekulative Dekodierung
Spekulative Dekodierung nutzt die Struktur natürlicher Sprachen und die autoregressive Natur von Transformern, um die Token-Generierung zu beschleunigen. Obwohl größere Modelle wie Llama-70B mehr Wissen als kleinere Modelle wie Llama-1B besitzen, erzielen sie bei einigen einfacheren Aufgaben ähnliche Ergebnisse. Diese Überschneidung deutet darauf hin, dass bestimmte Sequenzen besser von den weniger teuren Modellen generiert werden, während komplexe Probleme den größeren überlassen bleiben. Die Herausforderung besteht darin, zu bestimmen, welche Abschlüsse besser sind und ob die Generierung des kleineren Modells von derselben Qualität ist wie die des größeren.
Glücklicherweise sind LLMs autoregressive Transformer: Wenn sie eine Sequenz von Tokens erhalten, geben sie die Wahrscheinlichkeitsverteilung des nächsten Tokens aus. Auch die Logits, die aus den Zwischenmerkmalen abgeleitet werden, die mit den Tokens in der Eingabesequenz verbunden sind, zeigen, wie wahrscheinlich es ist, dass das Modell genau diese Tokens ausgibt. Diese Eigenschaft ermöglicht Spekulation: Wenn eine Sequenz von Tokens von einem kleineren Modell aus einem Eingabepräfix generiert wird, kann sie durch das größere Modell laufen, um festzustellen, wie gut sie mit dem Zielmodell übereinstimmt. Jedes Präfix der Kandidaten wird mit einer Wahrscheinlichkeit bewertet, und das längste über einem Akzeptanzschwellenwert wird ausgewählt. Als Bonus liefert das Zielmodell auch ein nachfolgendes Token kostenlos: Wenn ein Entwurfsmodell n Tokens generiert, können bis zu n + 1 in einem Schritt ausgegeben werden.
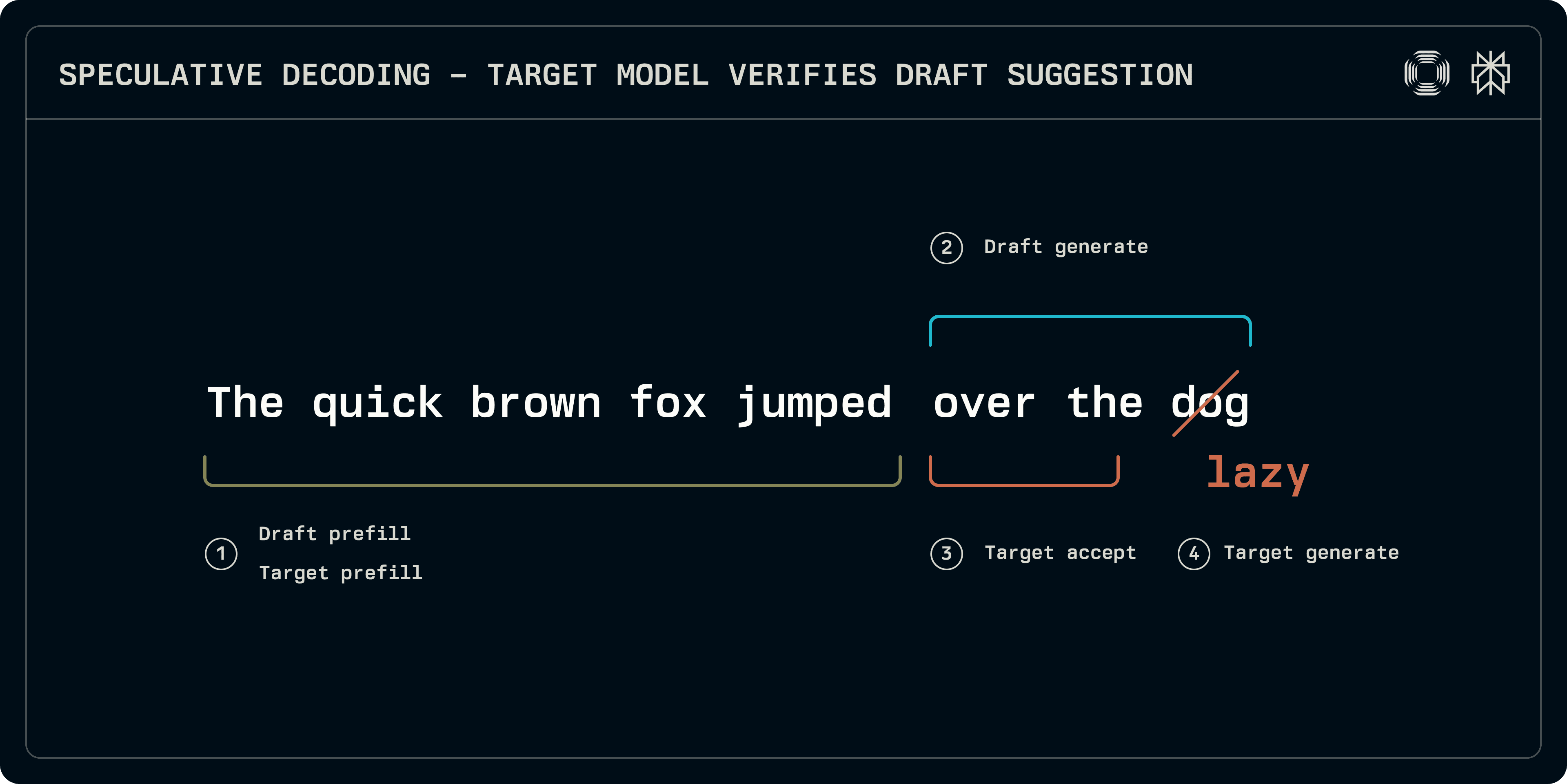
Zur Inferenzzeit kann der spekulative Samplings-Prozess grob in vier Phasen unterteilt werden:
Prefill: Sowohl das Ziel- als auch das Entwurfsmodell müssen auf der Eingabesequenz ausgeführt werden, um die KV-Cacheeinträge zu füllen. Während einige Schemata wie Medusa einfachere dichte Schichten für die Vorhersage verwenden, konzentrieren wir uns in diesem Beitrag auf transformerbasierte Entwürfe, die ihre eigenen KV-Caches benötigen.
