

Écrit par
Équipe d'IA
Publié le
Entraînement RL pour le raisonnement mathématique
Introduction et Motivation
Les algorithmes d'apprentissage par renforcement (RL), en particulier l'optimisation de politique proximale (PPO) et l'optimisation de politique relative de groupe (GRPO), se sont révélés essentiels pour améliorer les capacités des modèles dans les tâches liées au raisonnement. Dans ce blog, nous souhaitons partager les enseignements et les raisonnements décisionnels que nous avons expérimentés lors du développement de l'infrastructure RL ainsi que de la formation de modèles de raisonnement mathématique avec RL. À des fins d'illustration, les résultats que nous montrons ci-dessous sont basés sur des modèles open source plus petits, mais la plupart d'entre eux s'appliquent également aux modèles plus grands.
L'objectif de l'exploration de la formation du modèle RL est double : 1) partager nos leçons et nos apprentissages sur la manière de former des modèles pour atteindre des performances de raisonnement mathématique à la pointe de la technologie. Cela équipe l'équipe avec les connaissances appropriées sur la manipulation des données, les recettes de mélange de données, les meilleures pratiques de formation, les subtilités des algorithmes RL et l'expérience générale d'optimisation des performances. 2) Appliquer ces apprentissages à des cas d'utilisation en production réelle pour améliorer les produits Perplexity.
Un résumé des principaux résultats :
Infrastructure : nous avons développé l'algorithme GRPO sur la bibliothèque torchtune ainsi que sur la suite Nemo, avec intégration du déroulement basé sur VLLM. Nemo sera notre infrastructure de prédilection à court terme pour la formation RL, tandis que nous développons le support torchtune GRPO, qui sera notre infrastructure préférée à long terme, pour un entretien autonome (aucune dépendance externe) ainsi qu'une architecture de cadre plus simple.
Jeu de données mathématiques utilisés : gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), séries AIME.
Formation du modèle de raisonnement mathématique :
Le mélange de données de différents niveaux de difficulté est important
RL prouve être capable d'améliorer davantage les capacités de raisonnement des modèles de langage de grande taille (LLM) au-delà du réglage fin supervisé (SFT)
La capacité du modèle de base est très importante. En particulier, la capacité long-CoT du modèle de base est importante pour une mise à l'échelle supplémentaire avec RL.
Un bon point de contrôle de départ SFT aide cela. Le SFT léger sert deux objectifs :
permettre au modèle de base RL d'être à l'aise avec la génération de réponses long-CoT. Sans cette capacité, lorsque RL force le modèle à augmenter la longueur de ses réponses, un effondrement de répétition pourrait se produire.
enseigner une certaine capacité de raisonnement au modèle de base, permettant au processus RL de commencer plus haut et d'apprendre plus rapidement dès le début, par rapport à un modèle qui ne sait générer que des réponses long-CoT avec une faible capacité de raisonnement.
Exploration de l'infrastructure de formation
Malgré la disponibilité de plusieurs cadres de formation RL open source, beaucoup ne conviennent pas à notre situation. Idéalement, nous voudrions les propriétés suivantes :
Bonne échelle avec les grandes tailles de modèles de nos modèles de production.
Bonnes optimisations de vitesse de formation.
Facile à implémenter de nouveaux algorithmes et à maintenir sans trop de dépendances externes.
Design d'architecture de cadre plus simple et extensible.
Idéalement, unifier avec le cadre de formation SFT.
Comparaison des cadres
Une comparaison des cadres que nous avons envisagés [la comparaison suivante a été faite en février 2025. Notez que de nombreux algorithmes manquants ont été implémentés plus tard.] :

Nous avons choisi Nemo Aligner comme option à court terme et avons éliminé le reste pour les raisons suivantes :
Nemo-Aligner : en raison des fonctionnalités les plus complètes déjà mises en œuvre, ainsi que du support de partenariat de Nvidia, nous avons choisi cette option comme notre principal focus à court terme. Cependant, le complexe de configuration avec des dépendances sur plusieurs dépôts ajoute un certain surcroît à l'entretien.
torchtune : il s'agit du cadre SFT que nous utilisons chez Perplexity. Le cadre est élégamment conçu et facile à étendre en général. Cependant, étant relativement nouveau, le cadre manque de nombreuses fonctionnalités à ajouter. Nous avons l'intention de nous transférer à torchtune pour RL à long terme. Une fois que nous aurons amené Nemo-aligner à un bon état, nous investirons dans le maintien d'une version interne de torchtune avec notre propre implémentation des algorithmes désirés.
VeRL : bien qu'il intègre à la fois le backend FSDP et le plus puissant Megatron-LM, le support de ce dernier est très limité en raison de la demande de la communauté étant principalement sur des modèles plus petits où FSDP est suffisant. FSDP a généralement un support plus faible pour le parallélisme de tenseur, ce qui est crucial pour les modèles plus grands, en particulier dans la formation RL. Cependant, VeRL est rapidement devenu un choix populaire pour la communauté et s'est développé de manière significative ces derniers mois. Compte tenu de ses arguments de vente sur les optimisations de débit et de plusieurs articles récents sur la formation de modèles de raisonnement/agence basés sur ce cadre (par exemple, [1], [2]), il vaut la peine de réévaluer cette option dans un avenir proche.
openRLHF : populaire dans la communauté académique. Cependant, le backend DeepSpeed le rend moins évolutif pour les grands modèles. Nous avons écarté cette option.
Développement et validation d'algorithmes
Dans cette section, nous fournissons d'abord une brève introduction à l'algorithme GRPO et discutons des améliorations techniques associées qui contribuent à la complexité de son implémentation. Ensuite, nous décrivons l'infrastructure développée pour relever ces défis.

Comparaison de PPO vs GRPO. Référence : https://arxiv.org/abs/2402.03300
PPO est un algorithme RL populaire largement utilisé pour le réglage fin des LLM en raison de sa simplicité et de son efficacité, comme illustré ci-dessus. Cependant, la dépendance de PPO sur un modèle de valeur séparé introduit une surcharge informatique et de mémoire significative.
Pour remédier à cette limitation, GRPO modifie PPO en supprimant le modèle de valeur séparé et en introduisant un calcul d'avantage basé sur des groupes, comme illustré dans la figure ci-dessus. Plus précisément, il génère plusieurs réponses candidates pour chaque question d'entrée, calcule leurs scores de récompense collectivement et détermine les avantages par rapport à ces résultats groupés. Bien qu'une telle innovation simplifie certains aspects, elle introduit de nouvelles complexités d'implémentation, telles que la génération efficace de multiples lancements de séquences longues.
Détails de l'implémentation
Bien que des algorithmes RL similaires (PPO, Reinforce) soient déjà en place dans Nemo-Aligner, il est étonnamment long de faire fonctionner GRPO correctement pour notre cas. Un résumé des améliorations que nous avons apportées comprend :
Implémentation de l'algorithme GRPO ;
Un estimateur de divergence KL plus robuste (détails) ;
Incorporer une récompense de format et des règles renforcées pour la précision mathématique (couvrant à la fois les réponses numériques et les expressions symboliques de référence) ;
Travailler avec l'équipe de support Nvidia pour intégrer le déroulement basé sur VLLM, qui a amélioré l'efficacité du déroulement de 30% et a également corrigé l'infrastructure TensorRT-LLM défaillante qui présentait un décalage des probabilités logarithmiques (voir point suivant)
Alignement des probabilités logarithmiques avec HF
Note : cet effort a été de loin le plus chronophage. Pour assurer la correction du code, nous adoptons la métrique suivante pour vérifier que les log-probabilités calculés de Nemo-Aligner sont corrects :
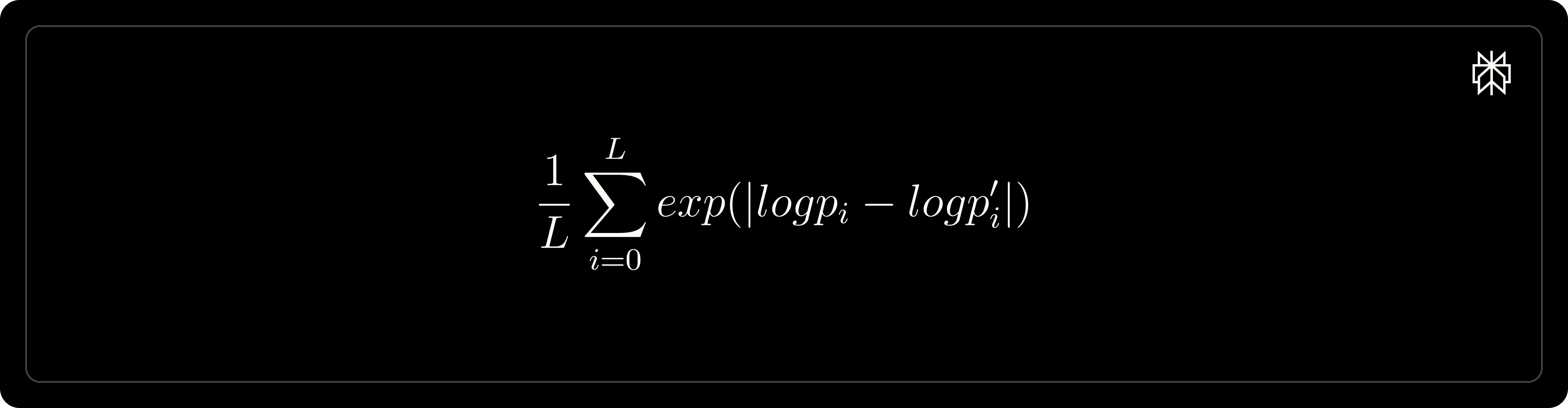
où L est la longueur d'un déroulement, le premier 𝓁𝑜𝑔𝓅ᵢ est la probabilité logarithmique du iᵉ token de Nemo-Aligner, et le second 𝓁𝑜𝑔𝓅'ᵢ est la probabilité logarithmique de référence que nous obtenons en exécutant manuellement model.forward sur un modèle Hugging Face directement. Cette métrique doit rester très proche de 1.0. Nous avons traversé plusieurs itérations de conversion de modèle nemo, mise à jour des dépôts et reconstruction d'image pour réduire la métrique de 1e5 à une plage normale de [1, 1.05].
