

Γραμμένο από
Ομάδα Τεχνητής Νοημοσύνης
Δημοσιεύτηκε την
Αυξημένη Σαφήνεια μέσω Υποψίας
Η υποψιασμένη αποκωδικοποίηση επιταχύνει την ταχύτητα παραγωγής μεγάλων γλωσσικών μοντέλων (LLMs) χρησιμοποιώντας ένα γρήγορο και μικρό υπόδειγμα για να παράγει υποψήφια αποτελέσματα που επαληθεύονται από το μεγαλύτερο μοντέλο στόχο. Με αυτό το σχέδιο, αντί για μια τρέχουσα δαπανηρού στόχου που παράγει ένα μόνο διακριτό, εκπέμπονται πολλές διακριτές σε ένα μόνο βήμα. Εδώ παρουσιάζουμε τις λεπτομέρειες υλοποίησης διάφορων ειδών υποψιασμένης αποκωδικοποίησης, εφαρμοσμένων στο Perplexity για να μειώσουμε τη χρονική καθυστέρηση μεταξύ διακριτών μοντέλων Sonar.
Υποψιασμένη Αποκωδικοποίηση
Η υποψιασμένη αποκωδικοποίηση αξιοποιεί τη δομή των φυσικών γλωσσών και τη αυτό-αναδρομική φύση των μεταμορφωτών για να επιταχύνει την παραγωγή διακριτών. Παρόλο που τα μεγαλύτερα μοντέλα, όπως το Llama-70B, φέρουν περισσότερη γνώση από τα μικρότερα, όπως το Llama-1B, σε ορισμένες απλούστερες εργασίες επιτελούν παρόμοια. Αυτή η υπερκάλυψη υποδηλώνει ότι ορισμένες ακολουθίες είναι καλύτερα παραγόμενες από τα λιγότερο δαπανηρά μοντέλα, αφήνοντας σύνθετα προβλήματα σε μεγαλύτερα. Η πρόκληση έγκειται στη διαπίστωση ποια αποτελέσματα είναι καλύτερα και αν η παραγωγή του μικρότερου μοντέλου είναι της ίδιας ποιότητας με την του μεγαλύτερου.
Ευτυχώς, οι LLMs είναι αυτό-αναδρομικοί μεταμορφωτές: όταν δοθεί μια ακολουθία διακριτών, εξάγουν την κατανομή πιθανότητας του επόμενου διακριτού. Επιπλέον, οι λογισμοί που προκύπτουν από τα ενδιάμεσα χαρακτηριστικά που σχετίζονται με τα διακριτά στην εισαγωγική ακολουθία δείχνουν επίσης πόσο πιθανό είναι για το μοντέλο να εκδώσει αυτές τις ακριβείς διακριτές. Αυτή η ιδιότητα επιτρέπει την υποψία: αν μια ακολουθία διακριτών παραχθεί από ένα μικρότερο που ξεκινά από μια εισαγωγική προθέση, μπορεί να εκτελεστεί μέσω του μεγαλύτερου για να προσδιορίσει πόσο καλά ευθυγραμμίζεται με το μοντέλο στόχο. Κάθε πρόθεση των υποψηφίων βαθμολογείται με μια πιθανότητα και η μεγαλύτερη που είναι πάνω από ένα αποδεκτό όριο επιλέγεται. Ως μπόνους, το μοντέλο στόχος παρέχει επίσης ένα επόμενο διακριτό δωρεάν: αν ένα υπόδειγμα παράγει n διακριτές, έως n + 1 μπορούν να εκτελούνται σε ένα βήμα.
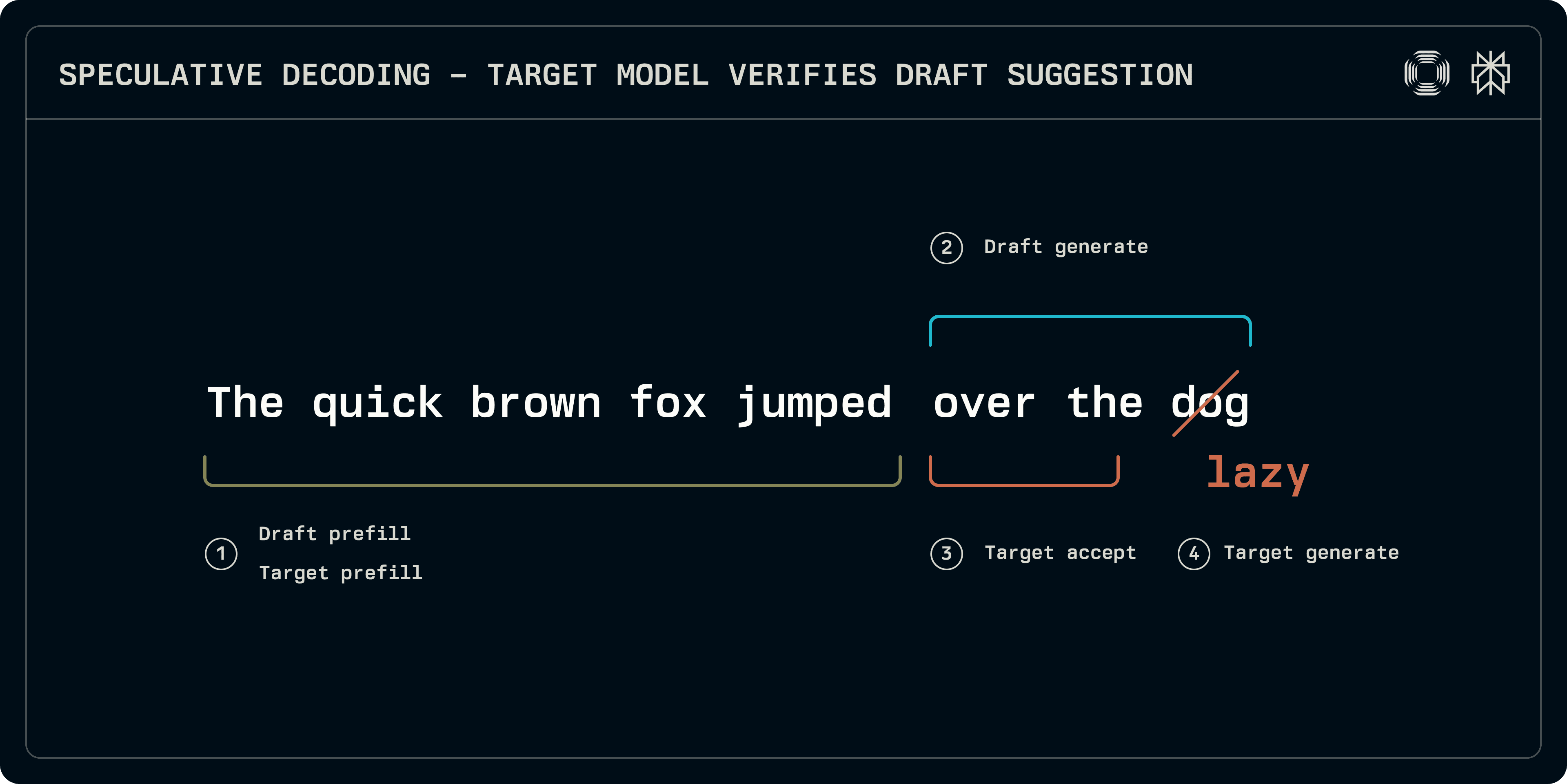
Στην ώρα της εκτίμησης, η διαδικασία υποψιασμένου δειγματοληπτη μπορεί να χωριστεί σε περίπου 4 στάδια:
Προετοιμασία: τόσο το μοντέλο στόχος όσο και το υπόδειγμα πρέπει να εκτελούνται στην εισαγωγική ακολουθία για να γεμίσουν τις εγγραφές KV cache. Ενώ ορισμένα σχέδια, όπως το Medusa, χρησιμοποιούν απλούστερες πυκνές στρώσεις για πρόβλεψη, σε αυτήν την ανάρτηση εστιάζουμε σε βάσεις μεταμορφωτή που απαιτούν δικές τους KV cache.
Γενεά υποδείγματος: το υπόδειγμα επαναλαμβάνει για να παραγάγει έναν αριθμό σταθερών διακριτών. Η υποδειγματική ακολουθία μπορεί να είναι γραμμική ή το μοντέλο μπορεί να εξερευνήσει μια δέντρο-όμοια δομή μέχρι ένα δεδομένο βάθος (EAGLE, Medusa). Εδώ, εστιάζουμε σε γραμμικές ακολουθίες.
Αποδοχή: το μοντέλο στόχος εκτελείται στην υποδειγματική ακολουθία, δημιουργώντας λογισμούς που αντιστοιχούν σε κάθε διακριτό υποδείγματος. Η διάρκεια της μεγαλύτερης αποδεκτής ακολουθίας προσδιορίζεται.
Γενεά στόχου: καθώς το μοντέλο στόχου παράγει λογισμούς, στη θέση ασυμμετρία ή στο τέλος της ακολουθίας οι λογισμοί αντιστοιχούν σε ένα επόμενο διακριτό. Αυτοί οι λογισμοί μπορούν να δειγματοληφθούν για να παρέχουν ένα robust διακριτό από το στόχο, κλείνοντάς την ακολουθία.
Υπάρχουν διάφορες μέθοδοι για την υλοποίηση υποψιασμένης αποκωδικοποίησης. Σε αυτήν την ανάρτηση, θα εστιάσουμε στις μεθόδους που χρησιμοποιήσαμε για να αυξήσουμε τα μοντέλα Sonar χρησιμοποιώντας ένα εσωτερικό μοντέλο 1B, καθώς και στους μηχανισμούς πρόβλεψης που δημιουργούμε για να επιταχύνουμε μοντέλα κλίμακας DeepSeek.
Στόχος-Υπόδειγμα
Η υποψιασμένη αποκωδικοποίηση μπορεί να επιτευχθεί συνδυάζοντας ένα υπάρχον μικρό LLM ως υπόδειγμα με ένα μοντέλο στόχο για να δημιουργήσει υποψήφιες ακολουθίες. Στην παραγωγή, έχουμε επιταχύνει τα Sonar χρησιμοποιώντας ένα μοντέλο Llama-1B που έχει τελειοποιηθεί στο ίδιο σύνολο δεδομένων με το στόχο. Ενώ αυτή η προσέγγιση δεν απαιτούσε εκπαίδευση ενός υποδείγματος από την αρχή, το μικρό μοντέλο χρησιμοποιεί ακόμα σημαντική χωρητικότητα KV cache και εισάγει μια ελαφριά επιβάρυνση προετοιμασίας, αυξάνοντας το TTFT.
Σύμφωνα με αυτό το σχέδιο, ο αποκωδικοποιητής υποψήφεται μόνο σε batches αποκωδικοποίησης, παράγοντας διακριτά μέσω τυπικής δειγματοληπτικής κατά τη διάρκεια της προετοιμασίας ή σε μικτά batches προετοιμασίας-αποκωδικοποίησης. Στη φάση προετοιμασίας, οι λογισμοί στόχου δειγματοληπτούνται άμεσα για να προετοιμάσουν επίσης το νέο παραγόμενο διακριτό στην KV cache του υποδείγματος. Το υπόδειγμα δεν έχει δειγματοληφθεί ακόμη, αλλά οι λογισμοί που παράγει μεταφέρονται στη φάση αποκωδικοποίησης.