Entwurfsgenerierung: Das Entwurfsmodell iteriert, um eine Anzahl fester Tokens zu erzeugen. Die Entwurfssequenz kann linear sein oder das Modell kann eine baumartige Struktur bis zu einer bestimmten Tiefe erkunden (EAGLE, Medusa). Hier konzentrieren wir uns auf lineare Sequenzen.
Akzeptanz: Das Zielmodell läuft auf der Entwurfssequenz und baut Logits für jedes Entwurfstoken auf. Die Länge der längsten akzeptablen Sequenz wird bestimmt.
Zielgenerierung: Da die Ziel-Logits an der nicht übereinstimmenden Position oder am Ende der Sequenz den nächstfolgenden Token entsprechen, können diese Logits verwendet werden, um ein solides Token vom Ziel zu generieren, das die Sequenz abschließt.
Es gibt verschiedene Methoden zur Implementierung spekulativer Dekodierung. In diesem Beitrag konzentrieren wir uns auf die Schemata, die wir verwendet haben, um Sonar-Modelle mit einem hauseigenen 1B-Modell zu beschleunigen, sowie auf die Vorhersagemechanismen, die wir aufbauen, um Modelle im Maßstab von DeepSeek zu beschleunigen.
Ziel-Entwurf
Spekulative Dekodierung kann erreicht werden, indem ein vorhandenes kleines LLM als Entwurfsmodell an ein Zielmodell gekoppelt wird, um Kandidatensequenzen zu erzeugen. In der Produktion haben wir Sonar unter Verwendung eines feinabgestimmten Llama-1B-Modells auf demselben Datensatz wie das Ziel beschleunigt. Obwohl bei diesem Ansatz kein Training eines Entwurfsmodells von Grund auf erforderlich war, benötigt das kleine Modell dennoch erhebliche KV-Cache-Kapazität und führt zu einem leichten Prefill-Overhead, wodurch sich die TTFT erhöht.
Bei diesem Schema spekuliert der Decoder nur über dekodierbare Batches und erzeugt Tokens durch Standard-Sampling während des Prefill oder auf gemischten Prefill-Decode-Batches. In der Prefill-Phase werden die Ziel-Logits sofort abgetastet, um auch das neu generierte Token im KV-Cache des Entwurfs vorzufüllen. Der Entwurf wird noch nicht abgetastet, aber die von ihm erzeugten Logits werden in die Dekodierungsphase übertragen.
