

Γραμμένο από
Ομάδα Perplexity
Δημοσιεύτηκε την
Search API: Βελτιωμένη εξαγωγή, δυναμικά benchmarks
Τον Σεπτέμβριο, δημοσιεύσαμε μια τεχνική επισκόπηση της αρχιτεκτονικής του Perplexity Search API και διαθέσαμε το search_evals, το framework αξιολόγησης ανοιχτού κώδικα που αναπτύξαμε για τη συγκριτική αξιολόγηση search APIs σε ροές εργασίας με agents. Έκτοτε, η σημαντικότερη επένδυση έχει γίνει στην ποιότητα των snippets, βελτιστοποιημένη κατά μήκος δύο διαστάσεων: της συνάφειας και του μεγέθους. Η επιστροφή του κατάλληλου περιεχομένου στη σωστή ποσότητα καθορίζει άμεσα την ακρίβεια των απαντήσεων στα επόμενα στάδια και την αποδοτικότητα των tokens. Η εργασία για να φτάσουμε εκεί περιλάμβανε την ανάπτυξη νέων συστημάτων για εξαγωγή, επισήμανση σε επίπεδο span και αξιολόγηση, κυρίως ενός pipeline επισήμανσης spans που εντοπίζει ποια τμήματα ενός εγγράφου προέλευσης ανταποκρίνονται σε ένα δεδομένο query.
Αξιολόγηση των snippets σε επίπεδο span
Για να βελτιώσουμε συστηματικά τα snippets, αναπτύξαμε ένα νέο σύστημα αξιολόγησης. Για ένα δεδομένο query και έγγραφο, το σύστημα εντοπίζει και επισημαίνει spans εντός του εγγράφου ανάλογα με τη σχέση τους με το query: "ζωτικής σημασίας" spans που πρέπει να περιλαμβάνονται στο snippet, διάφορες κατηγορίες "μη σχετικών" spans που πρέπει να αποκλείονται, διπλότυπα και άλλες κατηγορίες. Αυτή η επισήμανση σε επίπεδο span μάς επιτρέπει να αξιολογούμε την ποιότητα των snippets με επίπεδο ακρίβειας που δεν ήταν προηγουμένως δυνατό, μετρώντας τόσο τι συμπεριλήφθηκε ορθά όσο και τι παραλείφθηκε ορθά.
Στην πράξη, αυτές οι βελτιώσεις μάς επιτρέπουν να δημιουργούμε μικρότερα snippets που είναι περισσότερο συναφή με το query. Το self-improving pipeline κατανόησης περιεχομένου μας χειρίζεται πλέον ένα ευρύτερο φάσμα μορφότυπων δομημένων δεδομένων, συμπεριλαμβανομένων πινάκων, εμφωλευμένων λιστών και δυναμικά αποδιδόμενου περιεχομένου, το οποίο τα παλαιότερα σύνολα κανόνων αδυνατούσαν να αναλύσουν με αξιοπιστία.
Αυτές οι βελτιώσεις προέκυψαν από τα δικά μας production systems. Καθώς η εσωτερική μας έρευνα προωθούσε τη συνάφεια και το μέγεθος των snippets, οι εσωτερικές αξιολογήσεις αποκάλυψαν ότι οι μικρότεροι προϋπολογισμοί περιεχομένου παρήγαγαν στην πράξη ακριβέστερα αποτελέσματα έπειτα από μια σειρά βελτιώσεων ποιότητας. Πραγματοποιήσαμε ορισμένες τροποποιήσεις στις προεπιλεγμένες διαμορφώσεις μας ώστε να αντικατοπτρίζουν τα ευρήματά μας, μειώνοντας το μέγεθος του payload των αποκρίσεων και την καθυστέρηση, ενώ ταυτόχρονα παρέχουμε χρησιμότερο περιεχόμενο ανά αποτέλεσμα. Για τους προγραμματιστές, τα μικρότερα και περισσότερο συναφή snippets μεταφράζονται άμεσα σε χαμηλότερο κόστος tokens και καλύτερη διαχείριση context για τα downstream LLMs.
SEAL: συγκριτική αξιολόγηση χρονικά ευαίσθητης ανάκτησης
Το benchmark SEAL ελέγχει εάν ένα σύστημα ανάκτησης μπορεί να απαντά σε ερωτήσεις των οποίων η σωστή απάντηση μεταβάλλεται με την πάροδο του χρόνου. Η αξιόπιστη απάντηση απαιτεί φρεσκάδα index σε πραγματικό χρόνο, εξυπνότερη εξαγωγή snippets από διάφορες πηγές δεδομένων που ενημερώνονται συνεχώς και parsing που μπορεί να εντοπίζει την τρέχουσα τιμή και όχι μια ιστορική.
