

Escrito por
Equipo de IA
Publicado en
Acelerando Sonar a través de la Especulación
La decodificación especulativa acelera la generación de Modelos de Lenguaje Grande (LLMs) al utilizar un modelo rápido y pequeño de borrador para producir candidatos de finalización que son verificados por el modelo objetivo más grande. Bajo este esquema, en lugar de que una ejecución del objetivo costoso produzca un solo token, se emiten múltiples en un solo paso. Aquí presentamos los detalles de implementación de varios tipos de decodificación especulativa, aplicados en Perplexity para reducir la latencia entre tokens en los modelos de Sonar.
Decodificación Especulativa
La Decodificación Especulativa aprovecha la estructura de los lenguajes naturales y la naturaleza auto-regresiva de los transformadores para acelerar la generación de tokens. Aunque los modelos más grandes, como Llama-70B, contienen más conocimiento que los más pequeños, como Llama-1B, en algunas tareas más simples realizan un desempeño similar. Esta superposición sugiere que ciertas secuencias son mejor generadas por modelos menos costosos, dejando problemas complejos a los más grandes. El desafío es determinar cuáles completaciones son mejores y si la generación del modelo más pequeño es de la misma calidad que la del más grande.
Afortunadamente, los LLMs son transformadores auto-regresivos: cuando se les da una secuencia de tokens, producen la distribución de probabilidad del siguiente token. Además, los logits derivados de las características intermedias asociadas con los tokens en la secuencia de entrada también indican cuán probable es que el modelo emita esos tokens exactos. Esta propiedad permite la especulación: si una secuencia de tokens es generada por uno más pequeño comenzando desde un prefijo de entrada, puede ser ejecutada a través del más grande para determinar qué tan bien se alinea con el modelo objetivo. Cada prefijo de los candidatos se califica con una probabilidad y se elige el más largo por encima de un umbral de aceptación. Como beneficio adicional, el modelo objetivo también proporciona un token subsiguiente gratis: si un modelo de borrador genera n tokens, se pueden emitir hasta n + 1 en un paso.
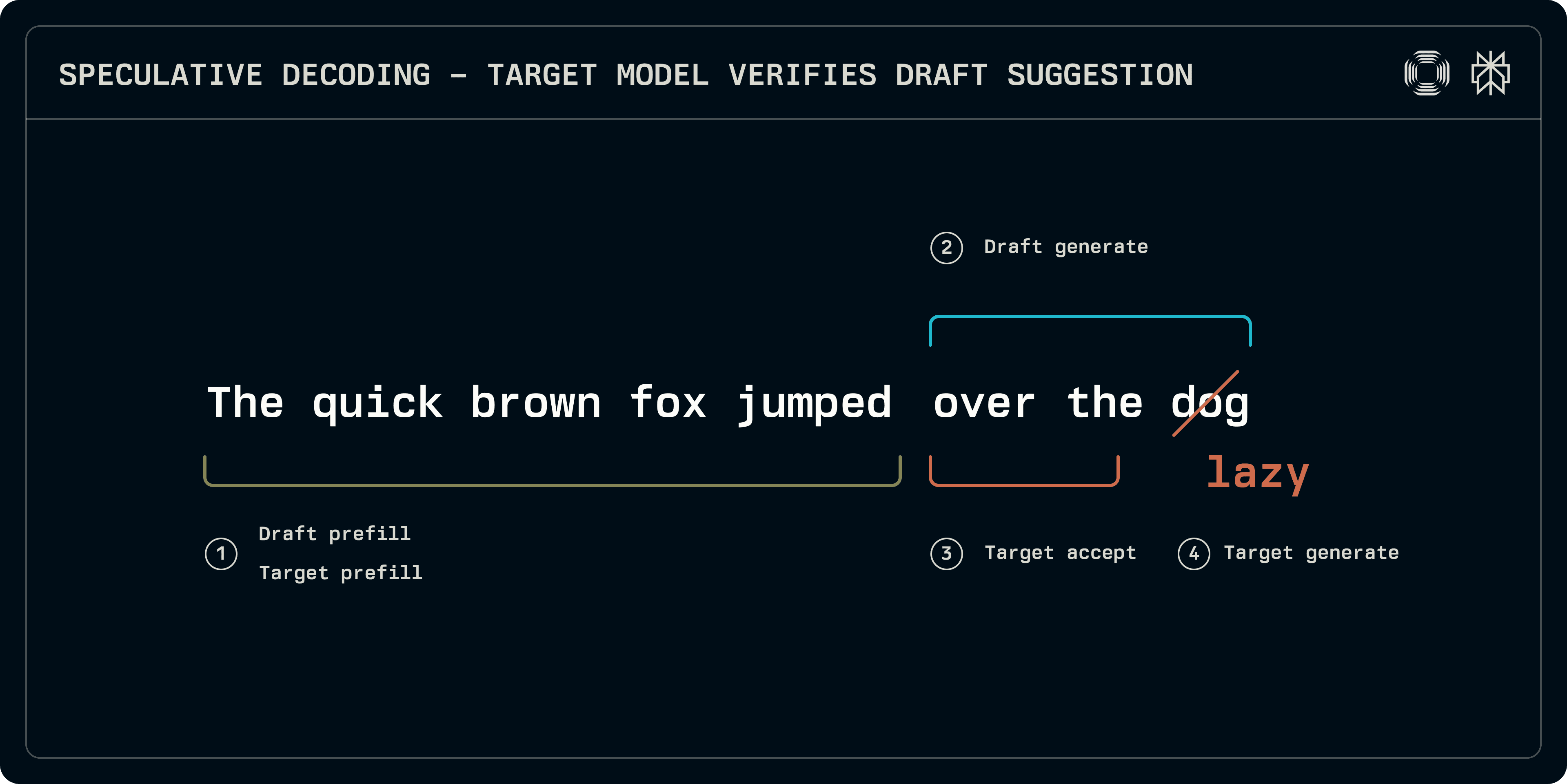
En el tiempo de inferencia, el proceso de muestreo especulativo se puede dividir en aproximadamente 4 etapas:
Prefill: tanto los modelos objetivo como de borrador deben ejecutarse en la secuencia de entrada para llenar las entradas del caché KV. Aunque algunos esquemas, como Medusa, utilizan capas densas más simples para la predicción, en esta publicación nos enfocamos en borradores basados en transformadores que necesitan sus propios cachés KV.
Generación de borrador: el modelo de borrador itera para producir un número de tokens fijos. La secuencia de borrador puede ser lineal o el modelo puede explorar una estructura en forma de árbol hasta cierta profundidad (EAGLE, Medusa). Aquí, nos centramos en secuencias lineales.
Aceptación: el modelo objetivo se ejecuta sobre la secuencia de borrador, construyendo logits correspondientes a cada token de borrador. Se determina la longitud de la secuencia aceptable más larga.
Generación objetivo: dado que el objetivo generó logits, en la posición desajustada o en el extremo final de la secuencia los logits corresponden a un token subsiguiente. Estos logits pueden ser muestreados para proporcionar un token robusto del objetivo, cerrando la secuencia.
Existen varios métodos para implementar la decodificación especulativa. En esta publicación, nos centraremos en los esquemas que utilizamos para acelerar los modelos Sonar usando un modelo interno de 1B, así como los mecanismos de predicción que estamos desarrollando para acelerar modelos a la escala de DeepSeek.
Objetivo-Borrador
La decodificación especulativa puede lograrse al acoplar un LLM pequeño existente como un modelo de borrador a un modelo objetivo para generar secuencias candidatas. En producción, hemos acelerado Sonar utilizando un modelo Llama-1B afinado en el mismo conjunto de datos que el objetivo. Si bien este enfoque no requería entrenar un borrador desde cero, el modelo pequeño aún utiliza una capacidad significativa de caché KV e introduce una ligera sobrecarga de pre-relleno, aumentando TTFT.
Bajo este esquema, el decodificador solo especula en lotes de solo decodificación, generando tokens a través del muestreo estándar durante el pre-relleno o en lotes mixtos de pre-relleno-decodificación. En la etapa de pre-relleno, los logits objetivo se muestrean inmediatamente para también prellenar el token recién generado en el caché KV del borrador. El borrador aún no se muestró, pero los logits que produce se utilizan en la etapa de decodificación.