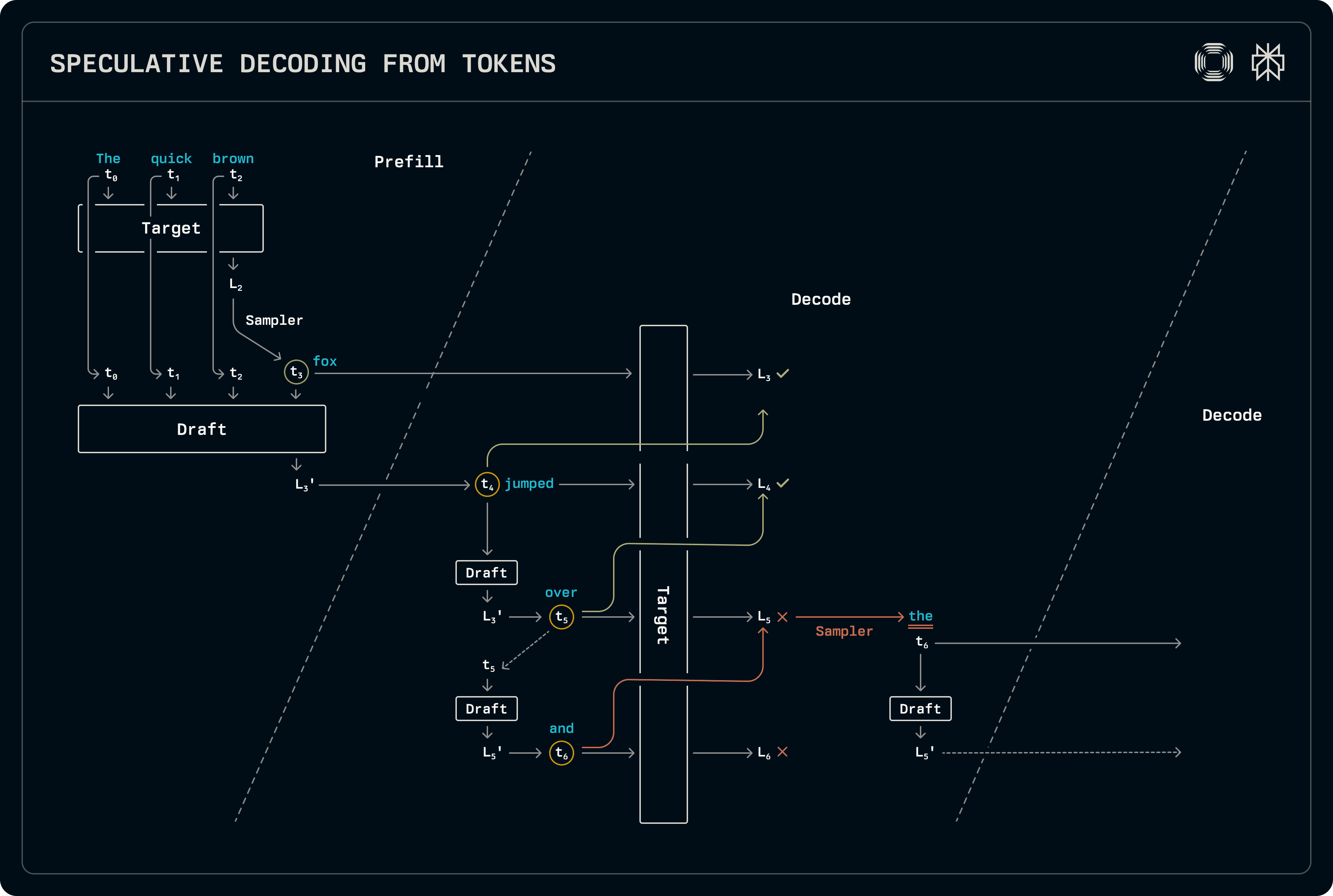
Beim Dekodieren wird das Entwurfsmodell fortgeschritten, und das oberste Token wird in jeder Phase abgetastet. Nachdem die gewünschte Entwurfslänge erreicht ist, werden die Tokens durch das Zielmodell geführt, um die Logits zu erzeugen, anhand derer das Sampler die akzeptierte Sequenzlänge identifiziert. Die Akzeptanz wird durch den Vergleich der vollständigen Wahrscheinlichkeitsverteilungen des Entwurfs und des Ziels bestimmt. Da das Ziel immer ein Set von Logits nach der akzeptierten Entwurfssequenz ausgibt, wird dieses abgetastet, um eine zusätzliche Ausgabe zu erzeugen. Da das Entwurfsmodell dieses akzeptierte Token noch nicht gesehen hat, wird es erneut ausgeführt, um die entsprechenden KV-Cache-Einträge für den nächsten Dekodierungsschritt zu füllen und die Logits erneut zu übertragen.
