

Geschrieben von
Perplexity Team
Veröffentlicht am
Search API: Bessere Extraktion, dynamische Benchmarks
Im September haben wir einen technischen Überblick über die Architektur der Perplexity Search API veröffentlicht und search_evals, unser Open-Source-Evaluierungsframework zum Benchmarking von Search APIs in agentischen Workflows, freigegeben. Seitdem galt die wichtigste Investition der Qualität von Snippets, optimiert entlang zweier Dimensionen: Relevanz und Größe. Die Rückgabe der richtigen Inhalte in der richtigen Menge bestimmt unmittelbar die Genauigkeit nachgelagerter Antworten und die Token-Effizienz. Die dafür erforderliche Arbeit umfasste den Aufbau neuer Systeme für Extraktion, Span-Level-Labeling und Evaluierung, insbesondere einer Span-Labeling-Pipeline, die ermittelt, welche Segmente eines Quelldokuments für eine bestimmte Abfrage relevant sind.
Bewertung von Snippets auf Span-Ebene
Um Snippets systematisch zu verbessern, haben wir ein neues Evaluierungssystem entwickelt. Für eine bestimmte Abfrage und ein bestimmtes Dokument identifiziert und kennzeichnet das System Spans innerhalb des Dokuments nach ihrer Beziehung zur Abfrage: „essenzielle“ Spans, die im Snippet enthalten sein müssen, verschiedene Klassen „irrelevanter“ Spans, die ausgeschlossen werden sollten, Duplikate und weitere Kategorien. Dieses Labeling auf Span-Ebene ermöglicht es uns, die Qualität von Snippets mit einem Präzisionsgrad zu bewerten, der zuvor nicht möglich war, indem sowohl gemessen wird, was korrekt aufgenommen wurde, als auch, was korrekt weggelassen wurde.
In der Praxis ermöglichen uns diese Verbesserungen, kleinere Snippets zu erzeugen, die für die Abfrage relevanter sind. Unsere sich selbst verbessernde Pipeline zum Inhaltsverständnis verarbeitet nun ein breiteres Spektrum strukturierter Datenformate, darunter Tabellen, verschachtelte Listen und dynamisch gerenderte Inhalte, die frühere Regelsätze nicht zuverlässig parsen konnten.
Diese Verbesserungen entstanden aus unseren eigenen Produktionssystemen. Während unsere interne Forschung die Relevanz und Größenbestimmung von Snippets vorantrieb, zeigten interne Evaluierungen, dass kleinere Inhaltsbudgets nach einer Reihe von Qualitätsverbesserungen tatsächlich genauere Ergebnisse lieferten. Wir haben einige Änderungen an unseren Standardkonfigurationen vorgenommen, um diese Erkenntnisse abzubilden, und dabei die Größe der Response-Payloads sowie die Latenz reduziert, während pro Ergebnis nützlichere Inhalte geliefert werden. Für Entwickler übersetzen sich kleinere, relevantere Snippets unmittelbar in geringere Token-Kosten und ein besseres Kontextmanagement für nachgelagerte LLMs.
SEAL: Benchmarking zeitkritischer Retrievals
Der SEAL-Benchmark testet, ob ein Retrieval-System Fragen beantworten kann, deren korrekte Antwort sich im Laufe der Zeit verändert. Eine zuverlässige Beantwortung erfordert die Aktualität des Indexes in Echtzeit, eine intelligentere Snippet-Extraktion aus verschiedenen kontinuierlich aktualisierten Datenquellen und ein Parsing, das den aktuellen statt eines historischen Werts erkennen kann.