Όταν εκτελέσαμε το search_evals έναντι της έκδοσης SEAL της 22ας Φεβρουαρίου χρησιμοποιώντας Claude Sonnet 4.5, οι βαθμολογίες του Perplexity αυξήθηκαν, ενώ άλλοι πάροχοι υποχώρησαν στο SEAL-Hard:
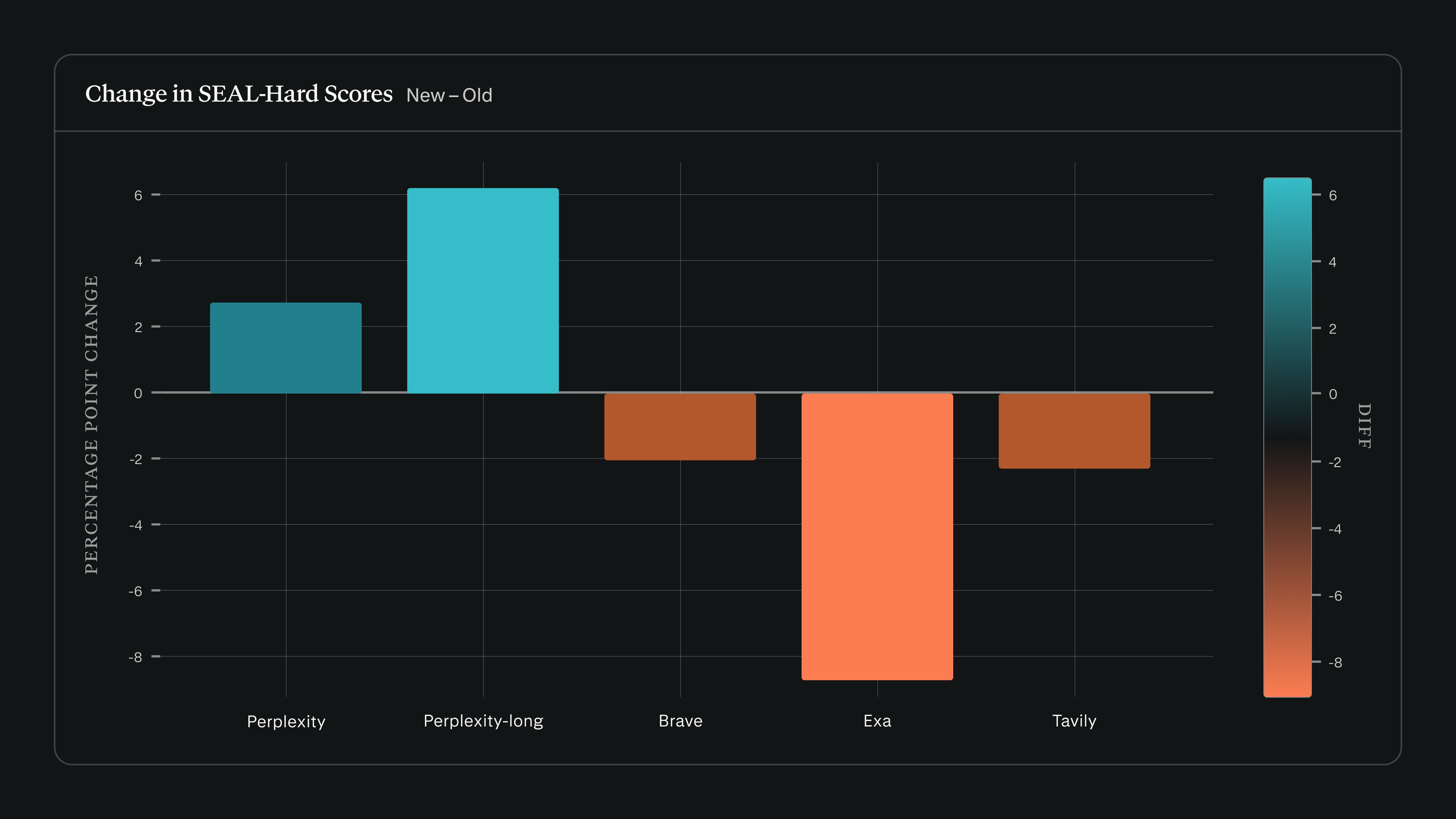
Έχουμε επεκτείνει το framework search_evals ώστε να περιλαμβάνει το SEAL, παράλληλα με τα benchmarks που αναφέρθηκαν στην ανάρτησή μας του Σεπτεμβρίου. Τα ενημερωμένα αποτελέσματα και η μεθοδολογία είναι διαθέσιμα στο ενημερωμένο repository στο GitHub.