EAGLE
EAGLE ist ein spekulatives Dekodierungsschema, das mehrere Entwurfssequenzen untersucht, die durch baumartige Durchquerung wahrscheinlicher Entwurfstokens generiert werden. Ein fester (EAGLE) oder dynamisch geformter (EAGLE-2) Baum wird unter Verwendung aufeinanderfolgender Ausführungen der Entwurfstokens erkundet, wobei die Top-K-Kandidaten an jedem Knoten betrachtet werden, anstatt dem höchsten bewerteten Token in einer linearen Sequenz zu folgen. Die Sequenzen werden dann bewertet, und die längste geeignete wird ausgewählt, um fortzufahren, wobei auch ein zusätzliches Token vom Ziel angehängt wird.

Um genauere Vorhersagen zu erreichen, sagt ein EAGLE-Entwurfsmodell nicht nur basierend auf Tokens voraus, sondern nutzt auch die Zielmerkmale (letzte Schicht versteckter Zustände) des Zielmodells. Der Nachteil von EAGLE ist die Notwendigkeit, benutzerdefinierte, kleine Entwurfsmodelle zu trainieren, die genau genug sind, um innerhalb eines niedrigen Latenzbudgets geeignete Kandidaten zu generieren. Typischerweise ist ein Entwurfsmodell eine einzelne Transformers-Schicht, die mit einer Decoder-Schicht des Originalmodells identisch ist, das eng mit dem Ziel verbunden ist, indem es mit seinen Einbettungen und lm_head-Projektionen gekoppelt wird. Da dies weniger KV-Cache-Kapazität erfordert, hat EAGLE einen geringeren Speicherbedarf.
Um baumartige Sequenzen im Zielmodell zu überprüfen, müssen benutzerdefinierte Aufmerksamkeitsmasken verwendet werden. Leider verlangsamt die Verwendung einer benutzerdefinierten Aufmerksamkeitsmaske für eine ganze Sequenz die Aufmerksamkeit für realistische Eingabelängen erheblich (um bis zu 50 %), was einen Teil der durch Spekulation erreichbaren Geschwindigkeit zunichtemacht. Aus diesem Grund haben wir die vollständige Baumexploration noch nicht in Produktion eingesetzt, sondern uns auf den Sonderfall der Einzel-Token-Vorhersage über MTP-ähnliche Schemata konzentriert, die im DeepSeek-V3-Technischen Bericht vorgestellt wurden.
MTP
Dieses Schema ähnelt der Dekodierung nach Entwurf und Ziel, mit der Ausnahme, dass versteckte Zustände zusammen mit Tokens zur Vorhersage verwendet werden. Im Vergleich zur regulären Entwurf-Ziel-Spekulation muss in sowohl der Prefill- als auch der Dekodierungsphase etwas mehr Arbeit geleistet werden. Das Entwurfsmodell verwendet sowohl Tokens als auch versteckte Zustände: Token t_{i+1} wird aus den Logits L_i abgetastet, die dem Token t_i entsprechen, die wiederum aus den versteckten Zuständen H_i abgeleitet werden. Infolgedessen müssen die Eingabetoken-Puffer relativ zu den vom Zielmodell ausgegebenen versteckten Zustandsvektoren um einen Schritt nach links verschoben werden. Die folgende Abbildung kennzeichnet die Übereinstimmungen, die für das Training verwendet wurden, sowie die Verschiebung während der Inferenz.