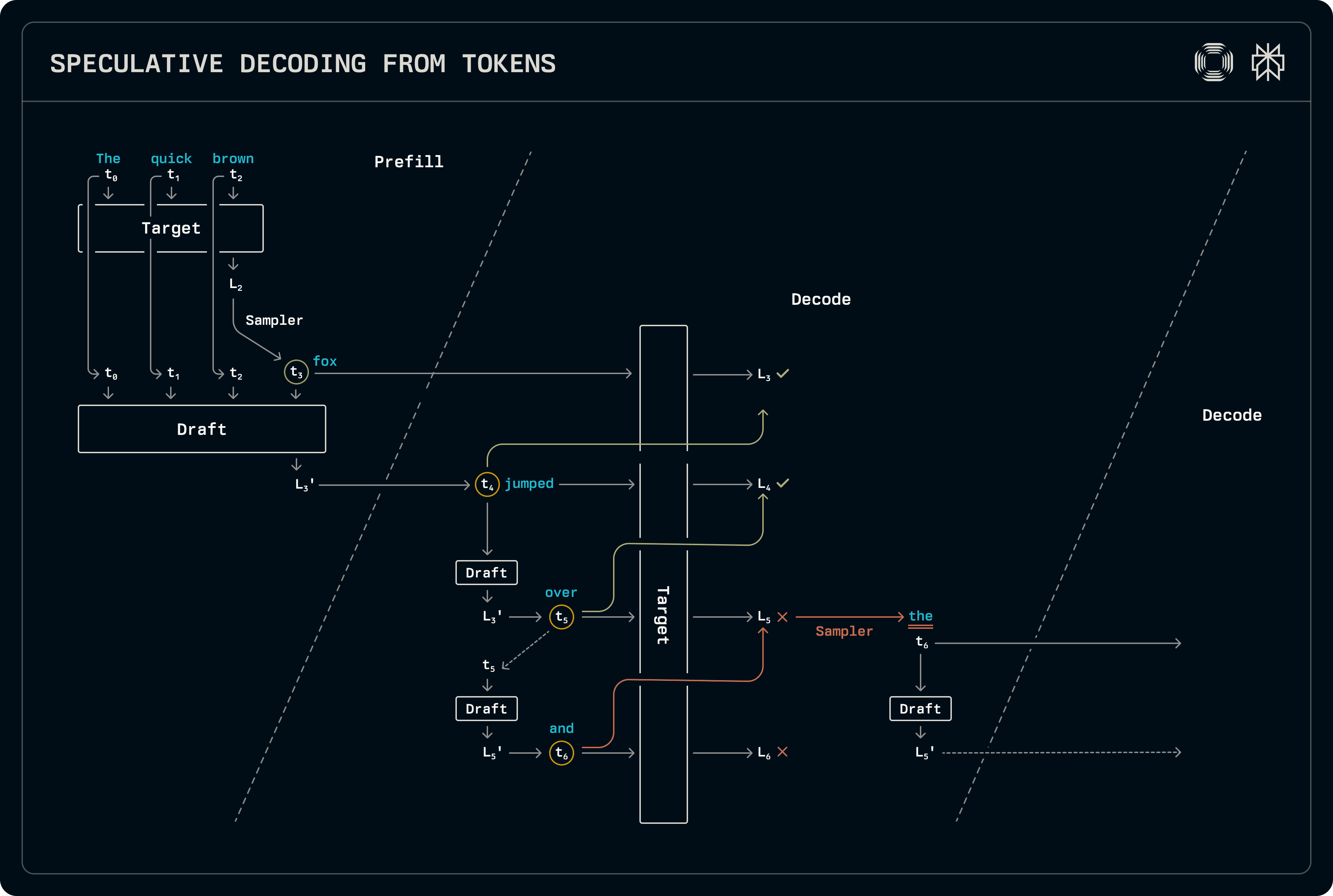
Στην αποκωδικοποίηση, το υπόδειγμα μοντέλο προχωρά, δειγματολαμβάνοντας το κορυφαίο διακριτό σε κάθε στάδιο. Αφού επιτευχθεί η επιθυμητή διάρκεια του υποδείγματος, οι διακριτές διεξάγονται μέσω του μοντέλου στόχου για να παραχθούν οι λογισμοί με βάση τους οποίους η δειγματολήπτης προσδιορίζει τη διάρκεια της αποδεκτής ακολουθίας. Η αποδοχή καθορίζεται συγκρίνοντας τις πλήρεις κατανομές πιθανοτήτων από το υπόδειγμα και το στόχο. Καθώς το μοντέλο στόχος πάντα εξάγει ένα σύνολο λογισμών κατόπιν της αποδεκτής υποδειγματικής ακολουθίας, αυτό δειγματοληπτείται για να παραγάγει μία επιπλέον έξοδο. Καθώς το μοντέλο υπόδειγμα δεν έχει δει ακόμη αυτό το αποδεκτό διακριτό, επαναλαμβάνεται για να γεμίσει τις αντίστοιχες εγγραφές KV cache στην προετοιμασία για το επόμενο βήμα αποκωδικοποίησης, μεταφέροντας ξανά τους λογισμούς.
EAGLE
Το EAGLE είναι σχέδιο υποψιασμένης αποκωδικοποίησης που εξερευνά πολλές υποδειγματικές ακολουθίες, παραγόμενες μέσω μιας δέντρο-όμοιας διαδρομής πιθανών διακριτών υποδειγμάτων. Ένα σταθερό (EAGLE) ή δυναμικά διαμορφωμένο (EAGLE-2) δέντρο εξερευνάται χρησιμοποιώντας διαδοχικές εκτελέσεις των διακριτών υποδειγμάτων, εξετάζοντας τους κορυφαίους K υποψηφίους σε κάθε κόμβο αντί να ακολουθεί το υψηλότερο διακριτό σε μια γραμμική ακολουθία. Οι ακολουθίες αξιολογούνται και η μεγαλύτερη κατάλληλη επιλέγεται για συνέχιση, προσθέτοντας επίσης ένα επιπλέον διακριτό από το στόχο.