Plusieurs séries de recherches d'hyper-paramètres pour optimiser la mémoire. En raison du fait que GRPO nécessite plusieurs échantillons par prompt, ainsi que les lancements de raisonnement mathématique sont généralement longs, nous rencontrons souvent des problèmes de mémoire insuffisante CUDA. Les hyper-paramètres, en particulier le paramètre de parallélisme, doivent être choisis avec soin pour assurer une formation fluide.
Problèmes mineurs liés à l'arrêt précoce de la consommation du dataloader et problèmes de forme de tenseur dans des cas limites.
Expériences
Dans cette section, nous présentons la configuration expérimentale et les résultats, en nous appuyant sur l'infrastructure précédemment décrite.
Configuration expérimentale
Nous évaluons les modèles sur le jeu de données MATH-500 en utilisant la métrique pass@1 définie comme suit, et nous rapportons spécifiquement les résultats pour pass@1. Pendant l'évaluation, nous réglons la température d'échantillonnage à 0,7 et une valeur de top-𝑝 de 0,95 pour générer k lancements.
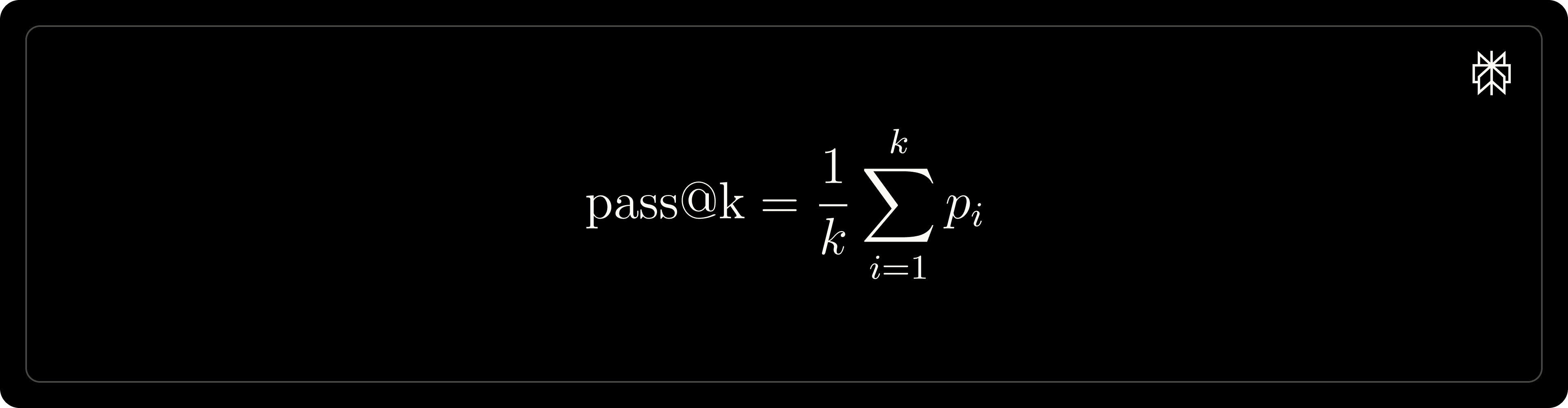
où 𝒫𝒾 désigne la justesse de la i-ème réponse. Les prompts de formation et d'évaluation sont listés ci-dessous, respectivement. Plus précisément, nous n'utilisons pas de prompt système, c'est-à-dire que les prompts suivants sont ajoutés au message utilisateur.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Les configurations expérimentales supplémentaires sont décrites ci-dessous.
SPÉCIFICATIONS DU MODÈLE
Nous avons principalement expérimenté avec des modèles Llama denses, sélectionnant nos modèles de base parmi les deux variantes suivantes en raison de leur taille appropriée et de leur adoption répandue au sein de la communauté de recherche. Ces modèles servent de références de base pour la performance en raisonnement dans nos expériences ultérieures :
Llama 3.1 8B Instruct
Llama 3.1 8B Base
DÉTAILS DES JEUX DE DONNÉES
Les jeux de données collectés et utilisés dans nos expériences sont décrits ci-dessous.
Sources | Taille | Modèles d'étiquetage | Difficulté | Utilisation |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B aperçu & R1 | Facile | Formation |
MATH | ~7k | QwQ 32B aperçu & R1 | Moyenne | Formation |
Orz (contient MATH) | ~57k | QwQ 32B aperçu & R1 | Difficile | Formation |
numinamath | ~250K (filtration) | Aucun | Difficile | Formation |
MATH-500 | 500 | Aucun | Moyenne | Évaluation |
PROCÉDURE D'ENTRAÎNEMENT
Cette sous-section décrit les méthodes d'entraînement spécifiques, notamment la sélection des hyper-paramètres, employées lors du réglage fin basé sur GRPO.
Hyperparamètres :
Nous avons utilisé le jeu de données GSM8K pour la formation dans cette sous-section.
Taux d'apprentissage (LR) et coefficient KL
Nous présentons les résultats de précision pour diverses combinaisons de taux d'apprentissage (LR) et de coefficients KL ci-dessous. (Notez que certaines expérimentations ont été interrompues prématurément en raison d'erreurs liées à l'infrastructure, entraînant de légères disparités dans le nombre total d'étapes d'entraînement.)
Taux d'apprentissage/coefficient KL | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
L'analyse de ces résultats indique qu'un taux d'apprentissage de 3e-7 démontre de manière constante une performance stable à travers différents réglages KL, il a donc été adopté pour les expériences principales. De plus, les expériences ont révélé de meilleurs résultats avec des valeurs KL plus basses, ce qui nous a amenés à supprimer totalement le terme KL lors des courses d'entraînement principales. Des taux d'apprentissage plus élevés comme 5e-7 et 8e-7 avaient tendance à accélérer la convergence précoce, limitant le développement des capacités de raisonnement en longue chaîne de pensée (CoT) à un stade avancé.
Température
Températures testées : [0.7 (rouge foncé), 0.8 (rouge), 1.0 (vert), 1.1 (mauve), 1.2 (bleu), 1.3 (gris)]
Les figures ci-dessous sont la précision de formation (à gauche) contre la précision de validation (à droite).

Température | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions :
Sur la base des résultats empiriques présentés ci-dessus, nous sélectionnons une température de 1,0 comme réglage par défaut, équilibrant la vitesse de convergence et la précision globale.
Les réglages de température plus élevés (par exemple, 1,2, 1,3) ont un impact négatif sur la convergence, entraînant une instabilité et l'échec à atteindre une performance satisfaisante.
Une température élevée, comme 1,2, 1,3, peut empêcher le modèle de converger
Alors que les valeurs de température plus basses (par exemple, 0,7, 0,8) facilitent une convergence initiale rapide, ces réglages conduisent généralement à une saturation prématurée, causant une amélioration limitée des performances sur le set de validation lors des étapes ultérieures de formation.
Modèles de récompense
Dans nos expériences préliminaires, nous avons évalué les deux modèles de récompense basés sur des règles proposés dans le document DeepSeek :
Récompense de précision : Cette fonction de récompense évalue la justesse de la sortie du modèle en comparant les réponses fournies par l'assistant avec les solutions de référence prédéfinies.
Récompense de format : Ce modèle de récompense encourage le modèle de langage à structurer ses réponses dans un format prédéfini et cohérent. Dans nos expériences, le format souhaité exige que les LLMs séparent explicitement le processus de raisonnement de la réponse finale en les incluant dans des balises XML-like spécifiques. Plus concrètement, le format attendu est montré dans
TRAINING_PROMPTlisté ci-dessus.
Résultats
Voici la configuration d'entraînement de nos expérimentations principales :
LR = 3e-7, coefficient KL = 0, Température = 1, uniquement la récompense de précision.
Résultat principal
La figure ci-dessous présente les résultats principaux de cette étude, montrant des comparaisons de précision de validation à travers trois conditions expérimentales :
Validation sur trois configurations RL: Gauche: entraînement à partir d'un modèle SFT-préchauffé ; Milieu: entraînement à partir de Llama 3.1 8B instruct ; Droite: entraînement à partir de Llama 3.1 8B Base
Les trois lignes illustrées dans la figure correspondent aux configurations suivantes
[Rouge] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle préchauffé et affiné de manière supervisée ORZ (4ème époque). Les données SFT sont étiquetées par le modèle QwQ-32B-aperçu, qui est un modèle de raisonnement CoT.
[Vert] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B instruct vanille.
[Bleu] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B base vanille.
Les résultats mettent en évidence deux conclusions clés :
RL a considérablement amélioré les capacités de raisonnement mathématique des modèles, comme en témoignent les améliorations de la précision de validation et des longueurs de génération accrues. (Notes : la précision de Llama 3.1 8B instruct et du modèle affiné selon ORZ est d'environ 0,38 et 0,60, respectivement. Le meilleur résultat RL, la ligne rouge dans le graphique ci-dessus, a atteint un score de 0,70 sur MATH500, ce qui correspond à des résultats similaires dans la littérature, par exemple, [1], [2])
L'exposition préalable aux données de raisonnement long-CoT lors du réglage supervisé ou de la phase de pré-entraînement a considérablement accéléré l'efficacité et l'efficacité du réglage fin RL ultérieur. D'après les courbes ci-dessus, il est clair que l'exposition long-CoT de SFT permet à la ligne rouge de commencer et de culminer beaucoup plus haut que les deux autres. (Note : Contrairement aux affirmations de certains articles, nos observations suggèrent que SFT améliore l'efficacité des étapes RL ultérieures. Bien que nous supposions que SFT peut également améliorer la performance maximale du modèle de base, nous n'avons pas encore suffisamment formé le modèle pour valider cette hypothèse de manière concluante.)
Analyse des phénomènes observés
Pendant nos expériences, nous avons observé plusieurs phénomènes remarquables que nous détaillons ici.
LE TAUX D'APPRENTISSAGE COMPTE
Nous avons constaté que le taux d'apprentissage dans GRPO contrôle généralement deux choses : 1) à quelle vitesse l'apprentissage s'amorce, et 2) à quel point la convergence est stable. Un taux d'apprentissage plus petit ralentit le progrès de l'apprentissage, ce qui est attendu. Cependant, avec un grand taux d'apprentissage, même si la courbe d'apprentissage monte rapidement lors des premières étapes, elle mène souvent à l'effondrement du modèle si elle est continuellement entraînée après convergence. Dans le graphique ci-dessous, les 3 lignes correspondent à 3 taux d'apprentissage différents :
Violet :
8e-7,Vert :
3e-7,Bleu :
1e-7.