Als wir search_evals mit Claude Sonnet 4.5 gegen die SEAL-Veröffentlichung vom 22. Februar ausführten, stiegen die Perplexity-Werte, während andere Anbieter bei SEAL-Hard zurückfielen:
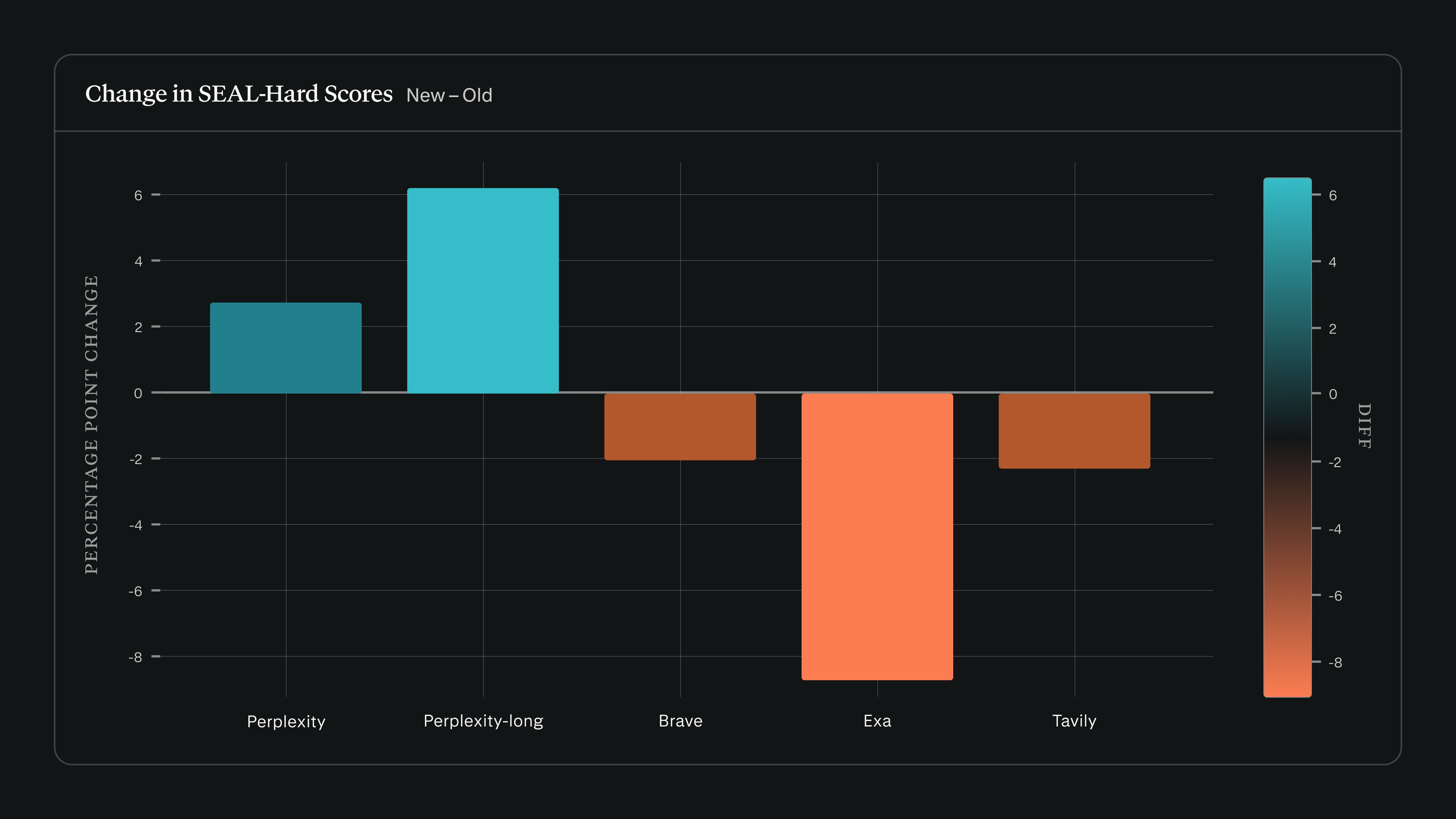
Wir haben unser search_evals-Framework erweitert, um SEAL zusammen mit den Benchmarks einzuschließen, die in unserem September-Beitrag berichtet wurden. Aktualisierte Ergebnisse und die Methodik sind im aktualisierten Repository auf GitHub verfügbar.
Unterstützung für mehrere Abfragen
Die API unterstützt jetzt bis zu 5 Abfragen in einer einzelnen Anfrage. Die Ergebnisse werden nach Abfrage gruppiert und in derselben Reihenfolge zurückgegeben, in der sie übermittelt wurden. Dadurch werden Roundtrips für Anwendungen reduziert, die verwandte Suchen parallel ausführen müssen, etwa Agenten, die eine komplexe Frage in mehrere Retrieval-Teilaufgaben zerlegen.
Erweiterte Filterung
Zusätzlich zur Domain-Filterung (Allowlist und Denylist, bis zu 20 Domains) und zur Aktualitätsfilterung unterstützt die API jetzt Sprachfilterung per ISO-639-1-Code sowie regionale Suche per ISO-Ländercode. Diese lassen sich kombinieren, um Ergebnisse präzise einzugrenzen, zum Beispiel auf englischsprachige Ergebnisse aus deutschen Domains.
SDK und Verfügbarkeit
Das Python SDK (pip install perplexityai) bietet jetzt native Unterstützung für die Search API neben Agent API und Sonar API.
Die vollständige Dokumentation finden Sie unter docs.perplexity.ai
Search API: Bessere Extraktion, dynamische Benchmarks
Im September haben wir einen technischen Überblick über die Architektur der Perplexity Search API veröffentlicht und search_evals, unser Open-Source-Evaluierungsframework zum Benchmarking von Search APIs in agentischen Workflows, freigegeben. Seitdem galt die wichtigste Investition der Qualität von Snippets, optimiert entlang zweier Dimensionen: Relevanz und Größe. Die Rückgabe der richtigen Inhalte in der richtigen Menge bestimmt unmittelbar die Genauigkeit nachgelagerter Antworten und die Token-Effizienz. Die dafür erforderliche Arbeit umfasste den Aufbau neuer Systeme für Extraktion, Span-Level-Labeling und Evaluierung, insbesondere einer Span-Labeling-Pipeline, die ermittelt, welche Segmente eines Quelldokuments für eine bestimmte Abfrage relevant sind.