Υποστήριξη πολλαπλών queries
Το API υποστηρίζει πλέον έως 5 queries σε ένα μόνο αίτημα. Τα αποτελέσματα επιστρέφονται ομαδοποιημένα ανά query με την ίδια σειρά με την οποία υποβλήθηκαν. Αυτό μειώνει τα round trips για εφαρμογές που πρέπει να εκτελούν παράλληλα σχετικές αναζητήσεις, όπως agents που αποσυνθέτουν ένα σύνθετο ερώτημα σε πολλαπλά υποκαθήκοντα ανάκτησης.
Επεκταμένο φιλτράρισμα
Εκτός από το φιλτράρισμα domain (allowlist και denylist, έως 20 domains) και το φιλτράρισμα χρονικής επικαιρότητας, το API υποστηρίζει πλέον φιλτράρισμα γλώσσας βάσει κωδικού ISO 639-1 και περιφερειακή αναζήτηση βάσει κωδικού χώρας ISO. Αυτά μπορούν να συνδυαστούν για ακριβή οριοθέτηση των αποτελεσμάτων, για παράδειγμα περιορίζοντας τα σε αποτελέσματα στην αγγλική γλώσσα από γερμανικά domains.
SDK και διαθεσιμότητα
Το Python SDK (pip install perplexityai) παρέχει πλέον εγγενή υποστήριξη για το Search API παράλληλα με τα Agent API και Sonar API.
Η πλήρης τεκμηρίωση βρίσκεται στο docs.perplexity.ai
Search API: Βελτιωμένη εξαγωγή, δυναμικά benchmarks
Τον Σεπτέμβριο, δημοσιεύσαμε μια τεχνική επισκόπηση της αρχιτεκτονικής του Perplexity Search API και διαθέσαμε το search_evals, το framework αξιολόγησης ανοιχτού κώδικα που αναπτύξαμε για τη συγκριτική αξιολόγηση search APIs σε ροές εργασίας με agents. Έκτοτε, η σημαντικότερη επένδυση έχει γίνει στην ποιότητα των snippets, βελτιστοποιημένη κατά μήκος δύο διαστάσεων: της συνάφειας και του μεγέθους. Η επιστροφή του κατάλληλου περιεχομένου στη σωστή ποσότητα καθορίζει άμεσα την ακρίβεια των απαντήσεων στα επόμενα στάδια και την αποδοτικότητα των tokens. Η εργασία για να φτάσουμε εκεί περιλάμβανε την ανάπτυξη νέων συστημάτων για εξαγωγή, επισήμανση σε επίπεδο span και αξιολόγηση, κυρίως ενός pipeline επισήμανσης spans που εντοπίζει ποια τμήματα ενός εγγράφου προέλευσης ανταποκρίνονται σε ένα δεδομένο query.
Αξιολόγηση των snippets σε επίπεδο span
Για να βελτιώσουμε συστηματικά τα snippets, αναπτύξαμε ένα νέο σύστημα αξιολόγησης. Για ένα δεδομένο query και έγγραφο, το σύστημα εντοπίζει και επισημαίνει spans εντός του εγγράφου ανάλογα με τη σχέση τους με το query: "ζωτικής σημασίας" spans που πρέπει να περιλαμβάνονται στο snippet, διάφορες κατηγορίες "μη σχετικών" spans που πρέπει να αποκλείονται, διπλότυπα και άλλες κατηγορίες. Αυτή η επισήμανση σε επίπεδο span μάς επιτρέπει να αξιολογούμε την ποιότητα των snippets με επίπεδο ακρίβειας που δεν ήταν προηγουμένως δυνατό, μετρώντας τόσο τι συμπεριλήφθηκε ορθά όσο και τι παραλείφθηκε ορθά.