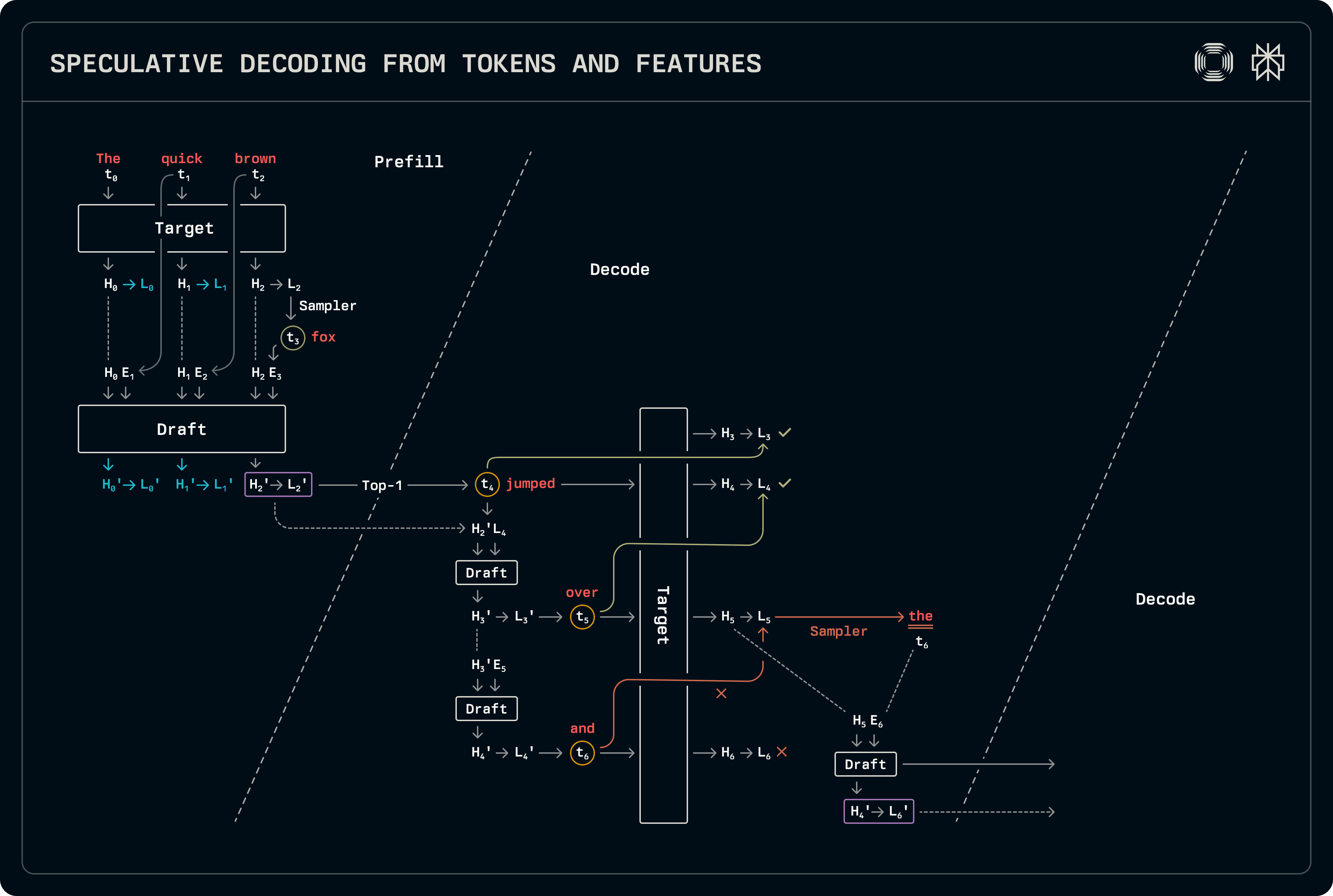
Der Dekodierungsablauf ähnelt stark der Entwurf-Ziel-Dekodierung, mit der Ausnahme, dass sowohl versteckte Zustände als auch Logits übertragen werden. Unsere Implementierung teilt alle zugehörigen Sampling- und Logitverarbeitungslogits und spezialisiert nur die Modellvorherlaufaufforderungen. Wenn mehrere Tokens vorhergesagt werden, verwendet das Entwurfsmodell Entwurf-versteckte Zustände zur Vorhersage und füllt auch KV-Cache-Einträge basierend auf seinen eigenen Merkmalen. Langfristig kann dies die Genauigkeit beeinträchtigen. Folglich, wenn das Entwurfsmodell ausgeführt wird, um den KV-Cache-Eintrag für die Zielvorhersage zu füllen, wird er auf der ganzen Sequenz unter Verwendung der genaueren versteckten Zustände des Ziels ausgeführt. Da diese Entwurfsmodelle klein sind, sind die zusätzlichen Kosten für die Verarbeitung der zusätzlichen Tokens vernachlässigbar.
Training von MTP-Köpfen
Um von MTP zu profitieren, haben wir die Infrastruktur aufgebaut, die erforderlich ist, um MTP-Köpfe zu trainieren, die an unsere fein abgestimmten Modelle auf den Datensätzen von Perplexity angehängt sind und auf einem Knoten mit 8xH100-Geräten laufen. In etwa einem Tag können wir Köpfe für Modelle von Llama-1B bis Llama-70B und DeepSeek V2-Lite aufbauen. Für größere Modelle verlassen wir uns auf MTP-Köpfe, die während des Feinabstimmungsprozesses aufgebaut wurden.
Das Ziel des MTP-Trainings besteht darin, die Entwurf-versteckten Zustände und die aus den Ziel-versteckten Zuständen extrapolierten Logits an die nächsten Token-Logits und versteckten Zustände des Ziels anzupassen. Da die Inferenz für versteckte Zustände teuer ist, berechnen wir sie vorab mit unserer inference-optimierten Implementierung des Zielmodells, um sie während des Trainings zu verwenden. Um jedoch die Inferenz-MTP-Implementierung zu validieren und sicherzustellen, dass numerische Unterschiede aufgrund von Quantisierung oder Optimierungen die Ergebnisse nicht behindern, verwenden wir für die Validierungsverluste und Genauigkeitsschätzungen vollständig die Inferenzimplementierung sowohl des Ziel- als auch des Entwurfsmodells.