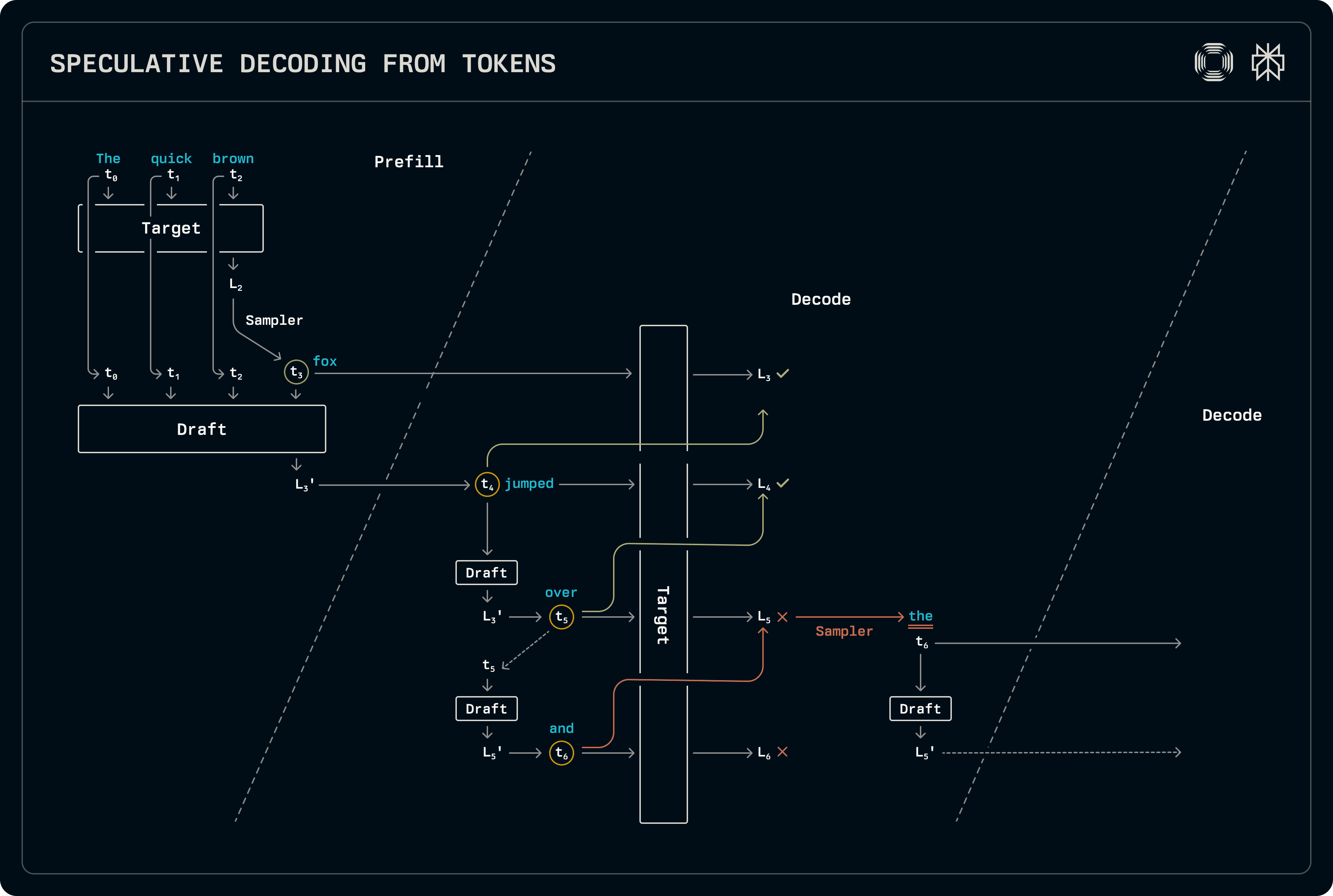
En la decodificación, el modelo de borrador avanza, muestreando el token superior en cada etapa. Después de alcanzar la longitud de borrador deseada, los tokens se ejecutan a través del modelo objetivo para producir los logits en base a los cuales el muestreador identifica la longitud de secuencia aceptada. La aceptación se determina al comparar las distribuciones de probabilidad completas desde el borrador y el objetivo. Dado que el objetivo siempre produce un conjunto de logits después de la secuencia de borrador aceptada, eso se muestra para producir una salida adicional. Como el modelo de borrador aún no ha visto ese token aceptado, se vuelve a ejecutar para llenar sus correspondientes entradas de caché KV en preparación para el siguiente paso de decodificación, llevando nuevamente los logits.
EAGLE
EAGLE es un esquema de decodificación especulativo que explora múltiples secuencias de borrador, generadas a través de un recorrido en forma de árbol de tokens de borrador probables. Se explora un árbol fijo (EAGLE) o con forma dinámica (EAGLE-2) usando ejecuciones consecutivas de los tokens de borrador, considerando los candidatos Top-K en cada nodo en lugar de seguir el token de mayor puntuación en una secuencia lineal. Luego, las secuencias se puntúan y se selecciona la más larga adecuada para continuar, también añadiendo un token adicional del objetivo.

Para lograr una predicción más precisa, un modelo de borrador EAGLE predice no solo en base a tokens, sino también usando las características objetivo (estados ocultos de la última capa) del modelo objetivo. La desventaja de EAGLE es la necesidad de entrenar modelos de borrador pequeños personalizados que sean lo suficientemente precisos como para generar candidatos adecuados dentro de un presupuesto de latencia bajo. Típicamente, un modelo de borrador es una sola capa de transformador idéntica a una capa de decodificación del modelo original, que está estrechamente acoplada al objetivo al conectar sus incrustaciones y proyecciones lm_head. Dado que esto requiere menos capacidad de caché KV, EAGLE tiene una menor huella de memoria.
Para verificar secuencias en forma de árbol en el modelo objetivo, deben usarse máscaras de atención personalizadas. Desafortunadamente, usar una máscara de atención personalizada para una secuencia completa reduce significativamente la velocidad de atención para longitudes de entrada realistas (hasta un 50%), anulando parte de la aceleración posible a través de especulación. Aún no hemos implementado la exploración completa de árboles en producción por esta razón, centrándonos en cambio en el caso especial de la predicción de un solo token a través de esquemas tipo MTP presentados en el Informe Técnico DeepSeek-V3.
MTP
Este esquema es similar a la decodificación borrador-objetivo, con la excepción de que se utilizan estados ocultos junto con tokens para la predicción. Se debe realizar un poco más de trabajo en ambas etapas de pre-relleno y decodificación en comparación con la especulación regular borrador-objetivo. El modelo de borrador utiliza tanto tokens como estados ocultos: el token t_{i+1} se muestrea de los logits L_i correspondientes al token t_i, que a su vez se derivan de los estados ocultos H_i. En consecuencia, los buffers de tokens de entrada deben desplazarse un paso a la izquierda con respecto a los vectores de estado oculto de salida del objetivo. La figura a continuación marca las correspondencias utilizadas para el entrenamiento, así como el desplazamiento durante la inferencia.
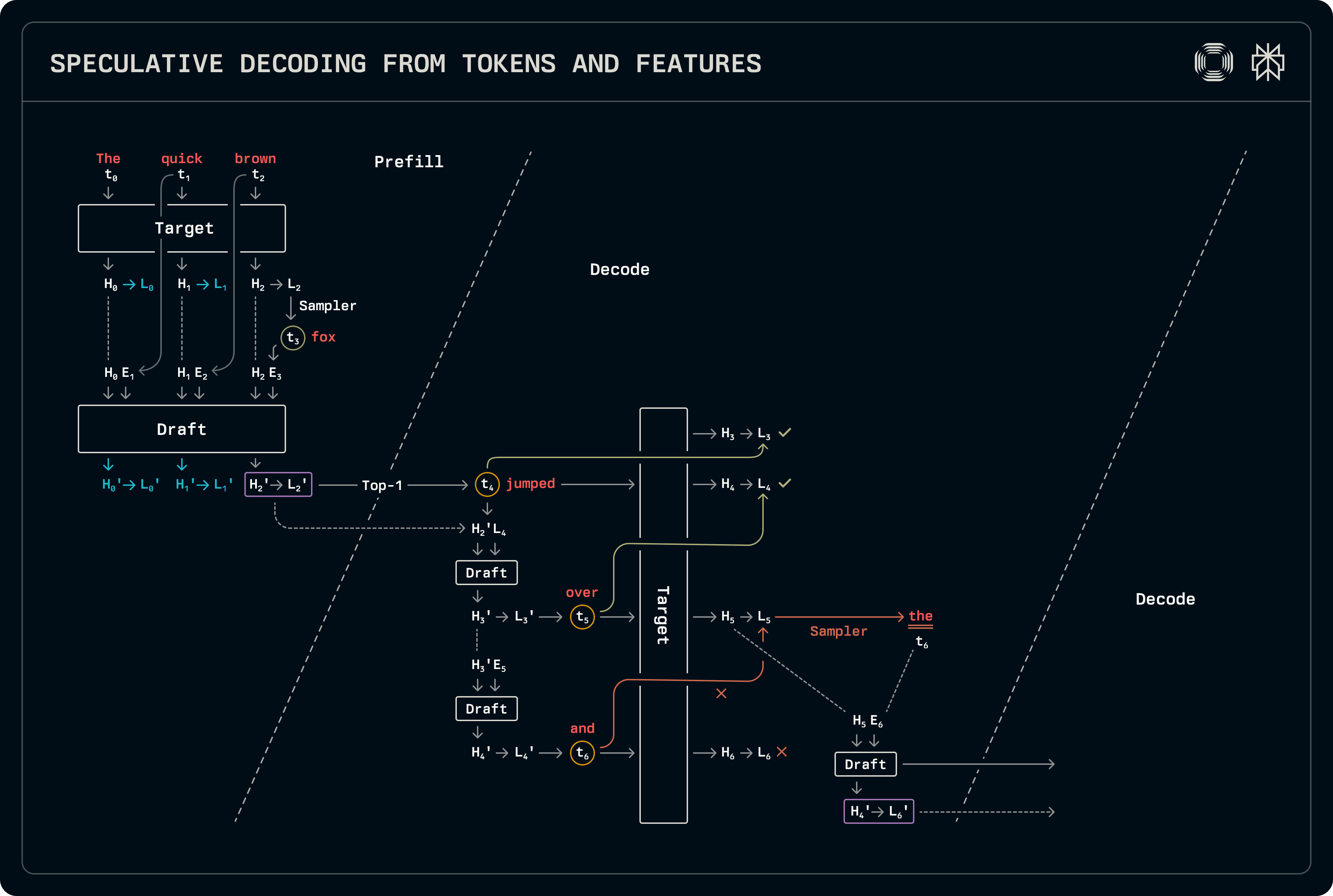
El flujo de decodificación es bastante similar al de decodificación borrador-objetivo, con la excepción de que tanto los estados ocultos como los logits se trasladan. Nuestra implementación comparte todo el muestreo asociado y los logits de procesamiento de logits, especializando solo las invocaciones de avance del modelo. Cuando se predicen múltiples tokens, el modelo de borrador utiliza estados ocultos de borrador para la predicción, también llenando las entradas de caché KV en función de sus propias características. A largo plazo, esto puede degradar la precisión. Posteriormente, al ejecutar el modelo de borrador para llenar la entrada de caché KV para la predicción objetivo, lo ejecutamos en la secuencia completa tomando los estados ocultos de objetivo más precisos como entradas. Dado que estos modelos de borrador son pequeños, el costo adicional de procesar los tokens adicionales es insignificante.
Entrenamiento de Cabezas MTP
Para beneficiarnos de MTP, construimos la infraestructura necesaria para entrenar cabezas MTP unidas a nuestros modelos afinados en los conjuntos de datos de Perplexity, ejecutándose en un nodo con 8 dispositivos H100. En aproximadamente un día, podemos construir cabezas para modelos que van desde Llama-1B hasta Llama-70B y DeepSeek V2-Lite. Para modelos más grandes, confiamos en cabezas MTP construidas durante el proceso de afinación.
El objetivo del entrenamiento MTP es alinear los estados ocultos del borrador y los logits extrapolados de los estados ocultos del objetivo a los siguientes logits y estados ocultos de token del objetivo. Dado que la inferencia para estados ocultos es costosa, los pre-computamos usando nuestra implementación optimizada para inferencia del modelo objetivo, para usarlos durante el entrenamiento. Sin embargo, para validar la implementación MTP de inferencia y asegurar que las diferencias numéricas debido a la cuantización u optimizaciones no afecten los resultados, para la pérdida de validación y estimación de precisión reutilizamos completamente la implementación de inferencia de ambos modelos, tanto del objetivo como del borrador.
Al escalar desde el conjunto de datos ShareGPT usado en el artículo original a muestras más grandes, notamos que la arquitectura de cabeza MTP descrita e implementada en el documento EAGLE falló al entrenar para modelos de tamaño 70B. A diferencia de ShareGPT, que contenía un mayor número de secuencias más cortas, entrenamos en un número ligeramente menor de secuencias sustancialmente más largas. Dado que las cabezas originales de EAGLE se desviaron ligeramente en estructura de un transformador típico, reintrodujimos algunas capas de Normalización RMS que fueron removidas. Descubrimos que esto no solo permitía que el entrenamiento convergiera, sino que también mejoraba la precisión de las cabezas en unos pocos puntos porcentuales.

No solo las normativas del nivel de capas facilitan el entrenamiento, reintroducir las normas también es matemáticamente intuitivo. Las cabezas MTP reutilizan las incrustaciones y las proyecciones de logits del modelo objetivo, ya que pueden ser sustanciales en tamaño (alrededor de 2 GB para Llama 70B). Durante el entrenamiento, estos están congelados y se espera que la capa MTP aprenda a incrustar las predicciones en el mismo espacio vectorial que la capa de proyección del modelo original aprendió durante el entrenamiento. Al omitir las normas, se espera que una sola MLP aprenda la misma función que una MLP seguida de una norma, lo que obstaculiza la correspondencia entre los estados ocultos de los modelos de borrador y objetivo.
Inferencia con Decodificación Especulativa
En el motor de inferencia, para generar tokens para secuencias de entrada, primero deben agruparse en lotes de tamaño razonable, luego deben asignarse páginas en el caché KV para los siguientes tokens. Los tokens de entrada y la información de la página KV se empaquetan en un buffer que se transmite a todos los rangos paralelos que ejecutan el modelo. Finalmente, los metadatos se copian en la memoria GPU y el modelo se ejecuta para producir los logits de los cuales se muestrea el siguiente token.
A diferencia de ciertas implementaciones que acoplan de manera suelta un servidor de inferencia de borrador y objetivo a través de un envoltorio que orquesta las solicitudes entre ellos, nuestros pares de borrador-objetivo están estrechamente acoplados y avanzan a través de la generación al unísono. La programación de lotes y la asignación de páginas KV se comparte entre los modelos para todas las formas de decodificación especulativa: esto unifica la lógica que conecta un modelo con el servidor de inferencia global, ya que todos exponen la misma interfaz.
El tiempo de ejecución de la inferencia en Perplexity está moldeado alrededor de FlashInfer, que determina los metadatos que deben construirse para configurar y programar el núcleo de atención. Dadas algunas secuencias de entrada que forman un lote, para pre-relleno, decodificación o verificación, debe realizarse trabajo en el lado del CPU para asignar buffers intermedios y llenar ciertos buffers constantes utilizados en la atención. Este trabajo es además del costo de la programación de lotes y la asignación de páginas KV, que también incurren en latencias que deben ocultarse para maximizar la utilización de la GPU.
Aunque paralelizamos completamente el trabajo del lado de la CPU y del lado de la GPU para inferencias sin especulación, encontramos que el equilibrio CPU-GPU para la decodificación especulativa es más intrincado. El principal desafío surge del hecho de que el número de tokens aceptados determina la longitud de la secuencia para una ejecución subsiguiente, introduciendo un punto de sincronización GPU-CPU difícil de evitar. Experimentamos con diferentes esquemas de programación para ocultar mejor la latencia del trabajo del CPU.
Programa de Borrador-Objetivo
A pesar de ser más pequeño que un modelo objetivo, cuando se utiliza todo un LLM como borrador, aún introduce una latencia considerable en la GPU, proporcionando algo de margen para ocultar operaciones del CPU costosas. Dado que los modelos más pequeños no se benefician del paralelismo tensorial, hay una discrepancia entre el número de rangos que un objetivo y un borrador están fragmentados. En nuestra implementación, el modelo de borrador se ejecuta solo en el rango principal de un grupo TP.
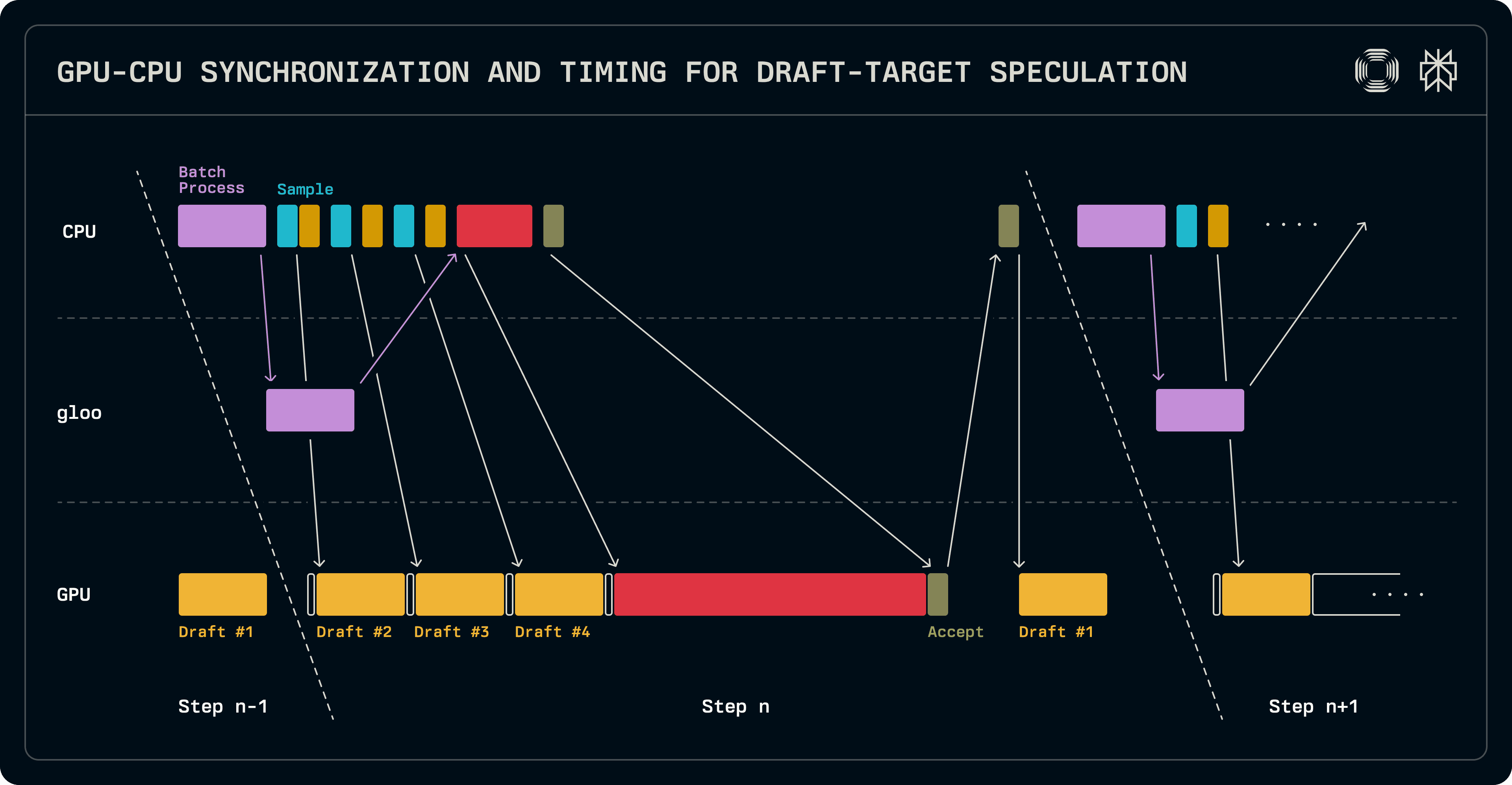
Como se indicó antes, un paso de decodificación lleva los logits a la próxima ejecución. Esto nos permite superponer una ejecución del modelo de borrador con el trabajo de programación de lotes del lado de la CPU. Después de que se arma el lote, llamadas repetidas al muestreador y al borrador producen los tokens de borrador. En paralelo, se ensambló el lote para verificación para el modelo objetivo y se sincroniza con los trabajadores paralelos. Los logits objetivo se verifican y se muestrean para determinar las longitudes de secuencia aceptadas. En este punto, es necesario sincronizar GPU-CPU para determinar las longitudes de secuencia posteriores. Dado que el modelo de borrador se ejecuta solo en el nodo principal, su lote se configura secuencialmente y su ejecución se inicia para llenar sus entradas de caché KV con el token adicional que produjo el objetivo. Los logits producidos por esta ejecución de borrador en la ejecución actual se usarán para muestrear el primer token de borrador en la ejecución subsiguiente. Lo más importante, mientras se ejecuta el borrador, se puede programar el siguiente lote.
Programa MTP para un Solo Token
Aunque el tiempo de ejecución aún no proporciona exploración de árbol de borrador estilo Eagle, implementamos un caso especial de este esquema, considerando una secuencia lineal de tokens de borrador producidos por un modelo del tamaño de una sola capa de decodificador. Este esquema puede usarse para la predicción de borrador usando los pesos de código abierto de DeepSeek R1. El sub-caso de predecir un solo token es interesante, ya que las grandes capas MTP logran tasas de aceptación lo suficientemente altas como para justificar su sobrecarga.
La programación de MTP es algo más compleja, ya que el modelo de borrador es mucho más rápido, ocultando menos latencia del lado del CPU. Además, el borrador se fragmenta junto con el modelo objetivo, requiriendo transferencias de memoria compartida para la información de lote. Una ejecución comienza transfiriendo información de lote y muestreando el primer token de los logits transportados, de manera similar al esquema anterior. Luego, se ejecuta el objetivo para validar tokens, procesando 2 * D tokens, donde D es el tamaño del lote de decodificación. Esto es ideal para micro-batching en modelos de Mezcla de Expertos (MoE) sobre interconexiones más lentas como InfiniBand, ya que el lote se divide uniformemente en dos mitades. Los estados ocultos del objetivo se trasladan a la siguiente ejecución de borrador, mientras que los logits se pasan al muestreador para verificación.

Al realizar una cantidad limitada de trabajo adicional en la GPU, evitamos la sincronización CPU-GPU después de la aceptación de la secuencia de borrador. Después de que los tokens de entrada de los objetivos se desplazaron, un kernel conecta los siguientes tokens objetivo en sus ubicaciones correspondientes. Luego, se vuelve a ejecutar el borrador con la misma información de lote que el objetivo, llenando entradas de caché KV y construyendo los logits y estados ocultos para la siguiente ejecución, haciendo un trabajo redundante en tokens que no fueron aceptados. En estas situaciones, la latencia del trabajo no utilizado es apenas medible debido al pequeño tamaño del modelo de borrador. En paralelo con la ejecución del borrador, se determinan las longitudes de secuencia en la CPU y se inicia la programación del siguiente lote, sin tener que esperar a que el trabajo en la GPU termine.
La sobrecarga del trabajo adicional en la capa de borrador no es notable en la atención, sin embargo las capas MLP son más problemáticas. Dado que las instrucciones de multiplicación de matrices rellenan hasta un límite de 64 a lo largo de la dimensión del número de tokens, si doblar no requiere significativamente más bloques, la sobrecarga se oculta. Para secuencias de borrador más largas, la sobrecarga es más costosa y el esquema utilizado para modelos borrador-objetivo regulares funciona mejor.
Referencias
Inferencia Rápida de Transformadores a través de Decodificación Especulativa
EAGLE: Muestreo Especulativo Requiere Repensar la Incertidumbre de Características
EAGLE-2: Inferencia Más Rápida de Modelos de Lenguaje con Árboles de Borrador Dinámicos
Medusa: Marco Simple de Aceleración de Inferencia LLM con Múltiples Cabezas de Decodificación
FlashInfer: Motor de Atención Eficiente y Personalizable para el Servicio de Inferencia LLM