Avec lr=8e-7, l'apprentissage plafonne très tôt, puis provoque l'effondrement du modèle (et la longueur des réponses explose) très rapidement. Avec lr=3e-7, l'apprentissage atteint le même niveau vers la fin des 15 000 étapes et est stable, tandis qu'avec lr=1e-7, l'apprentissage est trop lent, et la formation ne converge pas dans les 15 000 étapes. (Les trois courses utilisent l'optimiseur Adam, la plage de taux d'apprentissage est constante).
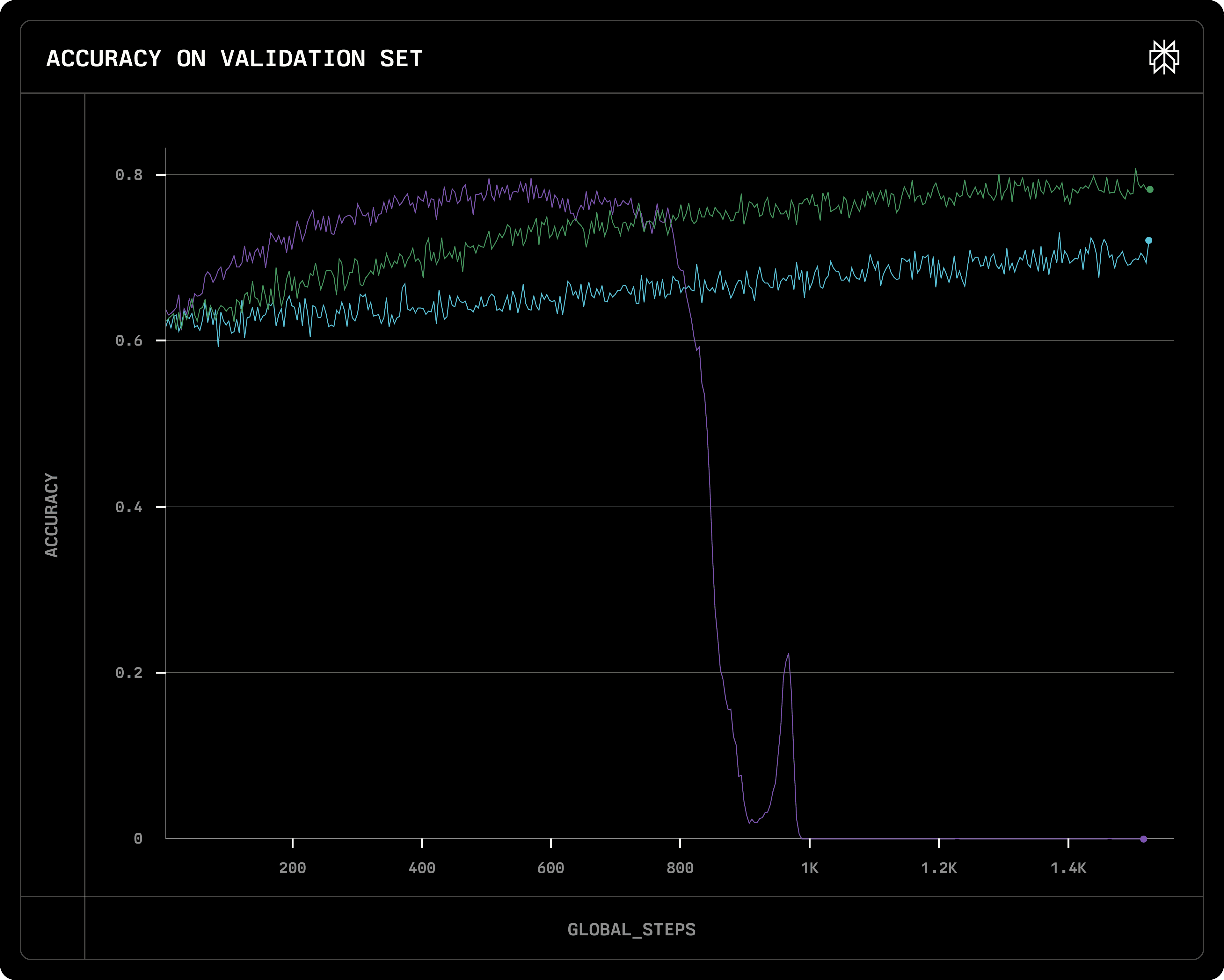
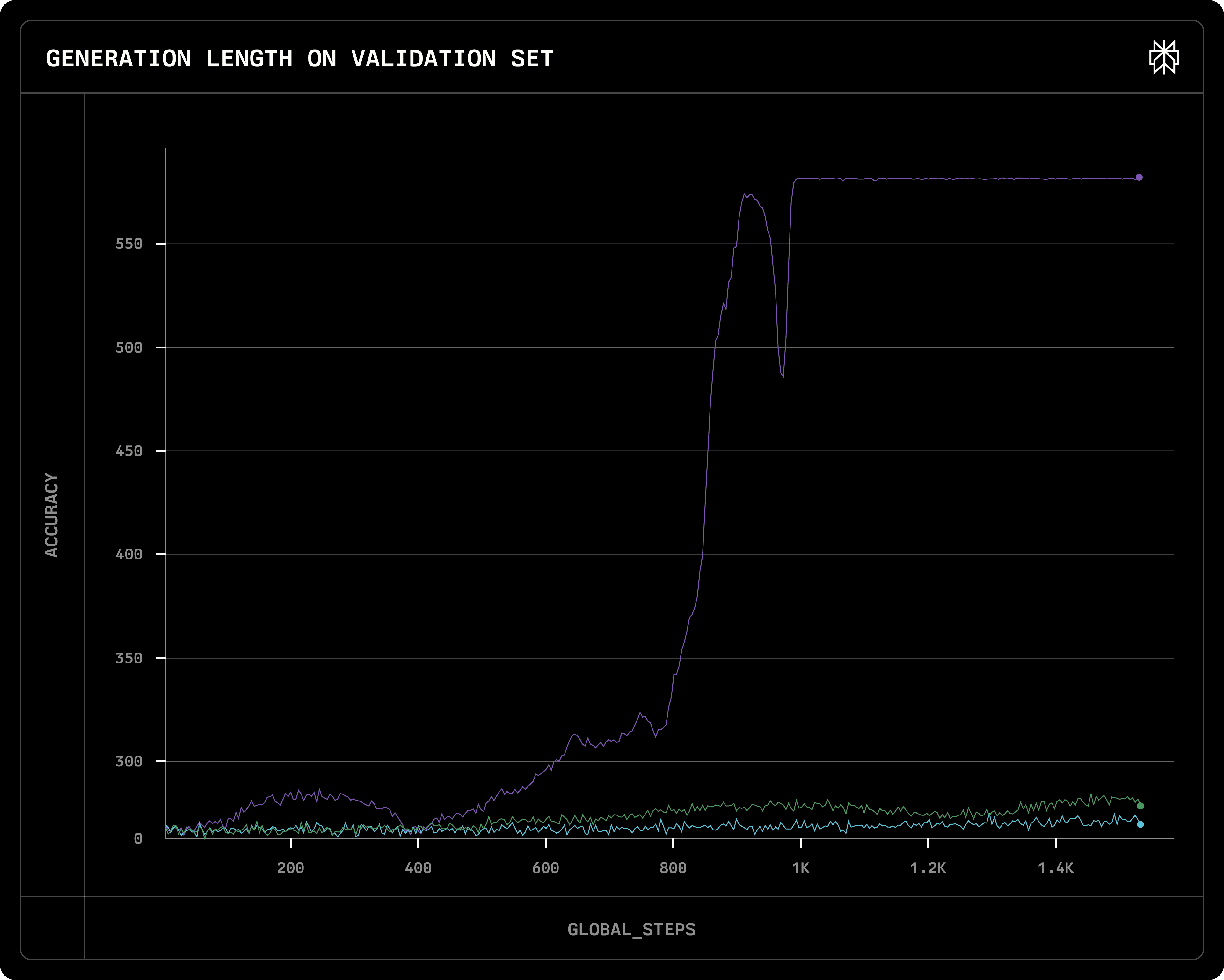
Récompense de validation (c'est-à-dire précision) de trois courses avec différents taux d'apprentissage : Violet : 8e-7, Vert : 3e-7 ; Bleu : 1e-7
Nous examinerons plus en avant pourquoi la courbe des récompenses s'effondre dans la section Effondrement du modèle.
EFFONDREMENT DU MODÈLE
Nous définissons l'effondrement du modèle comme la détérioration soudaine des capacités génératives d'un modèle pendant la formation RL. Cela se manifeste principalement sous deux formes au cours de nos expériences : effondrement par auto-répétition et effondrement de fin de séquence.
Effondrement par auto-répétition : Cette forme d'effondrement est apparue principalement dans les expériences incorporant une récompense de format. Initialement conçu pour guider le modèle vers la production de sorties bien structurées et interprétables, la récompense de format exige que le modèle organise ses réponses en utilisant des balises
<think></think>et<answer></answer>distinctes. Cependant, tout en promouvant la clarté structurelle, nous avons constaté que ce signal de récompense augmentait involontairement la probabilité d'effondrement par répétition.