Beim Hochskalieren vom ShareGPT-Datensatz, der im Originalpapier verwendet wurde, auf größere Samples stellten wir fest, dass die im EAGLE-Papier umrissene und implementierte MTP-Kopfarchetektur bei 70B-großen Modellen nicht trainiert werden konnte. Im Gegensatz zu ShareGPT, das eine größere Anzahl kürzerer Sequenzen enthielt, trainieren wir auf einer etwas kleineren Anzahl wesentlich längerer Aufforderungen. Da die ursprünglichen EAGLE-Köpfe in ihrer Struktur leicht von einem typischen Transformer abwichen, führten wir einige RMS-Normalisierungsschichten wieder ein, die entfernt worden waren. Wir stellten fest, dass dies nicht nur das Training zum Konvergieren brachte, sondern auch die Genauigkeit der Köpfe um einige Prozentpunkte steigerte.

Nicht nur erleichtern Schichtnormen das Training, das Wiedereinführen der Normen ist auch mathematisch intuitiv. MTP-Köpfe verwenden die Einbettungen und die Logit-Projektionen des Zielmodells wieder, da sie erheblich groß sein können (etwa 2 GB für Llama 70B). Während des Trainings sind diese eingefroren, und es wird erwartet, dass die MTP-Schicht lernt, Vorhersagen in denselben Vektorraum einzubetten, den die Projektschicht des Originalmodells während des Trainings gelernt hat. Durch das Weglassen der Normen wird von einem einzelnen MLP erwartet, dass es dieselbe Funktion lernt wie ein MLP, gefolgt von einer Norm, was das Angleichung zwischen den versteckten Zuständen der Entwurfs- und der Zielmodelle erschwert.
Inferenz mit spekulativer Dekodierung
Im Inferenzmodul, um Tokens für Eingabesequenzen zu erzeugen, müssen sie zuerst in vernünftig große Batches gruppiert werden, dann müssen Seiten im KV-Cache für die nächsten Tokens zugewiesen werden. Die Eingabetokens und die KV-Seiteninformationen werden dann in einen Puffer gepackt, der an alle parallelen Ränge gesendet wird, die das Modell ausführen. Schließlich werden die Metadaten in den GPU-Speicher kopiert und das Modell ausgeführt, um die Logits zu erzeugen, aus denen das nächste Token abgetastet wird.
Im Gegensatz zu bestimmten Implementierungen, die einen Entwurfs- und Zielinferenz-Server locker über einen Wrapper koppeln, der die Anfragen zwischen ihnen organisiert, sind unsere Entwurf-Ziel-Paare eng gekoppelt und durchlaufen die Generierung gemeinsam. Batch-Planung und KV-Seiteneinzug werden zwischen den Modellen für alle Formen spekulativer Dekodierung geteilt: dies vereinfacht die Logik, die ein Modell mit dem übergeordneten Inferenzserver verbindet, da sie alle dieselbe Schnittstelle bereitstellen.
Die Inferenzlaufzeit bei Perplexity basiert auf FlashInfer, das die Metadaten bestimmt, die erstellt werden müssen, um den Attention-Kernel zu konfigurieren und zu planen. Gegeben sind einige Eingabesequenzen, die ein Batch bilden, für Prefill, Dekodieren oder Verifizierung muss auf der CPU-Seite Arbeit geleistet werden, um Zwischenpuffer zuzuweisen und bestimmte konstante Puffer zu füllen, die in der Aufmerksamkeit verwendet werden. Diese Arbeit kommt zusätzlich zu den Kosten der Batch-Scheduling- und KV-Seitenzuweisungen hinzu, die ebenfalls Latenzzeiten verursachen, die verborgen werden müssen, um die GPU-Auslastung zu maximieren.
Während wir die CPU-seitige und GPU-seitige Arbeit für die Inferenz ohne Spekulation vollständig parallelisiert haben, stellten wir fest, dass das CPU-GPU-Gleichgewicht für die spekulative Dekodierung komplexer ist. Die Hauptherausforderung entsteht daraus, dass die Anzahl der akzeptierten Tokens die Sequenzlänge für einen nachfolgenden Lauf bestimmt, was einen kaum vermeidbaren GPU-zu-CPU-Synchronisationspunkt einführt. Wir experimentierten mit verschiedenen Planungsschemata, um die Latenzzeit der CPU-Arbeit bestmöglich zu verbergen.