Bewertung von Snippets auf Span-Ebene
Um Snippets systematisch zu verbessern, haben wir ein neues Evaluierungssystem entwickelt. Für eine bestimmte Abfrage und ein bestimmtes Dokument identifiziert und kennzeichnet das System Spans innerhalb des Dokuments nach ihrer Beziehung zur Abfrage: „essenzielle“ Spans, die im Snippet enthalten sein müssen, verschiedene Klassen „irrelevanter“ Spans, die ausgeschlossen werden sollten, Duplikate und weitere Kategorien. Dieses Labeling auf Span-Ebene ermöglicht es uns, die Qualität von Snippets mit einem Präzisionsgrad zu bewerten, der zuvor nicht möglich war, indem sowohl gemessen wird, was korrekt aufgenommen wurde, als auch, was korrekt weggelassen wurde.
In der Praxis ermöglichen uns diese Verbesserungen, kleinere Snippets zu erzeugen, die für die Abfrage relevanter sind. Unsere sich selbst verbessernde Pipeline zum Inhaltsverständnis verarbeitet nun ein breiteres Spektrum strukturierter Datenformate, darunter Tabellen, verschachtelte Listen und dynamisch gerenderte Inhalte, die frühere Regelsätze nicht zuverlässig parsen konnten.
Diese Verbesserungen entstanden aus unseren eigenen Produktionssystemen. Während unsere interne Forschung die Relevanz und Größenbestimmung von Snippets vorantrieb, zeigten interne Evaluierungen, dass kleinere Inhaltsbudgets nach einer Reihe von Qualitätsverbesserungen tatsächlich genauere Ergebnisse lieferten. Wir haben einige Änderungen an unseren Standardkonfigurationen vorgenommen, um diese Erkenntnisse abzubilden, und dabei die Größe der Response-Payloads sowie die Latenz reduziert, während pro Ergebnis nützlichere Inhalte geliefert werden. Für Entwickler übersetzen sich kleinere, relevantere Snippets unmittelbar in geringere Token-Kosten und ein besseres Kontextmanagement für nachgelagerte LLMs.
SEAL: Benchmarking zeitkritischer Retrievals
Der SEAL-Benchmark testet, ob ein Retrieval-System Fragen beantworten kann, deren korrekte Antwort sich im Laufe der Zeit verändert. Eine zuverlässige Beantwortung erfordert die Aktualität des Indexes in Echtzeit, eine intelligentere Snippet-Extraktion aus verschiedenen kontinuierlich aktualisierten Datenquellen und ein Parsing, das den aktuellen statt eines historischen Werts erkennen kann.
Als wir search_evals mit Claude Sonnet 4.5 gegen die SEAL-Veröffentlichung vom 22. Februar ausführten, stiegen die Perplexity-Werte, während andere Anbieter bei SEAL-Hard zurückfielen:
Wir haben unser search_evals-Framework erweitert, um SEAL zusammen mit den Benchmarks einzuschließen, die in unserem September-Beitrag berichtet wurden. Aktualisierte Ergebnisse und die Methodik sind im aktualisierten Repository auf GitHub verfügbar.
Unterstützung für mehrere Abfragen
Die API unterstützt jetzt bis zu 5 Abfragen in einer einzelnen Anfrage. Die Ergebnisse werden nach Abfrage gruppiert und in derselben Reihenfolge zurückgegeben, in der sie übermittelt wurden. Dadurch werden Roundtrips für Anwendungen reduziert, die verwandte Suchen parallel ausführen müssen, etwa Agenten, die eine komplexe Frage in mehrere Retrieval-Teilaufgaben zerlegen.
Erweiterte Filterung
Zusätzlich zur Domain-Filterung (Allowlist und Denylist, bis zu 20 Domains) und zur Aktualitätsfilterung unterstützt die API jetzt Sprachfilterung per ISO-639-1-Code sowie regionale Suche per ISO-Ländercode. Diese lassen sich kombinieren, um Ergebnisse präzise einzugrenzen, zum Beispiel auf englischsprachige Ergebnisse aus deutschen Domains.
SDK und Verfügbarkeit
Das Python SDK (pip install perplexityai) bietet jetzt native Unterstützung für die Search API neben Agent API und Sonar API.
Die vollständige Dokumentation finden Sie unter docs.perplexity.ai
Diesen Artikel teilen