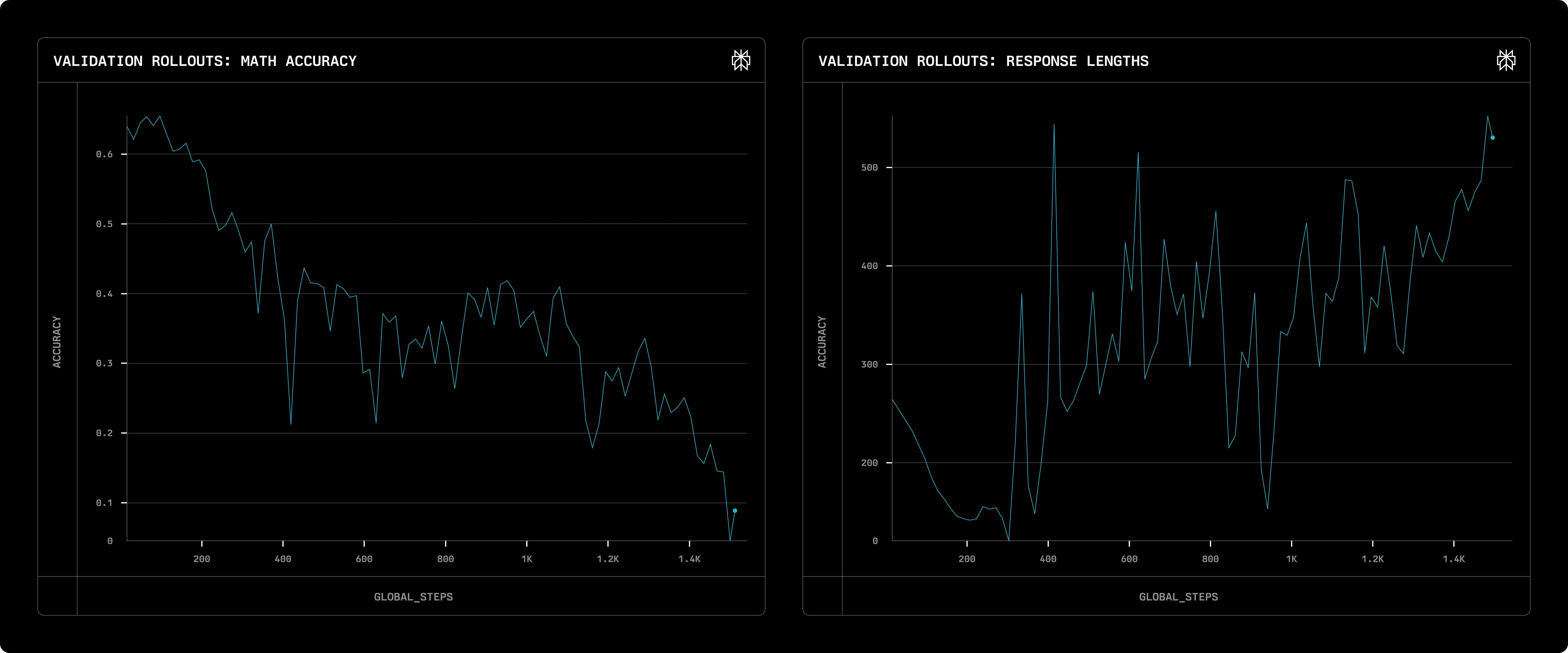
Initialement, nous avons employé une récompense de format relativement lâche - nécessitant au moins un bloc <think> et un bloc <answer> - pour encourager l'adoption de la structure de réponse souhaitée. Dans l'exemple suivant, bien que la récompense finale converge bien, les lancements ont commencé à avoir de graves problèmes de répétition lorsque les étapes de formation dépassent 110.

Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format lâche
Un examen plus attentif des lancements révèle qu'après la convergence, le modèle génère un processus de réflexion normal (quelque chose sans les balises <think>), puis la réponse correcte, puis une répétition des blocs de format avec un contenu vide (voir l'exemple ci-dessous).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
Pour remédier à cela, nous avons expérimenté avec une récompense de format plus stricte exigeant exactement un bloc <think> suivi d'un bloc <answer>. Cependant, cet ajustement a aggravé le problème : non seulement la répétition a persisté, mais la précision des réponses s'est également détériorée [lien].
Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format stricte
Un exemple illustratif est joint ci-dessous :
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Sur la base de ces observations, nous avons initialement supposé que la récompense de format elle-même était la cause principale de l'effondrement. Pour tester cela, nous avons mené des expériences de suivi avec la récompense de format entièrement supprimée, ce qui nous amène à l'effondrement de fin de séquence suivant.
Effondrement de fin de séquence : cet effondrement se produit lorsque le modèle atteint la limite maximale de génération de tokens autorisée, entraînant ensuite une défaillance des performances.
Ce phénomène résulte probablement de scénarios de perte mal définis, où plusieurs sorties d'une seule requête d'entrée reçoivent uniformément des récompenses identiques. Cela se produit lorsque tous les lancements d'un prompt sont coupés, ce qui entraîne une récompense pour tous égale à 0, donc l'avantage est également 0. Examinons de plus près l'effondrement de la courbe de récompense exemple dans la section Le taux d'apprentissage compte. Dans ce cas, le coefficient KL est réglé sur 0. Pour les prompts dont tous les lancements sont coupés, il est impossible de faire sortir la politique de cet état, car le gradient de la politique devient 0 [voir Eq 2 dans la section Limites]. La précision mathématique commence à diminuer à mesure que de plus en plus de lancements sont coupés, puis reste coincée dans cette situation. Dans les graphiques suivants, nous pouvons voir une corrélation claire entre le taux de coupure et la baisse de la récompense rollout d'entraînement.

Effondrement de fin de séquence. L'effondrement de la récompense de la formation s'aligne avec la coupure du rollout
Notez que l'effondrement de fin de séquence est également observé dans Demystifying Long Chain-of-Thought Reasoning in LLMs, même avec le terme KL ajouté. Leur article a proposé une approche de mise en forme de récompense qui tente de contrôler la longueur de la séquence de déploiement. Cependant, nos expériences montrent que bien que la mise en forme des récompenses ait réussi à supprimer l'effondrement de la longueur (collapse de longueur), elle a empêché le modèle d'apprendre le raisonnement et la réponse corrects, ce qui a entraîné une précision mathématique beaucoup plus basse tout au long de la formation :
Précision de validation et longueur de réponse avec mise en forme des récompenses
Dans la section Limites, nous proposerons de nouvelles façons de gérer cette situation. En combinant l'exemple d'auto-répétition précédent et les résultats principaux ci-dessus, il semble qu'avec un modèle de base qui n'est pas exposé à des réponses de raisonnement en longue chaîne de pensée, RL amènerait le modèle à augmenter sa longueur de réponse de manière défectueuse et finalement s'effondrer par répétition.
CAPACITÉ DU MODÈLE DE BASE
Nous avons réalisé une étude d'ablation pour examiner l'impact de SFT sur la performance RL ultérieure. Les modèles ont d'abord été ajustés à l'aide d'ensembles de données de différents niveaux de difficulté - ORZ (difficile), MATH (moyen) et GSM8K (facile) - suivis d'un réglage RL exclusivement sur le jeu de données ORZ.
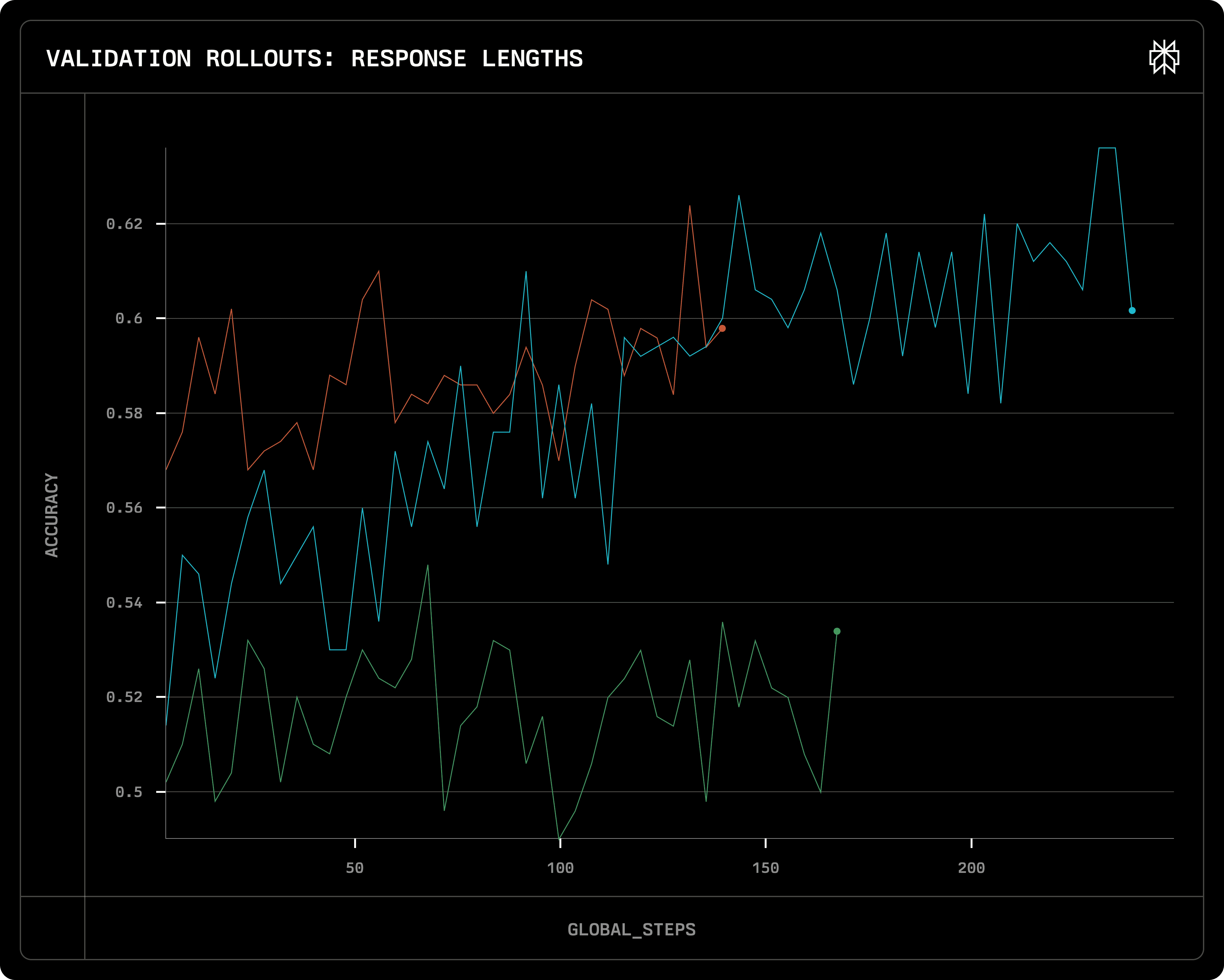
Précision de validation sur différents modèles initiaux
[Bleu] : SFT sur des données ORZ (difficulté : difficile) puis RL sur ORZ
[Rouge] : SFT sur des données MATH (difficulté : moyen) puis RL sur ORZ
[Vert] : SFT sur des données GSM8K (difficulté : facile) puis RL sur ORZ
Les résultats ont clairement indiqué que l'utilisation d'un mélange diversifié de niveaux de difficulté à l'étape SFT améliorait considérablement l'efficacité de la formation RL.
Les résultats de notre étude d'ablation suggèrent des directions de recherche futures précieuses, en particulier l'exploration de stratégies d'apprentissage continu.