Entwurf-Ziel-Zeitplan
Auch wenn er kleiner als ein Zielmodell ist, führt ein ganzes LLM als Entwurf dennoch zu beträchtlicher Latenz auf der GPU und bietet etwas Spielraum, um teure CPU-Operationen zu verbergen. Da kleinere Modelle nicht von der Tensor-Parallelverarbeitung profitieren, besteht eine Diskrepanz zwischen der Anzahl der Ränge, auf die ein Ziel und ein Entwurf verteilt sind. In unserer Implementierung läuft das Entwurfsmodell nur auf dem Führungsrang einer TP-Gruppe.
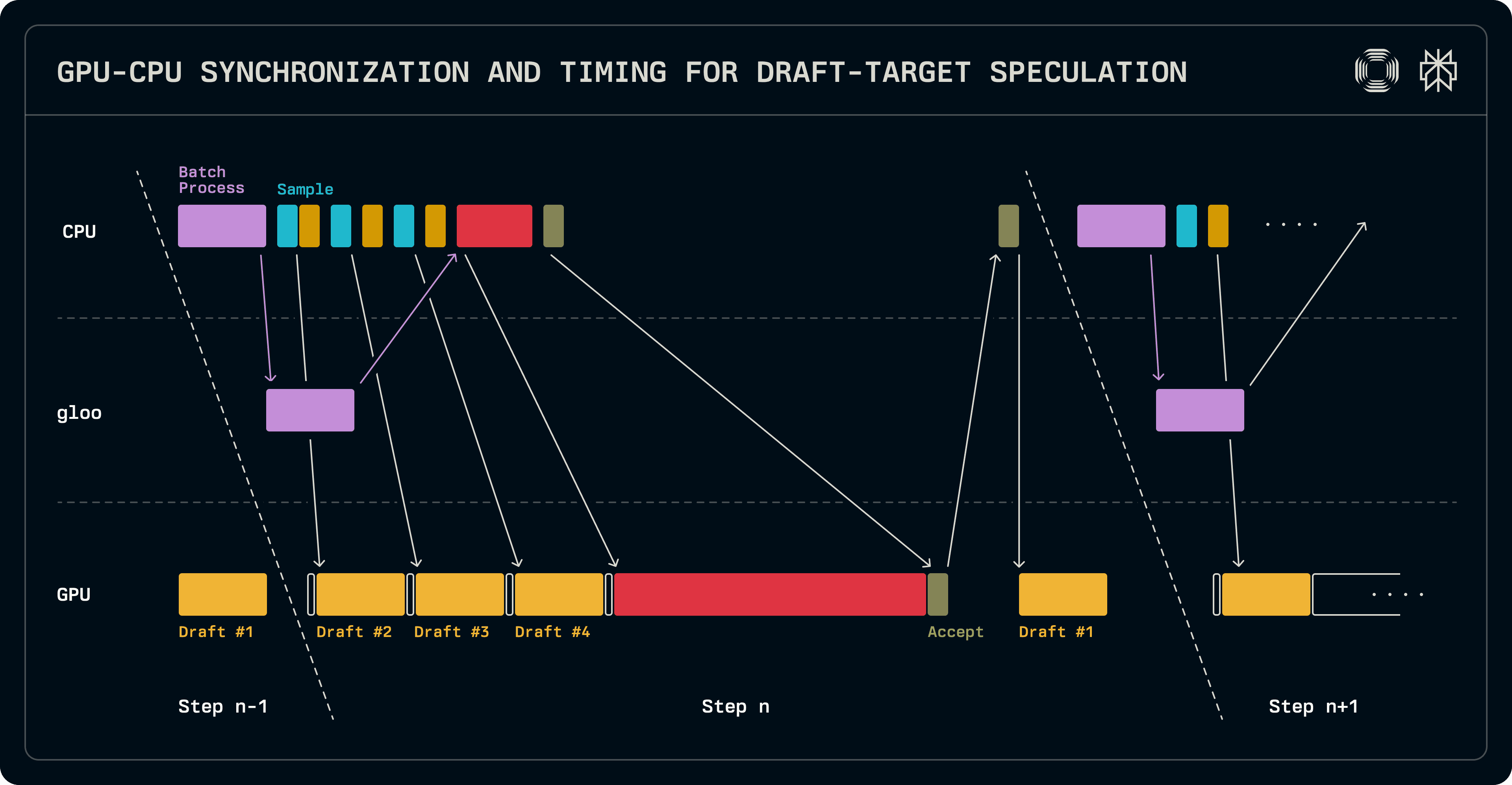
Wie bereits erwähnt, werden Logits bei einem Dekodiervorgang in den nächsten Lauf übertragen. Dies erlaubt es uns, eine Ausführung des Entwurfsmodells mit der CPU-seitigen Batch-Planungsarbeit zu überlappen. Nachdem das Batch zusammengestellt ist, erzeugen wiederholte Aufrufe des Samplers und des Entwurfs die Entwurf-Tokens. Parallel dazu wird das Batch zur Verifizierung für das Zielmodell zusammengestellt und mit den parallelen Arbeitern synchronisiert. Die Ziel-Logits werden verifiziert und abgetastet, um die akzeptierten Sequenzlängen zu bestimmen. An diesem Punkt ist eine GPU-zu-CPU-Synchronisation notwendig, um die nachfolgenden Sequenzlängen festzulegen. Da das Entwurfsmodell nur auf dem Führungsrang ausgeführt wird, wird dessen Batch sequenziell eingerichtet, und seine Ausführung wird gestartet, um seine KV-Cache-Einträge mit dem zusätzlichen Token zu füllen, das das Ziel produziert hat. Die Logits, die dieser Entwurfslauf produziert, werden im aktuellen Lauf verwendet, um das erste Entwurfstoken im folgenden Lauf zu samplen. Am wichtigsten ist, dass während des Entwurfs die nächste Charge geplant werden kann.
