

Escrito por
Equipo de Perplexity
Publicado en
Search API: mejor extracción, benchmarks dinámicos
En septiembre publicamos un resumen técnico de la arquitectura de Perplexity Search API y lanzamos search_evals, nuestro framework open source para evaluar APIs de búsqueda en flujos de trabajo con agentes. Desde entonces, nuestra inversión más importante ha estado en la calidad de los snippets, optimizándolos en dos frentes: relevancia y tamaño. Devolver el contenido correcto en la cantidad correcta impacta directamente la precisión de las respuestas posteriores y la eficiencia de tokens. Para lograr eso, construimos nuevos sistemas de extracción, etiquetado por fragmentos y evaluación, especialmente un pipeline de etiquetado que identifica qué partes de un documento fuente responden a una consulta dada.
Evaluación de snippets a nivel de fragmento
Para mejorar los snippets de forma sistemática, diseñamos un nuevo sistema de evaluación. Para una consulta y un documento dados, el sistema identifica y etiqueta fragmentos dentro del documento según su relación con la consulta: fragmentos "vitales" que deben incluirse en el snippet, varias clases de fragmentos "irrelevantes" que deben excluirse, duplicados y otras categorías. Este etiquetado a nivel de fragmento nos permite evaluar la calidad del snippet con una precisión que antes no era posible, midiendo tanto lo que se incluyó correctamente como lo que se omitió correctamente.
En la práctica, estas mejoras nos permiten generar snippets más pequeños y más relevantes para la consulta. Nuestro pipeline de comprensión de contenido, que mejora por sí mismo, ahora maneja una gama más amplia de formatos de datos estructurados, incluidas tablas, listas anidadas y contenido renderizado dinámicamente que los conjuntos de reglas anteriores no lograban analizar de forma confiable.
Estas mejoras surgieron de nuestros propios sistemas en producción. A medida que nuestra investigación interna mejoró la relevancia y el tamaño de los snippets, las evaluaciones internas mostraron que límites de contenido más pequeños en realidad producían resultados más precisos después de varias mejoras de calidad. Hicimos algunos ajustes a nuestras configuraciones predeterminadas para reflejar estos hallazgos, reduciendo el tamaño de la carga de respuesta y la latencia, al mismo tiempo que entregamos contenido más útil por resultado. Para los desarrolladores, snippets más pequeños y más relevantes se traducen directamente en menores costos de tokens y un mejor manejo del contexto para los LLMs posteriores.
SEAL: benchmarking de recuperación sensible al tiempo
El benchmark SEAL prueba si un sistema de recuperación puede responder preguntas cuya respuesta correcta cambia con el tiempo. Responder de forma confiable requiere índices actualizados en tiempo real, una extracción de snippets más inteligente desde varias fuentes de datos que se actualizan continuamente, y un análisis que pueda identificar el valor actual en lugar de uno histórico.
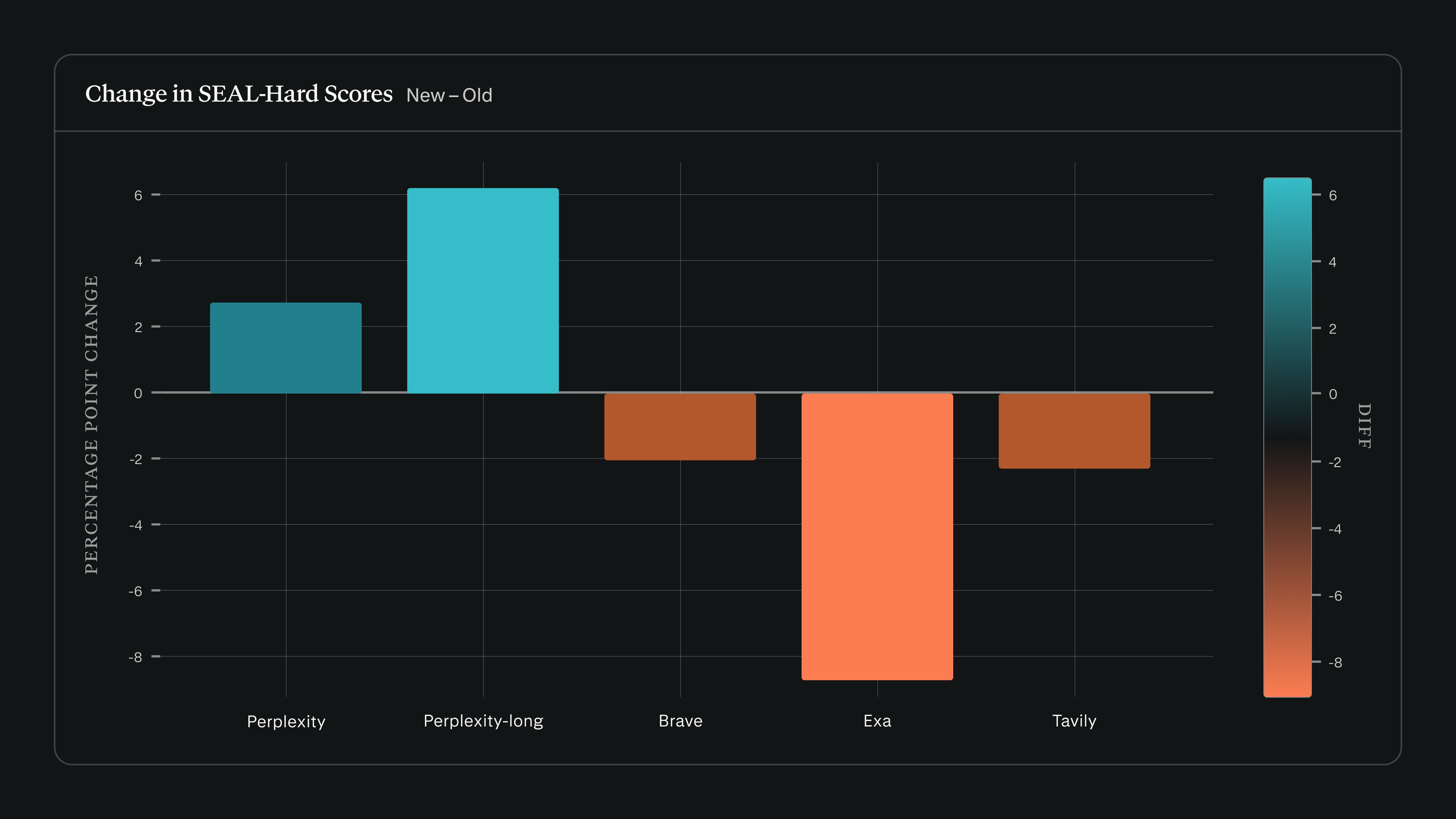
Cuando ejecutamos search_evals con la versión de SEAL del 22 de febrero usando Claude Sonnet 4.5, las puntuaciones de Perplexity subieron mientras que las de otros proveedores bajaron en SEAL-Hard:
Extendimos nuestro framework search_evals para incluir SEAL junto con los benchmarks que reportamos en nuestra publicación de septiembre. Los resultados actualizados y la metodología están disponibles en el repositorio actualizado en GitHub.
Soporte para múltiples consultas
La API ahora admite hasta 5 consultas en una sola solicitud. Los resultados se devuelven agrupados por consulta y en el mismo orden en que se enviaron. Esto reduce los viajes de ida y vuelta para aplicaciones que necesitan lanzar búsquedas relacionadas en paralelo, como agentes que descomponen una pregunta compleja en múltiples subtareas de recuperación.
Filtrado ampliado
Además del filtrado por dominio (allowlist y denylist, hasta 20 dominios) y del filtrado por recencia, la API ahora admite filtrado por idioma mediante código ISO 639-1 y búsqueda regional mediante código de país ISO. Se pueden combinar para delimitar los resultados con precisión, por ejemplo, restringiéndolos a resultados en inglés de dominios alemanes.
SDK y disponibilidad
El SDK de Python (pip install perplexityai) ahora ofrece soporte nativo para Search API junto con Agent API y Sonar API.
La documentación completa está en docs.perplexity.ai
Search API: mejor extracción, benchmarks dinámicos
En septiembre publicamos un resumen técnico de la arquitectura de Perplexity Search API y lanzamos search_evals, nuestro framework open source para evaluar APIs de búsqueda en flujos de trabajo con agentes. Desde entonces, nuestra inversión más importante ha estado en la calidad de los snippets, optimizándolos en dos frentes: relevancia y tamaño. Devolver el contenido correcto en la cantidad correcta impacta directamente la precisión de las respuestas posteriores y la eficiencia de tokens. Para lograr eso, construimos nuevos sistemas de extracción, etiquetado por fragmentos y evaluación, especialmente un pipeline de etiquetado que identifica qué partes de un documento fuente responden a una consulta dada.
Evaluación de snippets a nivel de fragmento
Para mejorar los snippets de forma sistemática, diseñamos un nuevo sistema de evaluación. Para una consulta y un documento dados, el sistema identifica y etiqueta fragmentos dentro del documento según su relación con la consulta: fragmentos "vitales" que deben incluirse en el snippet, varias clases de fragmentos "irrelevantes" que deben excluirse, duplicados y otras categorías. Este etiquetado a nivel de fragmento nos permite evaluar la calidad del snippet con una precisión que antes no era posible, midiendo tanto lo que se incluyó correctamente como lo que se omitió correctamente.
En la práctica, estas mejoras nos permiten generar snippets más pequeños y más relevantes para la consulta. Nuestro pipeline de comprensión de contenido, que mejora por sí mismo, ahora maneja una gama más amplia de formatos de datos estructurados, incluidas tablas, listas anidadas y contenido renderizado dinámicamente que los conjuntos de reglas anteriores no lograban analizar de forma confiable.
Estas mejoras surgieron de nuestros propios sistemas en producción. A medida que nuestra investigación interna mejoró la relevancia y el tamaño de los snippets, las evaluaciones internas mostraron que límites de contenido más pequeños en realidad producían resultados más precisos después de varias mejoras de calidad. Hicimos algunos ajustes a nuestras configuraciones predeterminadas para reflejar estos hallazgos, reduciendo el tamaño de la carga de respuesta y la latencia, al mismo tiempo que entregamos contenido más útil por resultado. Para los desarrolladores, snippets más pequeños y más relevantes se traducen directamente en menores costos de tokens y un mejor manejo del contexto para los LLMs posteriores.
SEAL: benchmarking de recuperación sensible al tiempo
El benchmark SEAL prueba si un sistema de recuperación puede responder preguntas cuya respuesta correcta cambia con el tiempo. Responder de forma confiable requiere índices actualizados en tiempo real, una extracción de snippets más inteligente desde varias fuentes de datos que se actualizan continuamente, y un análisis que pueda identificar el valor actual en lugar de uno histórico.
Cuando ejecutamos search_evals con la versión de SEAL del 22 de febrero usando Claude Sonnet 4.5, las puntuaciones de Perplexity subieron mientras que las de otros proveedores bajaron en SEAL-Hard:
Extendimos nuestro framework search_evals para incluir SEAL junto con los benchmarks que reportamos en nuestra publicación de septiembre. Los resultados actualizados y la metodología están disponibles en el repositorio actualizado en GitHub.
Soporte para múltiples consultas
La API ahora admite hasta 5 consultas en una sola solicitud. Los resultados se devuelven agrupados por consulta y en el mismo orden en que se enviaron. Esto reduce los viajes de ida y vuelta para aplicaciones que necesitan lanzar búsquedas relacionadas en paralelo, como agentes que descomponen una pregunta compleja en múltiples subtareas de recuperación.
Filtrado ampliado
Además del filtrado por dominio (allowlist y denylist, hasta 20 dominios) y del filtrado por recencia, la API ahora admite filtrado por idioma mediante código ISO 639-1 y búsqueda regional mediante código de país ISO. Se pueden combinar para delimitar los resultados con precisión, por ejemplo, restringiéndolos a resultados en inglés de dominios alemanes.
SDK y disponibilidad
El SDK de Python (pip install perplexityai) ahora ofrece soporte nativo para Search API junto con Agent API y Sonar API.
La documentación completa está en docs.perplexity.ai
Comparte este artículo