Une approche potentielle consiste à examiner la conception de cursus au sein d'un domaine unique vs une capacité, en augmentant progressivement la complexité ou la difficulté pour améliorer progressivement la compétence du modèle.
Une autre direction intrigante implique l'exploration de stratégies de cursus qui couvrent plusieurs capacités ou domaines - par exemple, développer initialement des capacités de suivi d'instructions avant de progresser vers des tâches de raisonnement plus complexes.
Comprendre l'efficacité et l'interaction de ces stratégies d'apprentissage pourrait optimiser de manière significative l'efficacité de la formation et finalement améliorer les performances globales du modèle. (Ce genre de stratégie a été employé par QwQ 32B, comme illustré dans leur rapport technique).
MISE À L'ÉCHELLE DE LA LONGUEUR DE DÉPLOIEMENT
Comme observé ci-dessus ainsi que dans de nombreuses littératures (par exemple, R1), RL encourage intrinsèquement les déploiements à devenir plus longs (sauf si une récompense de contrôle de longueur spécifique est utilisée). Cependant, nous avons constaté que RL ne se contente pas d'augmenter aveuglément la longueur des déploiements - au contraire, il essaie de trouver une longueur optimale en fonction du modèle initial donné. Par exemple, le graphique vert ci-dessous montre la mise à l'échelle de la longueur en utilisant le modèle Llama 3.1 8B base, tandis que le graphique violet utilise le même modèle Llama 3.1 8B mais préchauffé sur les données ORZ étiquetées par un étiqueteur CoT (QwQ-32B-aperçu). Le premier modèle n'a pas été formé sur des données CoT du tout et à tendance à générer des réponses courtes dès le début. Pour atteindre une précision mathématique plus élevée, RL encourage le modèle à produire des réponses plus longues. D'un autre côté, le modèle suivant, en raison de l'effet SFT, a tendance à générer des réponses très longues dès le départ. RL a en fait supprimé la longueur de génération, tandis que la précision mathématique augmente également.
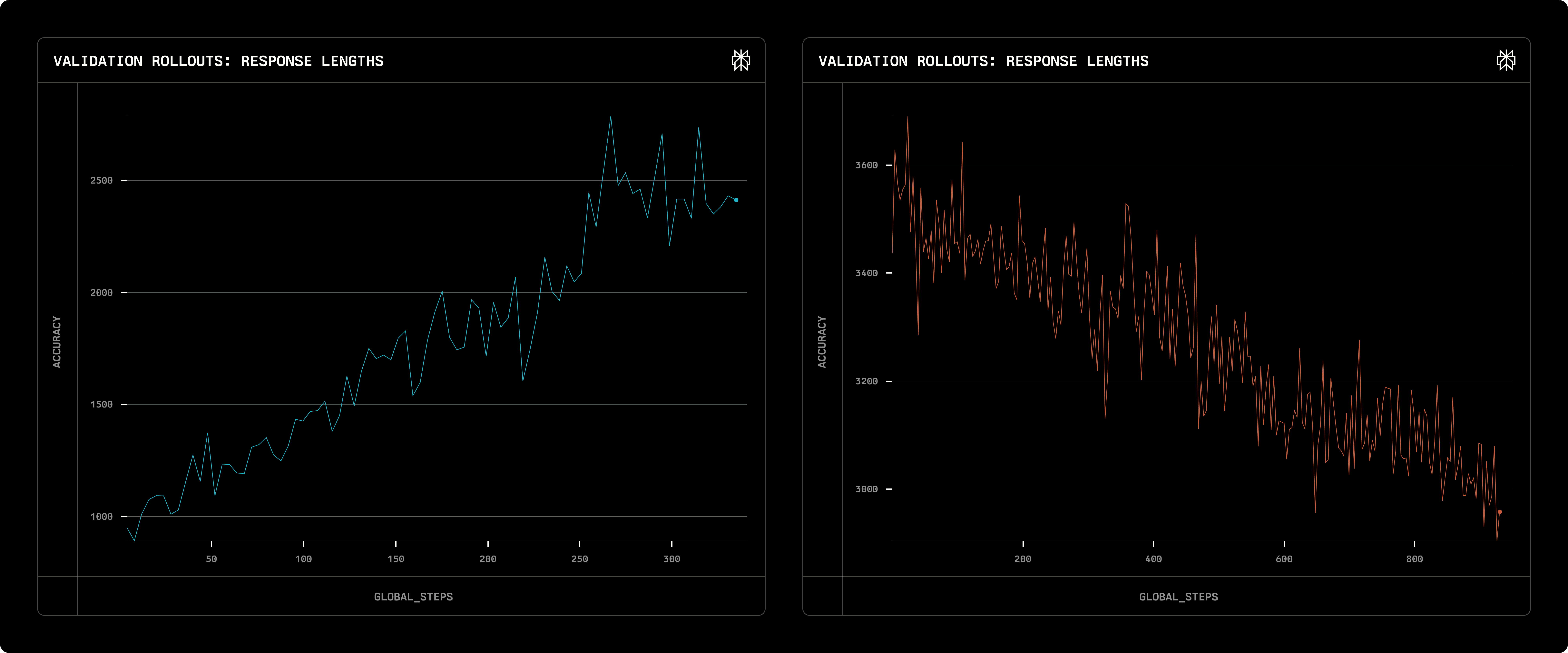
Mise à l'échelle de la longueur de déploiement avec un modèle initial différent: Llama 3.1 8B base (gauche) et Préchauffé SFT (droite)
Limites
La fonction de perte GRPO et les équations de mise à jour du gradient correspondantes sont fournies ci-dessous, mettant en évidence les biais potentiels introduits pendant les mises à jour de gradient.
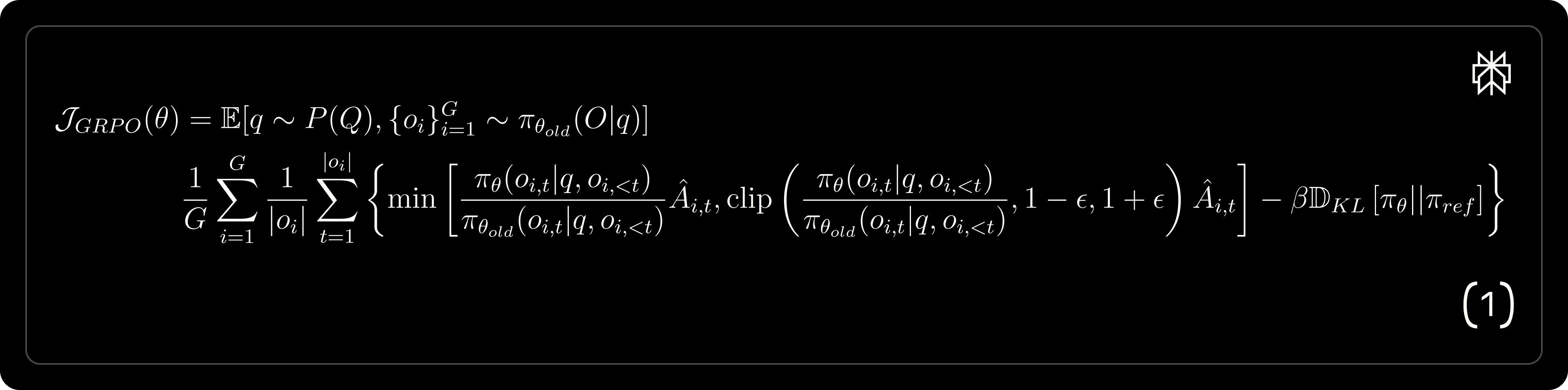

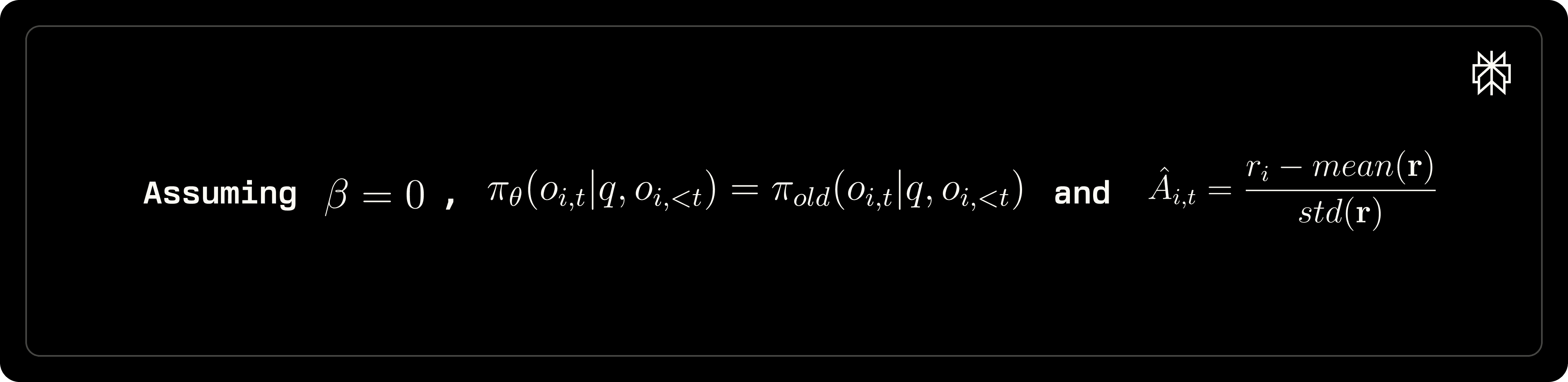
BIAIS D'ESTIMATION DE L'AVANTAGE
Nous notons que la façon dont l'avantage Âᵢ,ₜ est estimé peut affecter de manière significative la formation du modèle. En particulier, la normalisation par l'écart-type des récompenses au niveau du groupe introduit deux problèmes clés :
Avantage diminuant pour des réponses uniformes. Lorsque toutes les réponses pour une requête donnée produisent des récompenses identiques, le gradient résultant devient zéro, causant l'échec de la mise à jour du modèle. Une solution proposée consiste à ajuster le calcul des récompenses comme suit :

Mise à l'échelle inégale du gradient entre les requêtes. Les requêtes avec une faible variance de récompense (typiquement les questions plus faciles) aboutissent à un plus grand Âᵢ,ₜ, conduisant à des estimations d'avantages disproportionnellement importantes et donc à des mises à jour de gradient plus fortes. En revanche, les requêtes plus difficiles (avec une variance élevée) contribuent moins à l'apprentissage. Cela introduit un biais dans la formation en faveur des exemples faciles.
Nous prévoyons d'essayer ces modifications supplémentaires au niveau des algorithmes dans nos prochaines étapes.
Conclusion
Dans ce travail, nous avons systématiquement exploré les approches d'apprentissage par renforcement (RL) pour améliorer le raisonnement mathématique dans les grands modèles de langage, en nous concentrant sur le développement et le déploiement de l'algorithme GRPO dans des infrastructures de formation RL modernes. Nos expériences démontrent que RL, en particulier lorsqu'il est initialisé à partir de modèles exposés à un raisonnement en longue chaîne de pensée (CoT) via un réglage fin supervisé, peut augmenter considérablement la précision du raisonnement mathématique et la qualité des réponses. Nous avons constaté que le choix du modèle de base et la diversité des données supervisées influencent de manière critique l'efficacité et la performance finale de RL. Bien que notre implémentation ait abordé des défis techniques clés — tels que l'efficacité des déploiements et l'alignement des probabilités logarithmiques — des problèmes tels que l'effondrement du modèle et le biais d'estimation des avantages restent des domaines ouverts pour une recherche plus poussée. Globalement, nos résultats fournissent une base solide pour les futurs travaux sur les stratégies de cursus et les améliorations algorithmiques, dans le but d'avancer les capacités de raisonnement mathématique à la pointe de la technologie dans les modèles de langage.
Entraînement RL pour le raisonnement mathématique
Introduction et Motivation
Les algorithmes d'apprentissage par renforcement (RL), en particulier l'optimisation de politique proximale (PPO) et l'optimisation de politique relative de groupe (GRPO), se sont révélés essentiels pour améliorer les capacités des modèles dans les tâches liées au raisonnement. Dans ce blog, nous souhaitons partager les enseignements et les raisonnements décisionnels que nous avons expérimentés lors du développement de l'infrastructure RL ainsi que de la formation de modèles de raisonnement mathématique avec RL. À des fins d'illustration, les résultats que nous montrons ci-dessous sont basés sur des modèles open source plus petits, mais la plupart d'entre eux s'appliquent également aux modèles plus grands.
L'objectif de l'exploration de la formation du modèle RL est double : 1) partager nos leçons et nos apprentissages sur la manière de former des modèles pour atteindre des performances de raisonnement mathématique à la pointe de la technologie. Cela équipe l'équipe avec les connaissances appropriées sur la manipulation des données, les recettes de mélange de données, les meilleures pratiques de formation, les subtilités des algorithmes RL et l'expérience générale d'optimisation des performances. 2) Appliquer ces apprentissages à des cas d'utilisation en production réelle pour améliorer les produits Perplexity.
Un résumé des principaux résultats :
Infrastructure : nous avons développé l'algorithme GRPO sur la bibliothèque torchtune ainsi que sur la suite Nemo, avec intégration du déroulement basé sur VLLM. Nemo sera notre infrastructure de prédilection à court terme pour la formation RL, tandis que nous développons le support torchtune GRPO, qui sera notre infrastructure préférée à long terme, pour un entretien autonome (aucune dépendance externe) ainsi qu'une architecture de cadre plus simple.
Jeu de données mathématiques utilisés : gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), séries AIME.
Formation du modèle de raisonnement mathématique :
Le mélange de données de différents niveaux de difficulté est important
RL prouve être capable d'améliorer davantage les capacités de raisonnement des modèles de langage de grande taille (LLM) au-delà du réglage fin supervisé (SFT)
La capacité du modèle de base est très importante. En particulier, la capacité long-CoT du modèle de base est importante pour une mise à l'échelle supplémentaire avec RL.
Un bon point de contrôle de départ SFT aide cela. Le SFT léger sert deux objectifs :
permettre au modèle de base RL d'être à l'aise avec la génération de réponses long-CoT. Sans cette capacité, lorsque RL force le modèle à augmenter la longueur de ses réponses, un effondrement de répétition pourrait se produire.
enseigner une certaine capacité de raisonnement au modèle de base, permettant au processus RL de commencer plus haut et d'apprendre plus rapidement dès le début, par rapport à un modèle qui ne sait générer que des réponses long-CoT avec une faible capacité de raisonnement.
Exploration de l'infrastructure de formation
Malgré la disponibilité de plusieurs cadres de formation RL open source, beaucoup ne conviennent pas à notre situation. Idéalement, nous voudrions les propriétés suivantes :
Bonne échelle avec les grandes tailles de modèles de nos modèles de production.
Bonnes optimisations de vitesse de formation.
Facile à implémenter de nouveaux algorithmes et à maintenir sans trop de dépendances externes.
Design d'architecture de cadre plus simple et extensible.
Idéalement, unifier avec le cadre de formation SFT.
Comparaison des cadres
Une comparaison des cadres que nous avons envisagés [la comparaison suivante a été faite en février 2025. Notez que de nombreux algorithmes manquants ont été implémentés plus tard.] :
Nous avons choisi Nemo Aligner comme option à court terme et avons éliminé le reste pour les raisons suivantes :
Nemo-Aligner : en raison des fonctionnalités les plus complètes déjà mises en œuvre, ainsi que du support de partenariat de Nvidia, nous avons choisi cette option comme notre principal focus à court terme. Cependant, le complexe de configuration avec des dépendances sur plusieurs dépôts ajoute un certain surcroît à l'entretien.
torchtune : il s'agit du cadre SFT que nous utilisons chez Perplexity. Le cadre est élégamment conçu et facile à étendre en général. Cependant, étant relativement nouveau, le cadre manque de nombreuses fonctionnalités à ajouter. Nous avons l'intention de nous transférer à torchtune pour RL à long terme. Une fois que nous aurons amené Nemo-aligner à un bon état, nous investirons dans le maintien d'une version interne de torchtune avec notre propre implémentation des algorithmes désirés.
VeRL : bien qu'il intègre à la fois le backend FSDP et le plus puissant Megatron-LM, le support de ce dernier est très limité en raison de la demande de la communauté étant principalement sur des modèles plus petits où FSDP est suffisant. FSDP a généralement un support plus faible pour le parallélisme de tenseur, ce qui est crucial pour les modèles plus grands, en particulier dans la formation RL. Cependant, VeRL est rapidement devenu un choix populaire pour la communauté et s'est développé de manière significative ces derniers mois. Compte tenu de ses arguments de vente sur les optimisations de débit et de plusieurs articles récents sur la formation de modèles de raisonnement/agence basés sur ce cadre (par exemple, [1], [2]), il vaut la peine de réévaluer cette option dans un avenir proche.
openRLHF : populaire dans la communauté académique. Cependant, le backend DeepSpeed le rend moins évolutif pour les grands modèles. Nous avons écarté cette option.
Développement et validation d'algorithmes
Dans cette section, nous fournissons d'abord une brève introduction à l'algorithme GRPO et discutons des améliorations techniques associées qui contribuent à la complexité de son implémentation. Ensuite, nous décrivons l'infrastructure développée pour relever ces défis.
Comparaison de PPO vs GRPO. Référence : https://arxiv.org/abs/2402.03300
PPO est un algorithme RL populaire largement utilisé pour le réglage fin des LLM en raison de sa simplicité et de son efficacité, comme illustré ci-dessus. Cependant, la dépendance de PPO sur un modèle de valeur séparé introduit une surcharge informatique et de mémoire significative.
Pour remédier à cette limitation, GRPO modifie PPO en supprimant le modèle de valeur séparé et en introduisant un calcul d'avantage basé sur des groupes, comme illustré dans la figure ci-dessus. Plus précisément, il génère plusieurs réponses candidates pour chaque question d'entrée, calcule leurs scores de récompense collectivement et détermine les avantages par rapport à ces résultats groupés. Bien qu'une telle innovation simplifie certains aspects, elle introduit de nouvelles complexités d'implémentation, telles que la génération efficace de multiples lancements de séquences longues.
Détails de l'implémentation
Bien que des algorithmes RL similaires (PPO, Reinforce) soient déjà en place dans Nemo-Aligner, il est étonnamment long de faire fonctionner GRPO correctement pour notre cas. Un résumé des améliorations que nous avons apportées comprend :
Implémentation de l'algorithme GRPO ;
Un estimateur de divergence KL plus robuste (détails) ;
Incorporer une récompense de format et des règles renforcées pour la précision mathématique (couvrant à la fois les réponses numériques et les expressions symboliques de référence) ;
Travailler avec l'équipe de support Nvidia pour intégrer le déroulement basé sur VLLM, qui a amélioré l'efficacité du déroulement de 30% et a également corrigé l'infrastructure TensorRT-LLM défaillante qui présentait un décalage des probabilités logarithmiques (voir point suivant)
Alignement des probabilités logarithmiques avec HF
Note : cet effort a été de loin le plus chronophage. Pour assurer la correction du code, nous adoptons la métrique suivante pour vérifier que les log-probabilités calculés de Nemo-Aligner sont corrects :
où L est la longueur d'un déroulement, le premier 𝓁𝑜𝑔𝓅ᵢ est la probabilité logarithmique du iᵉ token de Nemo-Aligner, et le second 𝓁𝑜𝑔𝓅'ᵢ est la probabilité logarithmique de référence que nous obtenons en exécutant manuellement model.forward sur un modèle Hugging Face directement. Cette métrique doit rester très proche de 1.0. Nous avons traversé plusieurs itérations de conversion de modèle nemo, mise à jour des dépôts et reconstruction d'image pour réduire la métrique de 1e5 à une plage normale de [1, 1.05].
Plusieurs séries de recherches d'hyper-paramètres pour optimiser la mémoire. En raison du fait que GRPO nécessite plusieurs échantillons par prompt, ainsi que les lancements de raisonnement mathématique sont généralement longs, nous rencontrons souvent des problèmes de mémoire insuffisante CUDA. Les hyper-paramètres, en particulier le paramètre de parallélisme, doivent être choisis avec soin pour assurer une formation fluide.
Problèmes mineurs liés à l'arrêt précoce de la consommation du dataloader et problèmes de forme de tenseur dans des cas limites.
Expériences
Dans cette section, nous présentons la configuration expérimentale et les résultats, en nous appuyant sur l'infrastructure précédemment décrite.