Για να επιτευχθεί πιο ακριβής πρόβλεψη, ένα μοντέλο υποδείγματος EAGLE προβλέπει όχι μόνο με βάση τα διακριτά, αλλά και με τη χρήση των χαρακτηριστικών στόχου (κρυφές καταστάσεις τελευταίου επιπέδου) του μοντέλου στόχου. Το μειονέκτημα του EAGLE είναι η ανάγκη εκπαίδευσης προσαρμοσμένων, μικρών υποδειγμάτων που είναι αρκετά ακριβή για να παράγουν κατάλληλους υποψηφίους εντός ενός χαμηλού λανθάνοντα κόστους. Συνήθως, ένα υπομέτρο είναι ένα ενιαίο στρώμα μεταμορφωτή ταυτόσημο με ένα στρώμα αποκωδικοποιητή του αρχικού μοντέλου, το οποίο συνδέεται στενά με το στόχο συνδέοντας τα ενσωματωμένα του και οι προβολές lm_head. Δεδομένου ότι αυτό απαιτεί λιγότερη χωρητικότητα KV cache, το EAGLE έχει χαμηλότερο αποτύπωμα μνήμης.
Για να επαληθευτούν οι δέντρο-όμοιες ακολουθίες στο μοντέλο στόχου, πρέπει να χρησιμοποιηθούν προσαρμοσμένες μάσκες προσοχής. Δυστυχώς, η χρήση μιας προσαρμοσμένης μάσκας προσοχής για μια ολόκληρη ακολουθία επιβραδύνει σημαντικά την προσοχή για ρεαλιστικά μήκη εισόδου (έως 50%), ακυρώνοντας μέρος της επιτάχυνσης που είναι εφικτή μέσω της υποψίας. Δεν έχουμε ακόμη αναπτύξει πλήρη εξερεύνηση δέντρων στην παραγωγή για αυτόν τον λόγο, εστιάζοντας αντ' αυτού στην ειδική περίπτωση πρόβλεψης ενός μόνο διακριτού μέσω σχεδίων παρόμοιων με το MTP που παρουσιάστηκαν στο Τεχνικό Έγγραφο DeepSeek-V3.
MTP
Αυτό το σχέδιο είναι παρόμοιο με την αποκωδικοποίηση στόχου-υποδείγματος, με εξαίρεση τις κρυφές καταστάσεις που χρησιμοποιούνται παράλληλα με διακριτά για πρόβλεψη. Πρέπει να γίνουν ελαφρώς περισσότερες εργασίες και στις δύο φάσεις προετοιμασίας και αποκωδικοποίησης σε σύγκριση με κανονική υποψία στόχου-υποδείγματος. Το υπόδειγμα χρησιμοποιεί και τα διακριτά και τις κρυφές καταστάσεις: το διακριτό t_{i+1} δειγματοληπτείται από τους λογισμούς L_i που αντιστοιχούν στο διακριτό t_i, το οποίο με τη σειρά του προκύπτει από τις κρυφές καταστάσεις H_i. Κατά συνέπεια, τα διακριτά εισαγωγής πρέπει να μετατοπιστούν ένα βήμα αριστερά σε σχέση με τους διανύσματα κρυφών καταστάσεων που εκβάλλονται από το στόχο. Η εικόνα παρακάτω σημειώνει τις αντιστοιχίες που χρησιμοποιούνται για εκπαίδευση, καθώς και τη μετατόπιση κατά την εκτίμηση.