MTP-Zeitplan für ein einzelnes Token
Während das Laufzeitsystem noch keine Eagle-Style-Entwurf-Baumerkundung bietet, haben wir einen Sonderfall dieses Schemas implementiert, bei dem eine lineare Sequenz von Entwurfstokens verwendet wird, die von einem Modell in der Größe einer einzelnen Transformer-Decoder-Schicht erzeugt werden. Dieses Schema kann zur Entwurfsprognose mit den Open-Source-Gewichten von DeepSeek R1 verwendet werden. Der Unterfall der Vorhersage eines einzelnen Tokens ist interessant, da große MTP-Schichten ausreichend hohe Akzeptanzquoten erreichen, um ihren Overhead zu rechtfertigen.
MTP-Planung ist etwas komplexer, da das Entwurfsmodell viel schneller ist und dadurch weniger CPU-seitige Latenz verbirgt. Zudem ist der Entwurf zusammen mit dem Zielmodell geshardet, was gemeinsame Speicherübertragungen für Batch-Informationen erfordert. Ein Lauf beginnt mit der Übertragung von Batch-Informationen und der Abtastung des ersten Tokens aus Übertragungs-Logits, ähnlich wie beim vorherigen Schema. Als nächstes wird das Ziel ausgeführt, um Tokens zu validieren und 2 * D Tokens zu verarbeiten, wobei D die Dekodierverschachtelungsgröße ist. Dies ist ideal für das Micro-Batching in Mixture-of-Experts (MoE)-Modellen über langsamere Verbindungen wie InfiniBand, da das Batch gleichmäßig in zwei Hälften geteilt wird. Die versteckten Zustände des Ziels werden für den nächsten Entwurfslauf übertragen, während die Logits zur Verifizierung in den Sampler übergeben werden.

Durch eine begrenzte Menge zusätzlicher Arbeit auf der GPU vermeiden wir eine CPU-zu-GPU-Synchronisation nach der Annahme der Entwurfssequenz. Nachdem die Eingangstokens der Ziele verschoben wurden, wird ein Kernel die nächsten Zieltokens in ihre entsprechenden Positionen einfügen. Der Entwurf wird dann mit denselben Batch-Informationen wie das Ziel erneut durchgeführt, wobei KV-Cache-Einträge und Logits und versteckte Zustände für den nächsten Lauf erstellt werden, wobei einige redundante Arbeit an Tokens geleistet wird, die nicht angenommen wurden. In diesen Situationen ist die Latenz der ungenutzten Arbeit kaum messbar, da das Entwurfsmodell klein ist. Parallel zur Entwurfsdurchführung werden die Sequenzlängen auf der CPU bestimmt und die Planung der nächsten Charge wird eingeleitet, ohne auf die Beendigung der GPU-Arbeit warten zu müssen.
Der Overhead zusätzlicher Arbeit in der Entwurfschicht ist bei der Aufmerksamkeit nicht bemerkbar, jedoch sind MLP-Schichten problematischer. Da Matrizenmultiplikationsanweisungen zu einer Grenze von 64 in Bezug auf die Anzahl der Tokens abgepaddet werden, wird, wenn eine Verdopplung nicht signifikant mehr Blöcke erfordert, der Overhead verborgen. Für längere Entwurfssequenzen ist der Overhead teurer, und das Schema, das für reguläre Entwurf-Ziel-Modelle verwendet wird, funktioniert besser.
Referenzen
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving