

Écrit par
Équipe d'IA
Publié le
Accélérer le Sonar par la Spéculation
Le décodage spéculatif accélère la vitesse de génération des modèles de langage de grande taille (LLMs) en utilisant un modèle de brouillon rapide et petit pour produire des candidats de complétion qui sont vérifiés par le modèle cible plus grand. Dans ce schéma, au lieu d'une exécution coûteuse du modèle cible produisant un seul jeton, plusieurs sont émis en une seule étape. Ici, nous présentons les détails de l'implémentation de divers types de décodage spéculatif, appliqués chez Perplexity pour réduire la latence inter-jeton sur les modèles Sonar.
Décodage Spéculatif
Le décodage spéculatif exploite la structure des langues naturelles et la nature auto-régressive des transformateurs pour accélérer la génération de jetons. Même si les modèles plus grands, comme Llama-70B, contiennent plus de connaissances que les plus petits, tels que Llama-1B, ils se comportent de manière similaire sur certaines tâches plus simples. Cette similitude suggère que certaines séquences sont mieux générées par les modèles moins coûteux, laissant les problèmes complexes aux plus grands. Le défi réside dans la détermination des complétions qui sont meilleures et si la génération du modèle plus petit est de la même qualité que celle du plus grand.
Heureusement, les LLMs sont des transformateurs auto-régressifs : lorsqu'on leur donne une séquence de jetons, ils produisent la distribution de probabilité du prochain jeton. De plus, les logits dérivés des caractéristiques intermédiaires associées aux jetons dans la séquence d'entrée indiquent également la probabilité pour le modèle d'émettre ces exacts jetons. Cette propriété permet la spéculation : si une séquence de jetons est générée par un petit modèle en partant d'un préfixe d'entrée, elle peut être passée par le modèle plus grand pour déterminer à quel point elle correspond bien au modèle cible. Chaque préfixe des candidats est noté avec une probabilité et le plus long au-dessus d'un seuil d'acceptation est choisi. En bonus, le modèle cible fournit également un jeton supplémentaire gratuitement : si un modèle de brouillon génère n jetons, jusqu'à n + 1 peuvent être émis en une étape.
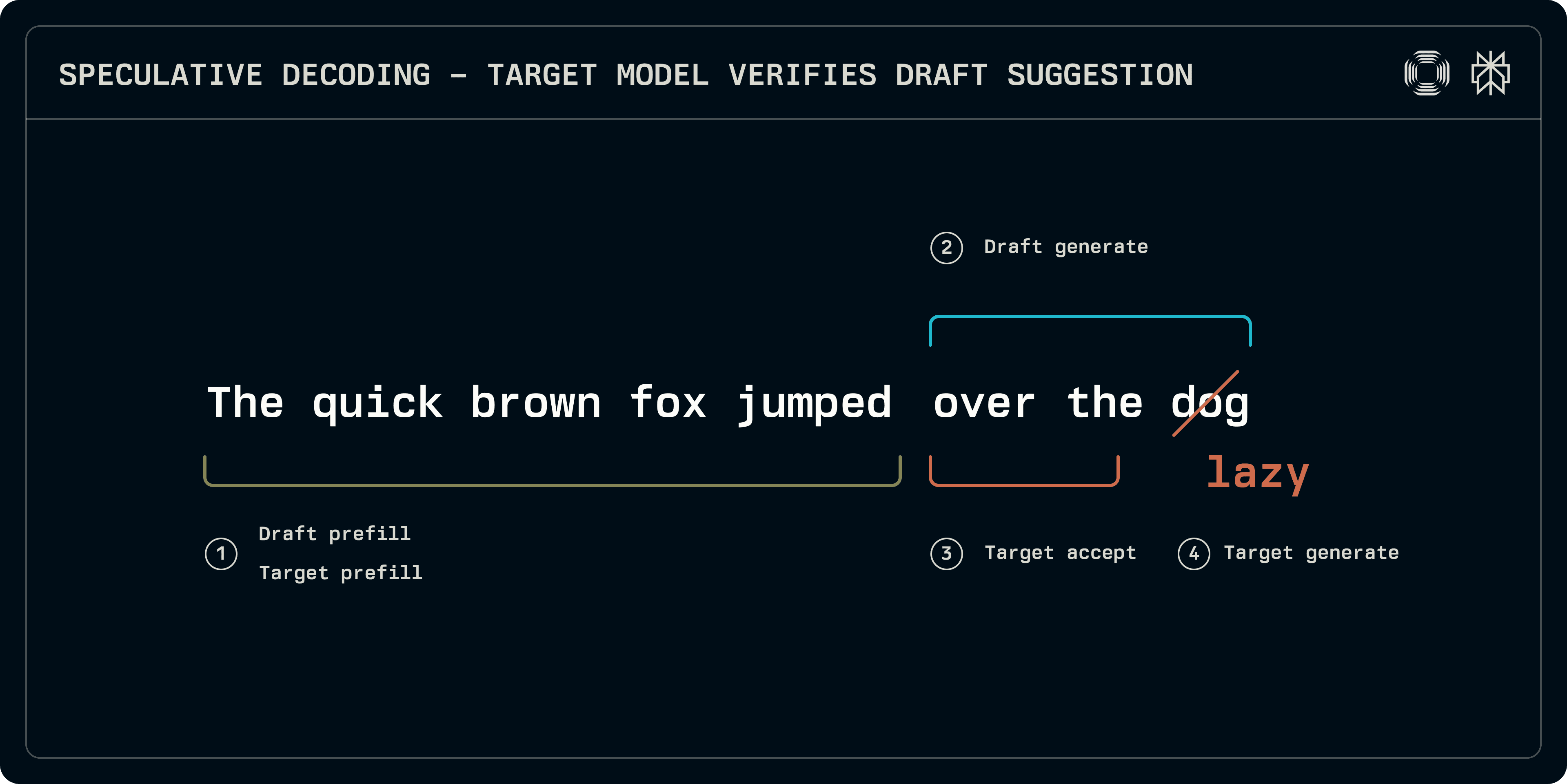
Au moment de l'inférence, le processus d'échantillonnage spéculatif peut être divisé en gros en 4 étapes :
Pré-remplissage : les modèles cible et de brouillon doivent être exécutés sur la séquence d'entrée pour remplir les entrées du cache KV. Alors que certains schémas, comme Medusa, utilisent des couches denses plus simples pour la prédiction, dans cet article nous nous concentrons sur les brouillons basés sur transformateurs qui nécessitent leurs propres caches KV.
Génération de brouillon : le modèle de brouillon itère pour produire un nombre de jetons fixes. La séquence de brouillon peut être linéaire ou le modèle peut explorer une structure en arbre jusqu'à une profondeur donnée (EAGLE, Medusa). Ici, nous nous concentrons sur les séquences linéaires.
Acceptation : le modèle cible exécute la séquence de brouillon, construisant les logits correspondant à chaque jeton de brouillon. La longueur de la séquence acceptable la plus longue est déterminée.
Génération cible : puisque le modèle cible a généré des logits, à la position décalée ou à la fin de la séquence, les logits correspondent à un jeton supplémentaire. Ces logits peuvent être échantillonnés pour fournir un jeton robuste à partir de la cible, concluant la séquence.
Différentes méthodes existent pour implémenter le décodage spéculatif. Dans cet article, nous nous concentrerons sur les schémas que nous avons utilisés pour accélérer les modèles Sonar en utilisant un modèle interne de 1B, ainsi que les mécanismes de prédiction que nous développons pour accélérer les modèles à l'échelle de DeepSeek.
Cible-Brouillon
Le décodage spéculatif peut être réalisé en couplant un LLM petit existant comme modèle de brouillon à un modèle cible pour générer des séquences candidates. En production, nous avons accéléré Sonar en utilisant un modèle Llama-1B affiné sur le même ensemble de données que la cible. Bien que cette approche n'ait pas exigé d'entraînement d'un brouillon à partir de zéro, le petit modèle utilise toujours une capacité considérable de cache KV et introduit un léger surcoût de pré-remplissage, augmentant le TTFT.
Dans ce schéma, le décodeur ne spécule que sur les lots de décodage uniquement, générant des jetons par échantillonnage standard lors du pré-remplissage ou sur des lots de pré-remplissage-mixte-décodage. Lors de l'étape de pré-remplissage, les logits de la cible sont immédiatement échantillonnés pour également pré-remplir le nouveau jeton généré dans le cache KV du brouillon. Le brouillon n'est pas encore échantillonné, mais les logits qu'il produit sont transférés à l'étape de décodage.
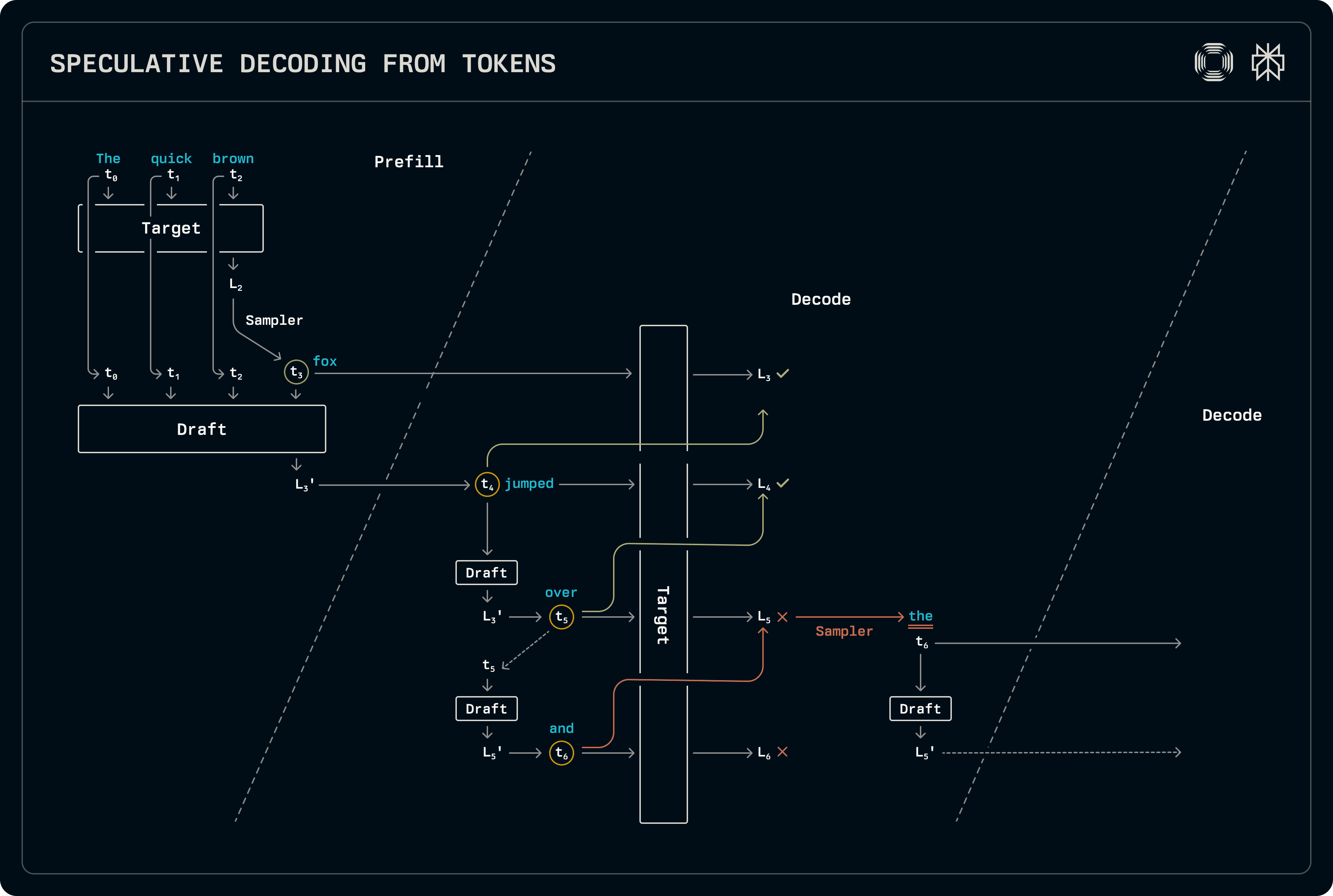
En décodage, le modèle de brouillon est avancé, échantillonnant le jeton supérieur à chaque étape. Une fois la longueur de brouillon désirée atteinte, les jetons sont passés par le modèle cible pour produire les logits sur la base desquels l'échantillonneur identifie la longueur de séquence acceptée. L'acceptation est déterminée en comparant les distributions de probabilité complètes du brouillon et de la cible. Puisque la cible produit toujours un ensemble de logits suivant la séquence de brouillon acceptée, celui-ci est échantillonné pour produire une sortie supplémentaire. Comme le modèle de brouillon n'a pas encore vu ce jeton accepté, il est ré-exécuté pour remplir ses entrées de cache KV correspondantes en préparation de la prochaine étape de décodage, transférant à nouveau les logits.
EAGLE
EAGLE est un schéma de décodage spéculatif qui explore plusieurs séquences de brouillon, générées par une traversée en arbre des jetons probables de brouillon. Un arbre fixe (EAGLE) ou de forme dynamique (EAGLE-2) est exploré en utilisant des exécutions consécutives des jetons de brouillon, en considérant les candidats Top-K à chaque nœud au lieu de suivre le jeton ayant le meilleur score dans une séquence linéaire. Les séquences sont ensuite notées et la plus longue adéquate est sélectionnée pour continuer, en ajoutant également un jeton supplémentaire de la cible.

Pour obtenir une prédiction plus précise, un modèle de brouillon EAGLE prédit non seulement en se basant sur les jetons, mais aussi en utilisant les caractéristiques cibles (états cachés de la dernière couche) du modèle cible. L'inconvénient de l'EAGLE est le besoin d'entraîner des modèles de brouillon petits et personnalisés, suffisamment précis pour générer des candidats adéquats sous un budget de latence faible. Typiquement, un modèle de brouillon est une seule couche de transformateur identique à une couche de décodeur du modèle original, qui est étroitement couplée à la cible en se liant à ses embeddings et aux projections du lm_head. Étant donné que cela nécessite moins de capacité de cache KV, EAGLE a une empreinte mémoire plus faible.
Pour vérifier les séquences en arbre dans le modèle cible, des masques d'attention personnalisés doivent être utilisés. Malheureusement, utiliser un masque d'attention personnalisé pour une séquence entière ralentit considérablement l'attention pour des longueurs d'entrée réalistes (jusqu'à 50%), annulant une partie de l'accélération réalisable par la spéculation. Nous n'avons pas encore déployé l'exploration complète d'arbre en production pour cette raison, en nous concentrant plutôt sur le cas spécial de prédiction d'un seul jeton via des schémas de type MTP présentés dans le rapport technique DeepSeek-V3.
MTP
Ce schéma est similaire au décodage brouillon-cible, à l'exception des états cachés utilisés avec les jetons pour la prédiction. Un peu plus de travail doit être fait dans les étapes de pré-remplissage et de décodage comparé à la spéculation brouillon-cible régulière. Le modèle de brouillon utilise à la fois les jetons et les états cachés : le jeton t_{i+1} est échantillonné à partir des logits L_i correspondant au jeton t_i, qui à leur tour sont dérivés des états cachés H_i. Par conséquent, les tampons de jetons d'entrée doivent être décalés d'une étape vers la gauche par rapport aux vecteurs d'état cachés produits par la cible. La figure ci-dessous marque les correspondances utilisées pour l'entraînement, ainsi que le décalage lors de l'inférence.
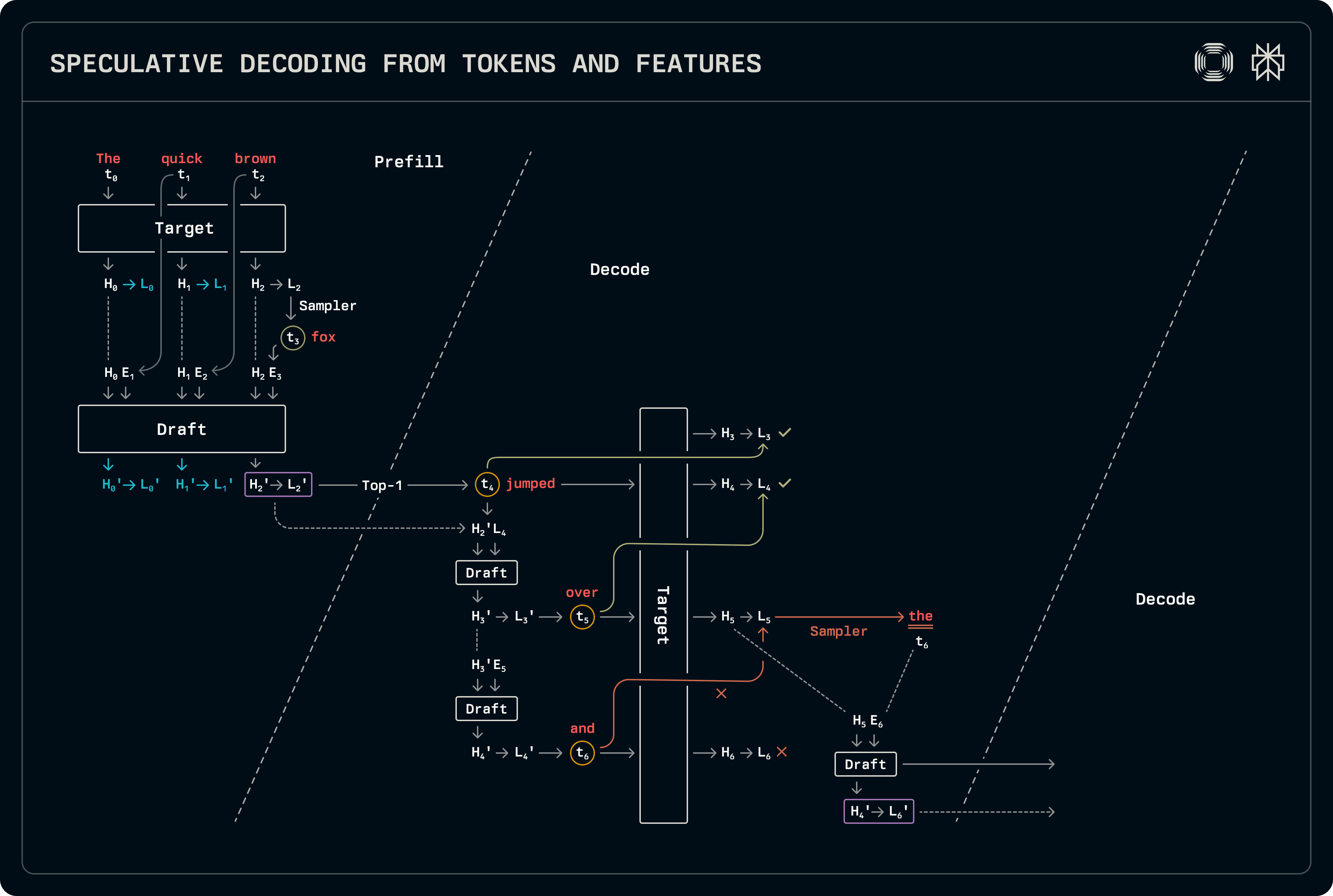
Le flux de décodage est assez similaire au décodage brouillon-cible, à l'exception du fait que les états cachés et les logits sont transférés. Notre implémentation partage tous les logits d'échantillonnage et de traitement associés, en spécialisant uniquement les invocations avancées du modèle. Quand plusieurs jetons sont prédits, le modèle de brouillon utilise des états cachés de brouillon pour la prédiction, remplissant également les entrées de cache KV sur la base de ses propres caractéristiques. À long terme, cela peut dégrader la précision. Par la suite, lors de l'exécution du modèle de brouillon pour remplir l'entrée de cache KV pour la prédiction cible, nous l'exécutons sur toute la séquence en prenant les états cachés des cibles plus précis comme entrées. Étant donné que ces modèles de brouillon sont petits, le coût supplémentaire de traitement des jetons supplémentaires est négligeable.
Entraînement des Têtes MTP
Pour bénéficier du MTP, nous avons construit l'infrastructure nécessaire pour entraîner des têtes MTP attachées à nos modèles affinés sur les ensembles de données de Perplexity, fonctionnant sur une seule unité avec 8xH100. En environ un jour, nous pouvons construire des têtes pour des modèles allant de Llama-1B à Llama-70B et DeepSeek V2-Lite. Pour les modèles plus grands, nous nous basons sur les têtes MTP construites lors du processus d'affinage.
L'objectif de l'entraînement MTP est de faire correspondre les états cachés et les logits de brouillon extrapolés à partir des états cachés de la cible aux logits et états cachés de jeton suivant de la cible. Comme l'inférence pour les états cachés est coûteuse, nous les pré-calculons en utilisant notre implémentation optimisée pour l'inférence du modèle cible, à utiliser pendant l'entraînement. Cependant, pour valider l'implémentation MTP d'inférence et assurer que les différences numériques dues à la quantification ou aux optimisations n'entravent pas les résultats, pour la validation de la perte et de l'estimation de l'exactitude, nous réutilisons entièrement l'implémentation d'inférence des modèles cible et de brouillon.
En passant à un échantillon plus large que le jeu de données ShareGPT utilisé dans l'article original, nous avons remarqué que l'architecture de tête MTP décrite et implémentée dans l'article EAGLE échouait à s'entraîner pour les modèles de taille 70B. Contrairement à ShareGPT qui contenait un grand nombre de séquences courtes, nous nous entraînons sur un nombre légèrement plus petit de prompts nettement plus longs. Puisque les têtes EAGLE originales divergeaient légèrement de la structure typique d'un transformateur, nous avons réintroduit certaines couches de Normalisation RMS qui avaient été supprimées. Nous avons constaté que cela non seulement permettait à l'entraînement de converger, mais augmentait également l'exactitude des têtes de quelques pourcentages.

Non seulement les normalisations de couche facilitent l'entraînement, mais la réintroduction des normalisations est également mathématiquement intuitive. Les têtes MTP réutilisent les embeddings et les projections de logits du modèle cible, car elles peuvent être considérables en taille (environ 2 Go pour Llama 70B). Pendant l'entraînement, celles-ci sont gelées et l'objectif est que la couche MTP apprenne à intégrer les prédictions dans le même espace vectoriel que celui que la couche de projection du modèle original a appris pendant l'entraînement. En supprimant les normalisations, un simple MLP est censé apprendre la même fonction qu'un MLP suivi d'une normalisation, ce qui entrave le rapprochement entre les états cachés des modèles de brouillon et de cible.
Inférence avec Décodage Spéculatif
Dans le moteur d'inférence, pour générer des jetons pour les séquences d'entrée, ils doivent d'abord être regroupés en lots de taille raisonnable, puis des pages doivent être allouées dans le cache KV pour les jetons suivants. Les jetons d'entrée et les informations de page KV sont ensuite emballés dans un buffer diffusé à tous les groupes parallèles exécutant le modèle. Enfin, les métadonnées sont copiées dans la mémoire GPU et le modèle est exécuté pour produire les logits à partir desquels le prochain jeton est échantillonné.
Contrairement à certaines implémentations qui couplent vaguement un serveur d'inférence de brouillon et de cible via un wrapper qui orchestre les requêtes entre eux, nos paires brouillon-cible sont étroitement couplées et passent ensemble par la génération. La planification des lots et l'allocation des pages KV sont partagées entre les modèles pour toutes les formes de décodage spéculatif : cela unifie la logique qui connecte un modèle avec le serveur d'inférence général, car ils exposent tous la même interface.
Le runtime d'inférence chez Perplexity est structuré autour de FlashInfer, qui détermine les métadonnées à construire pour configurer et programmer le noyau d'attention. Étant donné certaines séquences d'entrée formant un lot, pour la préremplissage, le décodage ou la vérification, un travail côté CPU doit être fait pour allouer des buffers intermédiaires et remplir certains buffers constants utilisés dans l'attention. Ce travail s'ajoute au coût de la planification des lots et de l'allocation des pages KV, qui entraîne également des latences devant être cachées pour maximiser l'utilisation du GPU.
Bien que nous ayons entièrement parallélisé le travail côté CPU et GPU pour l'inférence sans spéculation, nous avons découvert que l'équilibre CPU-GPU pour le décodage spéculatif est plus complexe. Le principal enjeu provient du fait que le nombre de jetons acceptés détermine la longueur de séquence pour une exécution suivante, introduisant un point de synchronisation GPU-vers-CPU difficile à éviter. Nous avons expérimenté avec différents schémas de planification pour mieux cacher la latence du travail CPU.
Planification Brouillon-Cible
Malgré sa taille inférieure à celle d'un modèle cible, quand un LLM entier est utilisé en tant que brouillon, il introduit néanmoins une latence considérable sur le GPU, offrant une certaine marge pour cacher des opérations CPU coûteuses. Étant donné que les modèles plus petits ne bénéficient pas du parallélisme de tenseur, il y a une déconnexion entre le nombre de rangs sur lesquels une cible et un brouillon sont partitionnés. Dans notre implémentation, le modèle de brouillon s'exécute uniquement sur le rang leader d'un groupe TP.
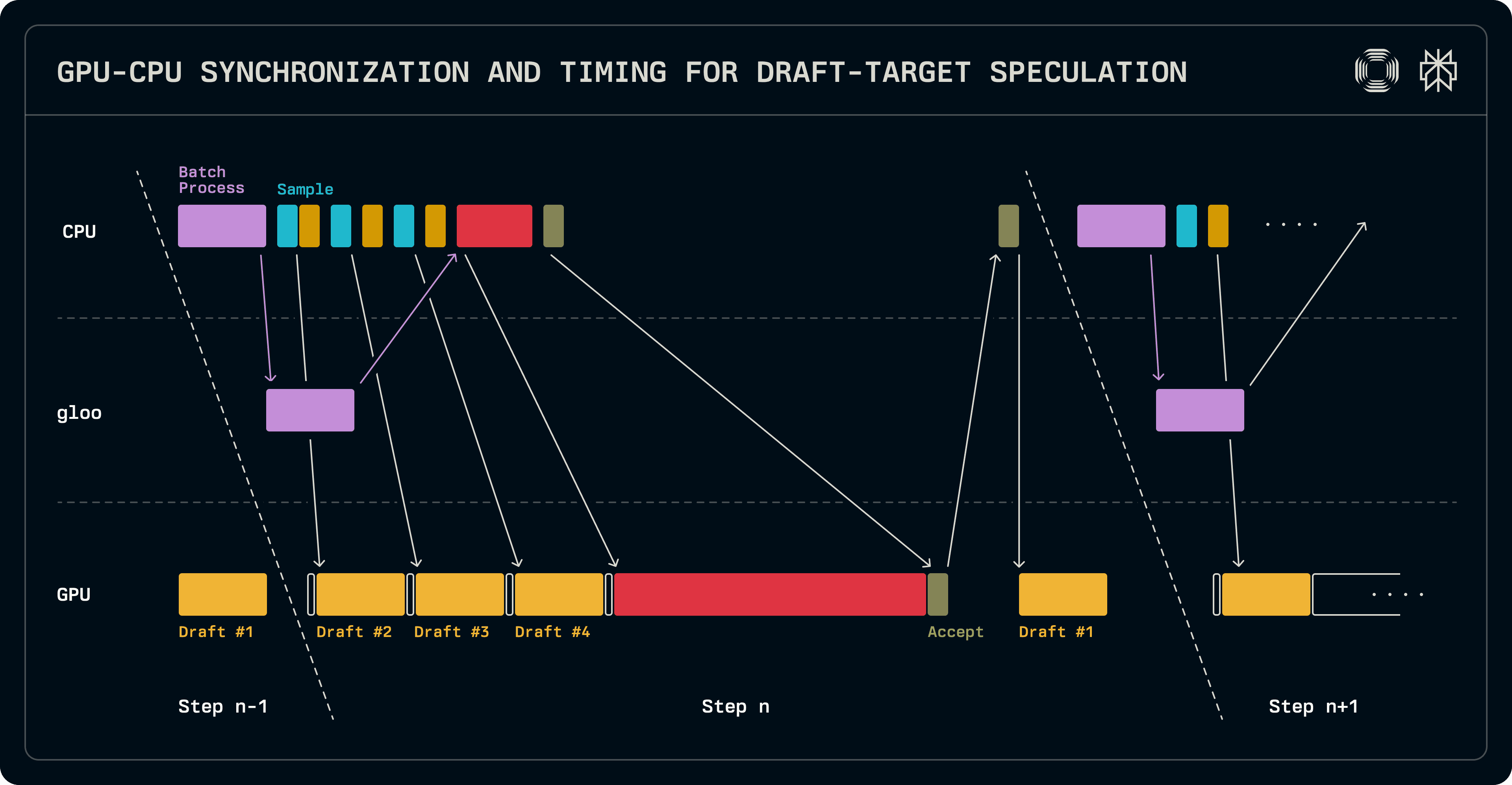
Comme indiqué précédemment, une étape de décodage transfère les logits dans l'exécution suivante. Cela nous permet de chevaucher une exécution du modèle de brouillon avec le travail de planification des lots côté CPU. Après que le lot est assemblé, des appels répétés à l'échantillonneur et au brouillon produisent les jetons de brouillon. En parallèle, le lot de vérification est assemblé pour le modèle cible et synchronisé avec les travailleurs parallèles. Les logits cibles sont vérifiés et échantillonnés pour déterminer les longueurs de séquence acceptées. À ce stade, une synchronisation GPU-vers-CPU est nécessaire pour déterminer les longueurs de séquence suivantes. Étant donné que le modèle de brouillon est seulement exécuté sur le nœud leader, son lot est configuré séquentiellement et son exécution est lancée pour remplir ses entrées de cache KV avec le jeton supplémentaire que la cible a produit. Les logits produits par cette exécution de brouillon lors de l'exécution actuelle seront utilisés pour échantillonner le premier jeton de brouillon lors de l'exécution suivante. Plus important encore, tandis que le brouillon s'exécute, le prochain lot peut être programmé.
Planification MTP pour un Jeton Unique
Bien que le runtime ne propose pas encore d'exploration en arbre de brouillon de style Eagle, nous avons implémenté un cas spécial de ce schéma, en considérant une séquence linéaire de jetons de brouillon produits par un modèle de la taille d'une seule couche de décodeur de transformateur. Ce schéma peut être utilisé pour la prédiction de brouillon en utilisant les poids open-source de DeepSeek R1. Le sous-cas de prédiction d'un seul jeton est intéressant, car des couches MTP de grande taille atteignent des taux d'acceptation suffisamment élevés pour en justifier leurs surcoûts.
La planification MTP est un peu plus complexe, car le modèle de brouillon est plus rapide, cachant moins de latence côté CPU. De plus, le brouillon est partitionné aux côtés du modèle cible, nécessitant des transferts de mémoire partagée pour les informations de lot. Un ensemble commence par transférer les informations de lot et échantillonner le premier jeton à partir des logits reportés, semblablement au schéma précédent. Ensuite, la cible est exécutée pour valider les jetons, en traitant 2 * D jetons, où D est la taille du lot de décodage. Cela est idéal pour la micro-batching dans les modèles Mixture-of-Experts (MoE) sur des interconnexions plus lentes telles que InfiniBand, car le lot se divise en deux moitiés égales. Les états cachés de la cible sont transférés à l'exécution de brouillon suivante, tandis que les logits sont passés dans l'échantillonneur pour vérification.

En effectuant une quantité limitée de travail supplémentaire sur le GPU, nous évitons la synchronisation CPU-vers-GPU après l'acceptation de la séquence de brouillon. Après que les jetons d'entrée des cibles sont décalés, un noyau plug les jetons cibles suivants dans leurs emplacements correspondants. Le brouillon est ensuite ré-exécuté avec les mêmes informations de lot que la cible, remplissant les entrées de cache KV et construisant les logits et les états cachés pour l'exécution suivante, effectuant un certain travail redondant sur les jetons non acceptés. Dans ces situations, la latence du travail inutile est à peine mesurable en raison de la petite taille du modèle de brouillon. En parallèle de l'exécution de brouillon, les longueurs de séquence sont déterminées sur le CPU et la programmation du lot suivant est lancée, sans avoir à attendre la fin du travail GPU.
Le surcoût du travail supplémentaire dans la couche de brouillon n'est pas perceptible dans l'attention, cependant les couches MLP sont plus problématiques. Étant donné que les instructions de multiplication matricielle s'adaptent à une limite de 64 le long de la dimension du nombre de jetons, si le doublement ne nécessite pas de blocs significativement plus nombreux, le surcoût est caché. Pour les séquences de brouillon plus longues, le surcoût est plus coûteux et le schéma utilisé pour les modèles brouillon-cible réguliers fonctionne mieux.
Références
Inference rapide des transformateurs via le décodage spéculatif
EAGLE : L'échantillonnage spéculatif nécessite de repenser l'incertitude des caractéristiques
EAGLE-2 : Inférence plus rapide de modèles de langage avec arbres de brouillon dynamiques
Medusa : Cadre simple d'accélération de l'inférence LLM avec plusieurs têtes de décodage
FlashInfer : Moteur d'attention efficace et personnalisable pour l'inférence LLM