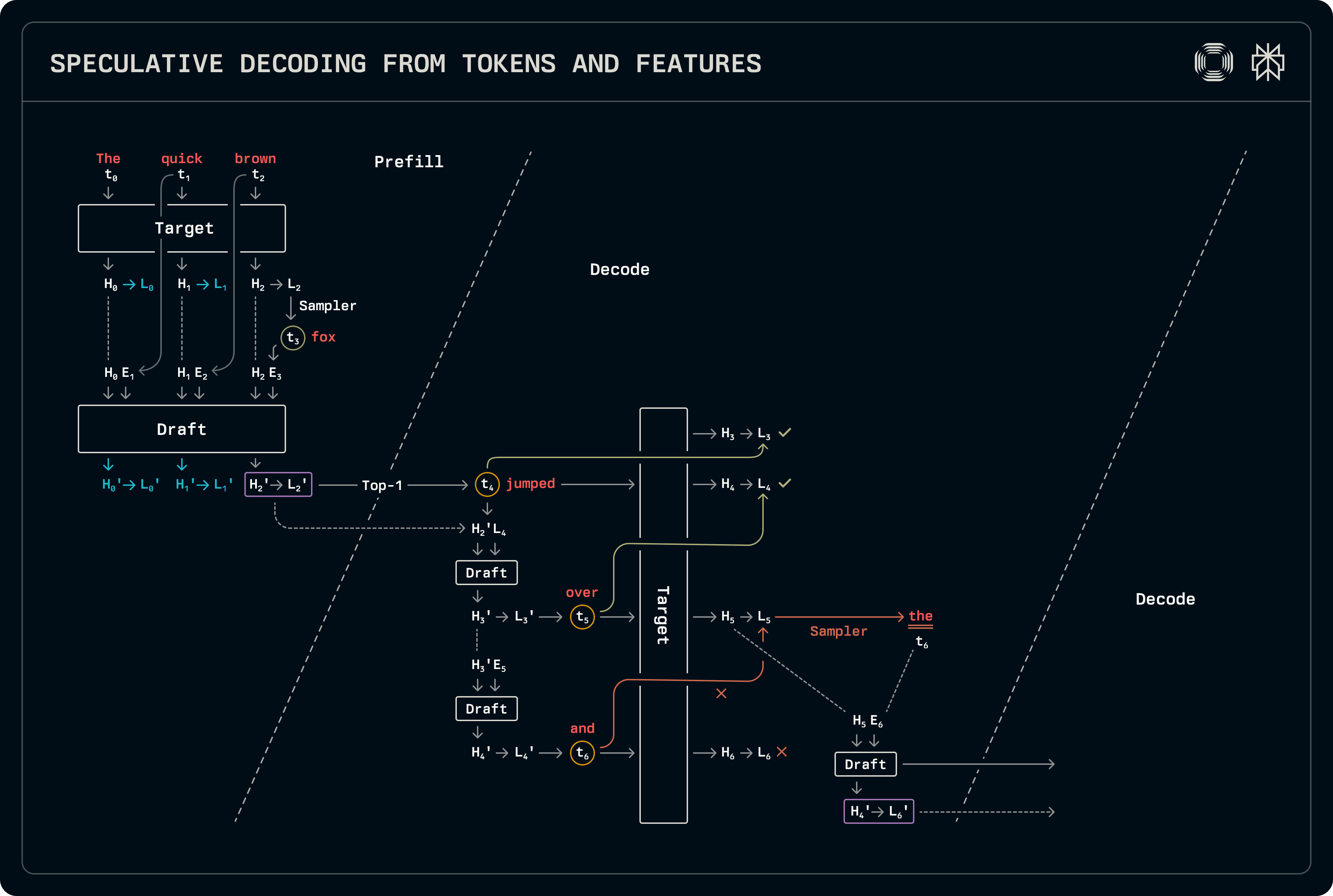
Η ροή αποκωδικοποίησης είναι παρόμοια με την αποκωδικοποίηση στόχου-υποδείγματος, με την εξαίρεση ότι και οι κρυφές καταστάσεις και οι λογισμοί μεταφέρονται. Η υλοποίησή μας μοιράζεται όλους τους σχετικούς δειγματοληπτικούς και ιδιαίτερους λογισμούς, ειδικεύοντας μόνο τις κλήσεις προόδου του μοντέλου. Όταν προβλέπονται πολλές διακριτές, το υπόδειγμα χρησιμοποιεί κρυφές καταστάσεις υποδείγματος για πρόβλεψη, γεμίζοντας επίσης τις εγγραφές KV cache βάσει των δικών του χαρακτηριστικών. Μακροπρόθεσμα, αυτό μπορεί να υποβαθμίσει την ακρίβεια. Στη συνέχεια, όταν εκτελούμε το υπόδειγμα για να γεμίσουμε την εγγραφή KV cache για την πρόβλεψη του στόχου, το εκτελούμε σε ολόκληρη την ακολουθία, λαμβάνοντας τις πιο ακριβείς κρυφές καταστάσεις του στόχου ως εισόδους. Δεδομένου ότι αυτά τα υποδείγματα είναι μικρά, το πρόσθετο κόστος επεξεργασίας των επιπλέον διακριτών είναι αμελητέο.
Εκπαίδευση Κεφαλιών MTP
Για να επωφεληθούμε από το MTP, δημιουργήσαμε την υποδομή που απαιτείται για να εκπαιδεύσουμε τα κεφάλια MTP που συνδέονται με τα τελειοποιημένα μοντέλα μας στα σύνολα δεδομένων του Perplexity, εκτελώντας σε έναν κόμβο με 8xH100 συσκευές. Σε περίπου μία ημέρα, μπορούμε να κατασκευάσουμε κεφάλια για μοντέλα που κυμαίνονται από το Llama-1B έως το Llama-70B και το DeepSeek V2-Lite. Για μεγαλύτερα μοντέλα, βασιζόμαστε σε κεφάλια MTP που κατασκευάστηκαν κατά τη διάρκεια της διαδικασίας επιμόρφωσης.
Ο στόχος της εκπαίδευσης MTP είναι να ταιριάξει τις κρυφές καταστάσεις και τους λογισμούς των υποδειγμάτων με τους λογισμούς διακριτών και τις κρυφές καταστάσεις του στόχου. Δεδομένου ότι η εκτίμηση για τις κρυφές καταστάσεις είναι δαπανηρή, τις προεξοφλούμε χρησιμοποιώντας την εκτίμηση του μοντέλου στόχου που είναι βελτιστοποιημένη για εκτίμηση, για να χρησιμοποιηθεί κατά την εκπαίδευση. Ωστόσο, για να επαληθεύσουμε την υλοποίηση MTP εκτίμησης και να διασφαλίσουμε ότι οι αριθμητικές διαφορές λόγω ποσοτικής ή βελτιστοποιήσεων δεν εμποδίζουν τα αποτελέσματα, για την εκτίμηση απώλειας επαλήθευσης και ακρίβειας, επαναχρησιμοποιούμε πλήρως την υλοποίηση εκτίμησης και των δύο μοντέλων στόχου και υποδείγματος.