Στην πράξη, αυτές οι βελτιώσεις μάς επιτρέπουν να δημιουργούμε μικρότερα snippets που είναι περισσότερο συναφή με το query. Το self-improving pipeline κατανόησης περιεχομένου μας χειρίζεται πλέον ένα ευρύτερο φάσμα μορφότυπων δομημένων δεδομένων, συμπεριλαμβανομένων πινάκων, εμφωλευμένων λιστών και δυναμικά αποδιδόμενου περιεχομένου, το οποίο τα παλαιότερα σύνολα κανόνων αδυνατούσαν να αναλύσουν με αξιοπιστία.
Αυτές οι βελτιώσεις προέκυψαν από τα δικά μας production systems. Καθώς η εσωτερική μας έρευνα προωθούσε τη συνάφεια και το μέγεθος των snippets, οι εσωτερικές αξιολογήσεις αποκάλυψαν ότι οι μικρότεροι προϋπολογισμοί περιεχομένου παρήγαγαν στην πράξη ακριβέστερα αποτελέσματα έπειτα από μια σειρά βελτιώσεων ποιότητας. Πραγματοποιήσαμε ορισμένες τροποποιήσεις στις προεπιλεγμένες διαμορφώσεις μας ώστε να αντικατοπτρίζουν τα ευρήματά μας, μειώνοντας το μέγεθος του payload των αποκρίσεων και την καθυστέρηση, ενώ ταυτόχρονα παρέχουμε χρησιμότερο περιεχόμενο ανά αποτέλεσμα. Για τους προγραμματιστές, τα μικρότερα και περισσότερο συναφή snippets μεταφράζονται άμεσα σε χαμηλότερο κόστος tokens και καλύτερη διαχείριση context για τα downstream LLMs.
SEAL: συγκριτική αξιολόγηση χρονικά ευαίσθητης ανάκτησης
Το benchmark SEAL ελέγχει εάν ένα σύστημα ανάκτησης μπορεί να απαντά σε ερωτήσεις των οποίων η σωστή απάντηση μεταβάλλεται με την πάροδο του χρόνου. Η αξιόπιστη απάντηση απαιτεί φρεσκάδα index σε πραγματικό χρόνο, εξυπνότερη εξαγωγή snippets από διάφορες πηγές δεδομένων που ενημερώνονται συνεχώς και parsing που μπορεί να εντοπίζει την τρέχουσα τιμή και όχι μια ιστορική.
Όταν εκτελέσαμε το search_evals έναντι της έκδοσης SEAL της 22ας Φεβρουαρίου χρησιμοποιώντας Claude Sonnet 4.5, οι βαθμολογίες του Perplexity αυξήθηκαν, ενώ άλλοι πάροχοι υποχώρησαν στο SEAL-Hard:
Έχουμε επεκτείνει το framework search_evals ώστε να περιλαμβάνει το SEAL, παράλληλα με τα benchmarks που αναφέρθηκαν στην ανάρτησή μας του Σεπτεμβρίου. Τα ενημερωμένα αποτελέσματα και η μεθοδολογία είναι διαθέσιμα στο ενημερωμένο repository στο GitHub.
Υποστήριξη πολλαπλών queries
Το API υποστηρίζει πλέον έως 5 queries σε ένα μόνο αίτημα. Τα αποτελέσματα επιστρέφονται ομαδοποιημένα ανά query με την ίδια σειρά με την οποία υποβλήθηκαν. Αυτό μειώνει τα round trips για εφαρμογές που πρέπει να εκτελούν παράλληλα σχετικές αναζητήσεις, όπως agents που αποσυνθέτουν ένα σύνθετο ερώτημα σε πολλαπλά υποκαθήκοντα ανάκτησης.
Επεκταμένο φιλτράρισμα
Εκτός από το φιλτράρισμα domain (allowlist και denylist, έως 20 domains) και το φιλτράρισμα χρονικής επικαιρότητας, το API υποστηρίζει πλέον φιλτράρισμα γλώσσας βάσει κωδικού ISO 639-1 και περιφερειακή αναζήτηση βάσει κωδικού χώρας ISO. Αυτά μπορούν να συνδυαστούν για ακριβή οριοθέτηση των αποτελεσμάτων, για παράδειγμα περιορίζοντας τα σε αποτελέσματα στην αγγλική γλώσσα από γερμανικά domains.
SDK και διαθεσιμότητα
Το Python SDK (pip install perplexityai) παρέχει πλέον εγγενή υποστήριξη για το Search API παράλληλα με τα Agent API και Sonar API.
Η πλήρης τεκμηρίωση βρίσκεται στο docs.perplexity.ai
Μοιραστείτε αυτό το άρθρο