Configuration expérimentale
Nous évaluons les modèles sur le jeu de données MATH-500 en utilisant la métrique pass@1 définie comme suit, et nous rapportons spécifiquement les résultats pour pass@1. Pendant l'évaluation, nous réglons la température d'échantillonnage à 0,7 et une valeur de top-𝑝 de 0,95 pour générer k lancements.
où 𝒫𝒾 désigne la justesse de la i-ème réponse. Les prompts de formation et d'évaluation sont listés ci-dessous, respectivement. Plus précisément, nous n'utilisons pas de prompt système, c'est-à-dire que les prompts suivants sont ajoutés au message utilisateur.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Les configurations expérimentales supplémentaires sont décrites ci-dessous.
SPÉCIFICATIONS DU MODÈLE
Nous avons principalement expérimenté avec des modèles Llama denses, sélectionnant nos modèles de base parmi les deux variantes suivantes en raison de leur taille appropriée et de leur adoption répandue au sein de la communauté de recherche. Ces modèles servent de références de base pour la performance en raisonnement dans nos expériences ultérieures :
Llama 3.1 8B Instruct
Llama 3.1 8B Base
DÉTAILS DES JEUX DE DONNÉES
Les jeux de données collectés et utilisés dans nos expériences sont décrits ci-dessous.
Sources | Taille | Modèles d'étiquetage | Difficulté | Utilisation |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B aperçu & R1 | Facile | Formation |
MATH | ~7k | QwQ 32B aperçu & R1 | Moyenne | Formation |
Orz (contient MATH) | ~57k | QwQ 32B aperçu & R1 | Difficile | Formation |
numinamath | ~250K (filtration) | Aucun | Difficile | Formation |
MATH-500 | 500 | Aucun | Moyenne | Évaluation |
PROCÉDURE D'ENTRAÎNEMENT
Cette sous-section décrit les méthodes d'entraînement spécifiques, notamment la sélection des hyper-paramètres, employées lors du réglage fin basé sur GRPO.
Hyperparamètres :
Nous avons utilisé le jeu de données GSM8K pour la formation dans cette sous-section.
Taux d'apprentissage (LR) et coefficient KL
Nous présentons les résultats de précision pour diverses combinaisons de taux d'apprentissage (LR) et de coefficients KL ci-dessous. (Notez que certaines expérimentations ont été interrompues prématurément en raison d'erreurs liées à l'infrastructure, entraînant de légères disparités dans le nombre total d'étapes d'entraînement.)
Taux d'apprentissage/coefficient KL | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
L'analyse de ces résultats indique qu'un taux d'apprentissage de 3e-7 démontre de manière constante une performance stable à travers différents réglages KL, il a donc été adopté pour les expériences principales. De plus, les expériences ont révélé de meilleurs résultats avec des valeurs KL plus basses, ce qui nous a amenés à supprimer totalement le terme KL lors des courses d'entraînement principales. Des taux d'apprentissage plus élevés comme 5e-7 et 8e-7 avaient tendance à accélérer la convergence précoce, limitant le développement des capacités de raisonnement en longue chaîne de pensée (CoT) à un stade avancé.
Température
Températures testées : [0.7 (rouge foncé), 0.8 (rouge), 1.0 (vert), 1.1 (mauve), 1.2 (bleu), 1.3 (gris)]
Les figures ci-dessous sont la précision de formation (à gauche) contre la précision de validation (à droite).
Température | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions :
Sur la base des résultats empiriques présentés ci-dessus, nous sélectionnons une température de 1,0 comme réglage par défaut, équilibrant la vitesse de convergence et la précision globale.
Les réglages de température plus élevés (par exemple, 1,2, 1,3) ont un impact négatif sur la convergence, entraînant une instabilité et l'échec à atteindre une performance satisfaisante.
Une température élevée, comme 1,2, 1,3, peut empêcher le modèle de converger
Alors que les valeurs de température plus basses (par exemple, 0,7, 0,8) facilitent une convergence initiale rapide, ces réglages conduisent généralement à une saturation prématurée, causant une amélioration limitée des performances sur le set de validation lors des étapes ultérieures de formation.
Modèles de récompense
Dans nos expériences préliminaires, nous avons évalué les deux modèles de récompense basés sur des règles proposés dans le document DeepSeek :
Récompense de précision : Cette fonction de récompense évalue la justesse de la sortie du modèle en comparant les réponses fournies par l'assistant avec les solutions de référence prédéfinies.
Récompense de format : Ce modèle de récompense encourage le modèle de langage à structurer ses réponses dans un format prédéfini et cohérent. Dans nos expériences, le format souhaité exige que les LLMs séparent explicitement le processus de raisonnement de la réponse finale en les incluant dans des balises XML-like spécifiques. Plus concrètement, le format attendu est montré dans
TRAINING_PROMPTlisté ci-dessus.
Résultats
Voici la configuration d'entraînement de nos expérimentations principales :
LR = 3e-7, coefficient KL = 0, Température = 1, uniquement la récompense de précision.
Résultat principal
La figure ci-dessous présente les résultats principaux de cette étude, montrant des comparaisons de précision de validation à travers trois conditions expérimentales :
Validation sur trois configurations RL: Gauche: entraînement à partir d'un modèle SFT-préchauffé ; Milieu: entraînement à partir de Llama 3.1 8B instruct ; Droite: entraînement à partir de Llama 3.1 8B Base
Les trois lignes illustrées dans la figure correspondent aux configurations suivantes
[Rouge] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle préchauffé et affiné de manière supervisée ORZ (4ème époque). Les données SFT sont étiquetées par le modèle QwQ-32B-aperçu, qui est un modèle de raisonnement CoT.
[Vert] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B instruct vanille.
[Bleu] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B base vanille.
Les résultats mettent en évidence deux conclusions clés :
RL a considérablement amélioré les capacités de raisonnement mathématique des modèles, comme en témoignent les améliorations de la précision de validation et des longueurs de génération accrues. (Notes : la précision de Llama 3.1 8B instruct et du modèle affiné selon ORZ est d'environ 0,38 et 0,60, respectivement. Le meilleur résultat RL, la ligne rouge dans le graphique ci-dessus, a atteint un score de 0,70 sur MATH500, ce qui correspond à des résultats similaires dans la littérature, par exemple, [1], [2])
L'exposition préalable aux données de raisonnement long-CoT lors du réglage supervisé ou de la phase de pré-entraînement a considérablement accéléré l'efficacité et l'efficacité du réglage fin RL ultérieur. D'après les courbes ci-dessus, il est clair que l'exposition long-CoT de SFT permet à la ligne rouge de commencer et de culminer beaucoup plus haut que les deux autres. (Note : Contrairement aux affirmations de certains articles, nos observations suggèrent que SFT améliore l'efficacité des étapes RL ultérieures. Bien que nous supposions que SFT peut également améliorer la performance maximale du modèle de base, nous n'avons pas encore suffisamment formé le modèle pour valider cette hypothèse de manière concluante.)
Analyse des phénomènes observés
Pendant nos expériences, nous avons observé plusieurs phénomènes remarquables que nous détaillons ici.
LE TAUX D'APPRENTISSAGE COMPTE
Nous avons constaté que le taux d'apprentissage dans GRPO contrôle généralement deux choses : 1) à quelle vitesse l'apprentissage s'amorce, et 2) à quel point la convergence est stable. Un taux d'apprentissage plus petit ralentit le progrès de l'apprentissage, ce qui est attendu. Cependant, avec un grand taux d'apprentissage, même si la courbe d'apprentissage monte rapidement lors des premières étapes, elle mène souvent à l'effondrement du modèle si elle est continuellement entraînée après convergence. Dans le graphique ci-dessous, les 3 lignes correspondent à 3 taux d'apprentissage différents :
Violet :
8e-7,Vert :
3e-7,Bleu :
1e-7.
Avec lr=8e-7, l'apprentissage plafonne très tôt, puis provoque l'effondrement du modèle (et la longueur des réponses explose) très rapidement. Avec lr=3e-7, l'apprentissage atteint le même niveau vers la fin des 15 000 étapes et est stable, tandis qu'avec lr=1e-7, l'apprentissage est trop lent, et la formation ne converge pas dans les 15 000 étapes. (Les trois courses utilisent l'optimiseur Adam, la plage de taux d'apprentissage est constante).
Récompense de validation (c'est-à-dire précision) de trois courses avec différents taux d'apprentissage : Violet : 8e-7, Vert : 3e-7 ; Bleu : 1e-7
Nous examinerons plus en avant pourquoi la courbe des récompenses s'effondre dans la section Effondrement du modèle.
EFFONDREMENT DU MODÈLE
Nous définissons l'effondrement du modèle comme la détérioration soudaine des capacités génératives d'un modèle pendant la formation RL. Cela se manifeste principalement sous deux formes au cours de nos expériences : effondrement par auto-répétition et effondrement de fin de séquence.
Effondrement par auto-répétition : Cette forme d'effondrement est apparue principalement dans les expériences incorporant une récompense de format. Initialement conçu pour guider le modèle vers la production de sorties bien structurées et interprétables, la récompense de format exige que le modèle organise ses réponses en utilisant des balises
<think></think>et<answer></answer>distinctes. Cependant, tout en promouvant la clarté structurelle, nous avons constaté que ce signal de récompense augmentait involontairement la probabilité d'effondrement par répétition.
Initialement, nous avons employé une récompense de format relativement lâche - nécessitant au moins un bloc <think> et un bloc <answer> - pour encourager l'adoption de la structure de réponse souhaitée. Dans l'exemple suivant, bien que la récompense finale converge bien, les lancements ont commencé à avoir de graves problèmes de répétition lorsque les étapes de formation dépassent 110.
Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format lâche
Un examen plus attentif des lancements révèle qu'après la convergence, le modèle génère un processus de réflexion normal (quelque chose sans les balises <think>), puis la réponse correcte, puis une répétition des blocs de format avec un contenu vide (voir l'exemple ci-dessous).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
Pour remédier à cela, nous avons expérimenté avec une récompense de format plus stricte exigeant exactement un bloc <think> suivi d'un bloc <answer>. Cependant, cet ajustement a aggravé le problème : non seulement la répétition a persisté, mais la précision des réponses s'est également détériorée [lien].
Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format stricte
Un exemple illustratif est joint ci-dessous :
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Sur la base de ces observations, nous avons initialement supposé que la récompense de format elle-même était la cause principale de l'effondrement. Pour tester cela, nous avons mené des expériences de suivi avec la récompense de format entièrement supprimée, ce qui nous amène à l'effondrement de fin de séquence suivant.
Effondrement de fin de séquence : cet effondrement se produit lorsque le modèle atteint la limite maximale de génération de tokens autorisée, entraînant ensuite une défaillance des performances.