Κατά την κλίμακα από το σύνολο δεδομένων ShareGPT που χρησιμοποιήθηκε στο αρχικό έγγραφο σε μεγαλύτερα δείγματα, παρατηρήσαμε ότι η αρχιτεκτονική κεφαλών MTP που περιγράφεται και υλοποιείται στο έγγραφο EAGLE απέτυχε να εκπαιδευτεί για μοντέλα μεγέθους 70B. Σε αντίθεση με το ShareGPT που περιείχε μεγαλύτερο αριθμό μικρότερων ακολουθιών, εκπαιδεύουμε σε ένα ελαφρώς μικρότερο αριθμό ουσιαστικά πιο μακρών υπονοούμενων. Δεδομένου ότι οι αρχικές κεφαλές EAGLE παρήγαγαν ελαφρώς διαφοροποιημένη δομή από έναν τυπικό μεταμορφωτή, επαναφέρουμε κάποιες στρώσεις RMS Κανονικοποίησης που είχαν αφαιρεθεί. Διαπιστώσαμε ότι αυτό όχι μόνο επέτρεψε την εκπαίδευση να συγκλίνει, αλλά αύξησε επίσης την ακρίβεια των κεφαλών κατά μερικές ποσοστιαίες μονάδες.

Όχι μόνο οι κανονισμοί στρώσεων διευκολύνουν την εκπαίδευση, η επαναφορά των κανονισμών είναι επίσης μαθηματικά ενσυναισθητική. Οι κεφάλες MTP επαναχρησιμοποιούν τις ενσωματώσεις και τις προβολές λογισμών του μοντέλου στόχου, καθώς μπορεί να είναι σημαντικού μεγέθους (περίπου 2 GB για το Llama 70B). Κατά την εκπαίδευση, αυτά παγώνουν και η προσδοκία είναι ότι το στρώμα MTP μαθαίνει να ενσωματώνει τις προβλέψεις στον ίδιο χώρο διανυσμάτων όπως αυτό που το στρώμα προβολής του αρχικού μοντέλου έμαθε κατά την εκπαίδευση. Με την απόρριψη των κανονισμών, αναμένεται ότι ένα μόνο MLP θα μάθει την ίδια συνάρτηση με ένα MLP που ακολουθείται από έναν κανονισμό, γεγονός που εμποδίζει την αντιστοίχιση μεταξύ των κρυφών καταστάσεων των υποδειγμάτων και του μοντέλου στόχου.
Εκτίμηση με Υποψιασμένη Αποκωδικοποίηση
Στον κινητήρα εκτίμησης, για να παραχθούν διακριτά για τις εισαγωγικές ακολουθίες, πρέπει πρώτα να ομαδοποιηθούν σε λογικά μεγέθη batches, στη συνέχεια θα πρέπει να παραχωρηθούν σελίδες στην κάρτα KV για τα επόμενα διακριτά. Οι εισαγωγικές διακριτές και οι πληροφορίες σελίδας KV στη συνέχεια συσκευάζονται σε έναν buffer που εκπέμπεται σε όλους τους παράλληλους βαθμούς που εκτελούν το μοντέλο. Τελικά, τα μεταδεδομένα αντιγράφονται στη μνήμη GPU και το μοντέλο εκτελείται για να παραγάγει τους λογισμούς από τους οποίους δειγματοληπτείται το επόμενο διακριτό.
Σε αντίθεση με ορισμένες υλοποιήσεις που διασυνδέουν χαλαρά έναν υποδείγμα και έναν στόχο μέσω ενός wrapper που οργανώνει τα αιτήματα μεταξύ τους, τα ζεύγη στόχου-υποδείγματός μας είναι στενά συνδεδεμένα και προχωρούν βήμα-βήμα στην παραγωγή. Το προγραμματισμό batch και η παραχώρηση σελίδας KV είναι κοινά μεταξύ των μοντέλων για όλες τις μορφές υποψιασμένης αποκωδικοποίησης: αυτό ενοποιεί την λογική που γεφυρώνει ένα μοντέλο με τον υπερκείμενο κινητήρα εκτίμησης, καθώς όλα εκθέτουν την ίδια διεπαφή.
Ο χρόνος εκτίμησης στο Perplexity είναι διαμορφωμένος γύρω από το FlashInfer, το οποίο προσδιορίζει τα μεταδεδομένα που πρέπει να κατασκευαστούν για να ρυθμίσουν και να προγραμματίσουν τον πυρήνα προσοχής. Δεδομένων ορισμένων εισαγωγικών ακολουθιών που σχηματίζουν ένα batch, για προετοιμασία, αποκωδικοποίηση ή επαλήθευση, πρέπει να γίνει εργασία πλευράς CPU για την παραχώρηση ενδιάμεσων buffers και την γέμιση ορισμένων σταθερών buffers που χρησιμοποιούνται στην προσοχή. Αυτή η εργασία προστίθεται στο κόστος του προγραμματισμού batch και της παραχώρησης σελίδας KV, που επίσης επιφέρουν καθυστερήσεις που πρέπει να κρυφτούν για να μεγιστοποιήσουν τη χρησιμοποίηση της GPU.
Ενώ έχουμε πλήρως παραλληλοποιήσει την εργασία πλευράς CPU και GPU για εκτίμηση χωρίς υποψία, διαπιστώσαμε ότι η ισορροπία CPU-GPU για υποψία αποκωδικοποίησης είναι πιο περίπλοκη. Η κύρια πρόκληση προκύπτει από το γεγονός ότι ο αριθμός των αποδεκτών διακριτών προσδιορίζει τη διάρκεια ακολουθίας για μια επόμενη εκτέλεση, εισάγοντας ένα δύσκολο να αποφευχθεί σημείο συγχρονισμού GPU προς CPU. Πειραματιστήκαμε με διάφορα σχέδια προγραμματισμού προκειμένου να αποκρύψουμε καλύτερα την καθυστέρηση της εργασίας CPU.
Προγραμματισμός Στόχου-Υποδείγματος
Παρά το γεγονός ότι είναι μικρότερο από ένα μοντέλο στόχου, όταν ένα ολόκληρο LLM χρησιμοποιείται ως το υπόδειγμα, εξακολουθεί να εισάγει σημαντική καθυστέρηση στην GPU, παρέχοντας κάποια απόσταση για να αποκρύψει δαπανηρές λειτουργίες CPU. Δεδομένου ότι τα μικρότερα μοντέλα δεν επωφελούνται από την παράλληλη τάνυση, υπάρχει μια ασυμβατότητα μεταξύ του αριθμού των βαθμών που είναι κατακερματισμένα σε έναν στόχο και ένα υπόδειγμα. Στην υλοποίησή μας, το υπόδειγμα μοντέλο εκτελείται μόνο στον ηγέτη βαθμό μιας ομάδας TP.
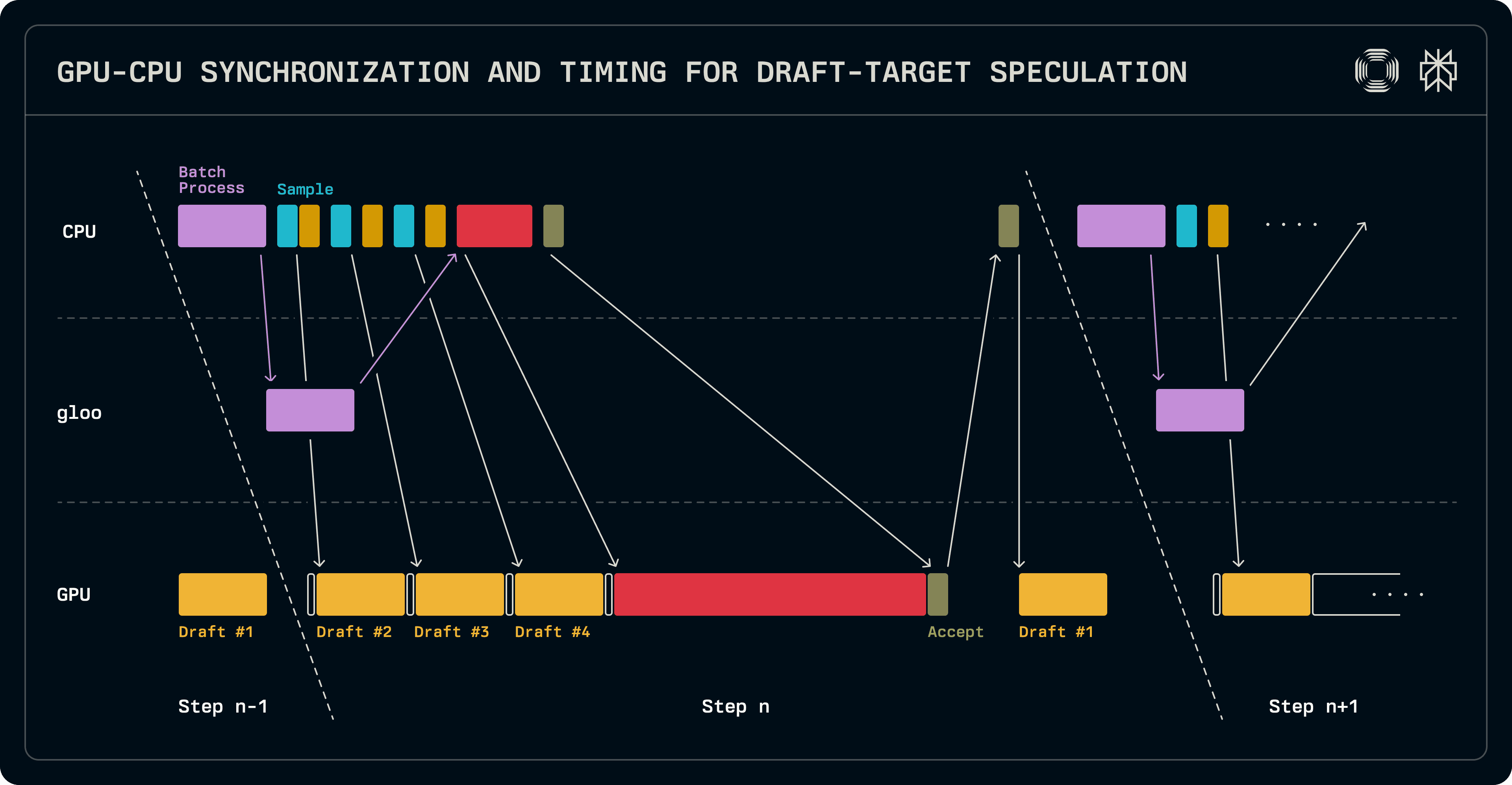
Όπως έχει αναφερθεί, ένα βήμα αποκωδικοποίησης μεταφέρει τους λογισμούς στην επόμενη εκτέλεση. Αυτό μας επιτρέπει να επικαλύψουμε μία εκτέλεση του υποδείγματος με την εργασία προγραμματισμού batch στην πλευρά CPU. Αφού το batch συγκεντρωθεί, οι επαναλαμβανόμενες κλήσεις στη δειγματολήπτη και στο υπόδειγμα παράγουν τα διακριτά του υποδείγματος. Παράλληλα, το batch για επαλήθευση συγκεντρώνεται για το μοντέλο στόχο και συγχρονίζεται με τους παράλληλους εργαζόμενους. Οι λογισμοί στόχου επαληθεύονται και δειγματοληπτούνται για να προσδιορίσουν τις αποδεκτές διάρκειες ακολουθίας. Σε αυτό το σημείο, είναι απαραίτητο το συγχρονισμό GPU προς CPU προκειμένου να προσδιοριστούν οι επόμενες διάρκειες ακολουθίας. Δεδομένου ότι το υπόδειγμα εκτελείται μόνο στον ηγέτη κόμβο, το batch του διαμορφώνεται σειριακά και η εκτέλεσή του ενεργοποιείται για να γεμίσει τις εγγραφές KV cache με το επιπλέον διακριτό που παρήγαγε ο στόχος. Οι λογισμοί που παράγονται από αυτήν τη φάση του υποδείγματος στην τρέχουσα εκτέλεση θα χρησιμοποιηθούν για να δειγματοληφτούν το πρώτο διακριτό υποδείγματος στην επόμενη εκτέλεση. Πιο σημαντικό, ενώ το υπόδειγμα εκτελείται, το επόμενο batch μπορεί να προγραμματιστεί.
Προγραμματισμός MTP για Ένα Μοναδικό Διακριτό
Ενώ η υλοποίηση δεν παρέχει ακόμη εξερεύνηση δέντρων στυλ EAGLE, έχουμε εφαρμόσει μια ειδική περίπτωση αυτού του σχεδίου, εξετάζοντας μια γραμμική ακολουθία υποδειγμάτων που παράγεται από ένα μοντέλο μεγέθους ενός μοναδικού στρώματος αποκωδικοποιητή μεταμορφωτή. Αυτό το σχέδιο μπορεί να χρησιμοποιηθεί για πρόβλεψη υποδείγματος χρησιμοποιώντας τα ανοιχτά βάρη του DeepSeek R1. Η υποκατηγορία πρόβλεψης ενός μόνο διακριτού είναι ενδιαφέρουσα, καθώς τα μεγάλα στρώματα MTP επιτυγχάνουν επαρκείς υψηλές ποσοστά αποδοχής για να δικαιολογήσουν την επιβάρυνσή τους.
Ο προγραμματισμός MTP είναι κάπως πιο περίπλοκος, καθώς το μοντέλο υποδείγματος είναι πολύ ταχύτερο, αποκρύπτοντας λιγότερη καθυστέρηση στην πλευρά CPU. Επιπλέον, το υπόδειγμα είναι κατακερματισμένο μαζί με το μοντέλο στόχου, απαιτώντας κοινές μεταφορές μνήμης για πληροφορίες batch. Μια εκτέλεση αρχίζει μεταφέροντας πληροφορίες batch και δειγματοληπτώντας το πρώτο διακριτό από τους λογισμούς που μεταφέρονται, παρόμοια με το προηγούμενο σχέδιο. Στη συνέχεια, το στόχο εκτελείται για να επαληθεύσει τα διακριτά, επεξεργάζοντας 2 * D διακριτά, όπου το D είναι το μέγεθος του batch αποκωδικοποίησης. Αυτό είναι ιδανικό για μικρο-ομαδοποίηση σε μοντέλα Μείγματος-Ειδικών (MoE) μέσω αργών διασυνδέσεων όπως το InfiniBand, καθώς το batch διασπάται ομοιόμορφα σε δύο μισά. Οι κρυφές καταστάσεις του στόχου μεταφέρονται στην επόμενη εκτέλεση του υποδείγματος, ενώ οι λογισμοί παραδίδονται στη δειγματολήπτη για επαλήθευση.

Με την εκτέλεση περιορισμένης πρόσθετης εργασίας στην GPU, αποφεύγουμε τον συγχρονισμό CPU προς GPU μετά την αποδοχή της ακολουθίας υποδείγματος. Αφού οι εισαγωγικές διακριτές των στόχων μετατοπιστούν, μια λογική ενσωματώνει τα επόμενα διακριτά στόχου στις αντίστοιχες θέσεις τους. Το υπόδειγμα εκτελείται ξανά με την ίδια την πληροφορία batch όπως το στόχο, γεμίζοντας τις εγγραφές KV cache και δημιουργώντας τους λογισμούς και τις κρυφές καταστάσεις για την επόμενη εκτέλεση, κάνοντας κάποια επαναλαμβανόμενη εργασία σε διακριτά που δεν έγιναν αποδεκτά. Σε αυτές τις περιπτώσεις, η καθυστέρηση της μη χρήσιμης εργασίας είναι ελάχιστη λόγω του μικρού μεγέθους του υποδείγματος. Παράλληλα με την εκτέλεση του υποδείγματος, οι διάρκειες ακολουθίας προσδιορίζονται στην πλευρά CPU και αρχίζει το προγραμματισμό του επόμενου batch, χωρίς να χρειάζεται να περιμένουμε για την ολοκλήρωση της εργασίας της GPU.
Η επιβάρυνση της επιπλέον εργασίας στο στρώμα υποδείγματος δεν είναι αισθητή στην προσοχή, ωστόσο, τα στρώματα MLP είναι πιο προβληματικά. Δεδομένου ότι οι οδηγίες πολλαπλασιασμού μήτρας προσαρμόζονται σε ένα όριο 64 κατά μήκος της διάστασης του αριθμού των διακριτών, αν η διπλασία δεν απαιτεί σημαντικά περισσότερα μπλοκ, η επιβάρυνση αποκρύπτεται. Για μεγαλύτερες υποδειγματικές ακολουθίες, η επιβάρυνση είναι πιο δαπανηρή και το σχέδιο που χρησιμοποιείται για τα κανονικά μοντέλα στόχου-υποδείγματος λειτουργεί καλύτερα.
Αναφορές
Γρήγορη Εκτίμηση από Μετασχηματιστές μέσω Υποψιασμένης Αποκωδικοποίησης
EAGLE: Η Υποψιασμένη Δειγματοληψία Απαιτεί Επανεξέταση της Αβεβαιότητας Χαρακτηριστικών
EAGLE-2: Ταχύτερη Εκτίμηση Γλωσσικών Μοντέλων με Δυναμικά Δέντρα Υποδείγματος
Medusa: Απλό Πλαίσιο Επιτάχυνσης Εκτίμησης LLM με Πολλαπλούς Αποκωδικοποιητές
FlashInfer: Αποτελεσματικός και Προσαρμόσιμος Μηχανισμός Προσοχής για Υπηρεσία Εκτίμησης LLM