Ce phénomène résulte probablement de scénarios de perte mal définis, où plusieurs sorties d'une seule requête d'entrée reçoivent uniformément des récompenses identiques. Cela se produit lorsque tous les lancements d'un prompt sont coupés, ce qui entraîne une récompense pour tous égale à 0, donc l'avantage est également 0. Examinons de plus près l'effondrement de la courbe de récompense exemple dans la section Le taux d'apprentissage compte. Dans ce cas, le coefficient KL est réglé sur 0. Pour les prompts dont tous les lancements sont coupés, il est impossible de faire sortir la politique de cet état, car le gradient de la politique devient 0 [voir Eq 2 dans la section Limites]. La précision mathématique commence à diminuer à mesure que de plus en plus de lancements sont coupés, puis reste coincée dans cette situation. Dans les graphiques suivants, nous pouvons voir une corrélation claire entre le taux de coupure et la baisse de la récompense rollout d'entraînement.
Effondrement de fin de séquence. L'effondrement de la récompense de la formation s'aligne avec la coupure du rollout
Notez que l'effondrement de fin de séquence est également observé dans Demystifying Long Chain-of-Thought Reasoning in LLMs, même avec le terme KL ajouté. Leur article a proposé une approche de mise en forme de récompense qui tente de contrôler la longueur de la séquence de déploiement. Cependant, nos expériences montrent que bien que la mise en forme des récompenses ait réussi à supprimer l'effondrement de la longueur (collapse de longueur), elle a empêché le modèle d'apprendre le raisonnement et la réponse corrects, ce qui a entraîné une précision mathématique beaucoup plus basse tout au long de la formation :
Précision de validation et longueur de réponse avec mise en forme des récompenses
Dans la section Limites, nous proposerons de nouvelles façons de gérer cette situation. En combinant l'exemple d'auto-répétition précédent et les résultats principaux ci-dessus, il semble qu'avec un modèle de base qui n'est pas exposé à des réponses de raisonnement en longue chaîne de pensée, RL amènerait le modèle à augmenter sa longueur de réponse de manière défectueuse et finalement s'effondrer par répétition.
CAPACITÉ DU MODÈLE DE BASE
Nous avons réalisé une étude d'ablation pour examiner l'impact de SFT sur la performance RL ultérieure. Les modèles ont d'abord été ajustés à l'aide d'ensembles de données de différents niveaux de difficulté - ORZ (difficile), MATH (moyen) et GSM8K (facile) - suivis d'un réglage RL exclusivement sur le jeu de données ORZ.
Précision de validation sur différents modèles initiaux
[Bleu] : SFT sur des données ORZ (difficulté : difficile) puis RL sur ORZ
[Rouge] : SFT sur des données MATH (difficulté : moyen) puis RL sur ORZ
[Vert] : SFT sur des données GSM8K (difficulté : facile) puis RL sur ORZ
Les résultats ont clairement indiqué que l'utilisation d'un mélange diversifié de niveaux de difficulté à l'étape SFT améliorait considérablement l'efficacité de la formation RL.
Les résultats de notre étude d'ablation suggèrent des directions de recherche futures précieuses, en particulier l'exploration de stratégies d'apprentissage continu.
Une approche potentielle consiste à examiner la conception de cursus au sein d'un domaine unique vs une capacité, en augmentant progressivement la complexité ou la difficulté pour améliorer progressivement la compétence du modèle.
Une autre direction intrigante implique l'exploration de stratégies de cursus qui couvrent plusieurs capacités ou domaines - par exemple, développer initialement des capacités de suivi d'instructions avant de progresser vers des tâches de raisonnement plus complexes.
Comprendre l'efficacité et l'interaction de ces stratégies d'apprentissage pourrait optimiser de manière significative l'efficacité de la formation et finalement améliorer les performances globales du modèle. (Ce genre de stratégie a été employé par QwQ 32B, comme illustré dans leur rapport technique).
MISE À L'ÉCHELLE DE LA LONGUEUR DE DÉPLOIEMENT
Comme observé ci-dessus ainsi que dans de nombreuses littératures (par exemple, R1), RL encourage intrinsèquement les déploiements à devenir plus longs (sauf si une récompense de contrôle de longueur spécifique est utilisée). Cependant, nous avons constaté que RL ne se contente pas d'augmenter aveuglément la longueur des déploiements - au contraire, il essaie de trouver une longueur optimale en fonction du modèle initial donné. Par exemple, le graphique vert ci-dessous montre la mise à l'échelle de la longueur en utilisant le modèle Llama 3.1 8B base, tandis que le graphique violet utilise le même modèle Llama 3.1 8B mais préchauffé sur les données ORZ étiquetées par un étiqueteur CoT (QwQ-32B-aperçu). Le premier modèle n'a pas été formé sur des données CoT du tout et à tendance à générer des réponses courtes dès le début. Pour atteindre une précision mathématique plus élevée, RL encourage le modèle à produire des réponses plus longues. D'un autre côté, le modèle suivant, en raison de l'effet SFT, a tendance à générer des réponses très longues dès le départ. RL a en fait supprimé la longueur de génération, tandis que la précision mathématique augmente également.
Mise à l'échelle de la longueur de déploiement avec un modèle initial différent: Llama 3.1 8B base (gauche) et Préchauffé SFT (droite)
Limites
La fonction de perte GRPO et les équations de mise à jour du gradient correspondantes sont fournies ci-dessous, mettant en évidence les biais potentiels introduits pendant les mises à jour de gradient.
BIAIS D'ESTIMATION DE L'AVANTAGE
Nous notons que la façon dont l'avantage Âᵢ,ₜ est estimé peut affecter de manière significative la formation du modèle. En particulier, la normalisation par l'écart-type des récompenses au niveau du groupe introduit deux problèmes clés :
Avantage diminuant pour des réponses uniformes. Lorsque toutes les réponses pour une requête donnée produisent des récompenses identiques, le gradient résultant devient zéro, causant l'échec de la mise à jour du modèle. Une solution proposée consiste à ajuster le calcul des récompenses comme suit :
Mise à l'échelle inégale du gradient entre les requêtes. Les requêtes avec une faible variance de récompense (typiquement les questions plus faciles) aboutissent à un plus grand Âᵢ,ₜ, conduisant à des estimations d'avantages disproportionnellement importantes et donc à des mises à jour de gradient plus fortes. En revanche, les requêtes plus difficiles (avec une variance élevée) contribuent moins à l'apprentissage. Cela introduit un biais dans la formation en faveur des exemples faciles.
Nous prévoyons d'essayer ces modifications supplémentaires au niveau des algorithmes dans nos prochaines étapes.
Conclusion
Dans ce travail, nous avons systématiquement exploré les approches d'apprentissage par renforcement (RL) pour améliorer le raisonnement mathématique dans les grands modèles de langage, en nous concentrant sur le développement et le déploiement de l'algorithme GRPO dans des infrastructures de formation RL modernes. Nos expériences démontrent que RL, en particulier lorsqu'il est initialisé à partir de modèles exposés à un raisonnement en longue chaîne de pensée (CoT) via un réglage fin supervisé, peut augmenter considérablement la précision du raisonnement mathématique et la qualité des réponses. Nous avons constaté que le choix du modèle de base et la diversité des données supervisées influencent de manière critique l'efficacité et la performance finale de RL. Bien que notre implémentation ait abordé des défis techniques clés — tels que l'efficacité des déploiements et l'alignement des probabilités logarithmiques — des problèmes tels que l'effondrement du modèle et le biais d'estimation des avantages restent des domaines ouverts pour une recherche plus poussée. Globalement, nos résultats fournissent une base solide pour les futurs travaux sur les stratégies de cursus et les améliorations algorithmiques, dans le but d'avancer les capacités de raisonnement mathématique à la pointe de la technologie dans les modèles de langage.
Entraînement RL pour le raisonnement mathématique
Introduction et Motivation
Les algorithmes d'apprentissage par renforcement (RL), en particulier l'optimisation de politique proximale (PPO) et l'optimisation de politique relative de groupe (GRPO), se sont révélés essentiels pour améliorer les capacités des modèles dans les tâches liées au raisonnement. Dans ce blog, nous souhaitons partager les enseignements et les raisonnements décisionnels que nous avons expérimentés lors du développement de l'infrastructure RL ainsi que de la formation de modèles de raisonnement mathématique avec RL. À des fins d'illustration, les résultats que nous montrons ci-dessous sont basés sur des modèles open source plus petits, mais la plupart d'entre eux s'appliquent également aux modèles plus grands.
L'objectif de l'exploration de la formation du modèle RL est double : 1) partager nos leçons et nos apprentissages sur la manière de former des modèles pour atteindre des performances de raisonnement mathématique à la pointe de la technologie. Cela équipe l'équipe avec les connaissances appropriées sur la manipulation des données, les recettes de mélange de données, les meilleures pratiques de formation, les subtilités des algorithmes RL et l'expérience générale d'optimisation des performances. 2) Appliquer ces apprentissages à des cas d'utilisation en production réelle pour améliorer les produits Perplexity.
Un résumé des principaux résultats :
Infrastructure : nous avons développé l'algorithme GRPO sur la bibliothèque torchtune ainsi que sur la suite Nemo, avec intégration du déroulement basé sur VLLM. Nemo sera notre infrastructure de prédilection à court terme pour la formation RL, tandis que nous développons le support torchtune GRPO, qui sera notre infrastructure préférée à long terme, pour un entretien autonome (aucune dépendance externe) ainsi qu'une architecture de cadre plus simple.
Jeu de données mathématiques utilisés : gsm8k, math, NuminaMath, Open Reasoning Zero (ORZ), séries AIME.
Formation du modèle de raisonnement mathématique :
Le mélange de données de différents niveaux de difficulté est important
RL prouve être capable d'améliorer davantage les capacités de raisonnement des modèles de langage de grande taille (LLM) au-delà du réglage fin supervisé (SFT)
La capacité du modèle de base est très importante. En particulier, la capacité long-CoT du modèle de base est importante pour une mise à l'échelle supplémentaire avec RL.
Un bon point de contrôle de départ SFT aide cela. Le SFT léger sert deux objectifs :
permettre au modèle de base RL d'être à l'aise avec la génération de réponses long-CoT. Sans cette capacité, lorsque RL force le modèle à augmenter la longueur de ses réponses, un effondrement de répétition pourrait se produire.
enseigner une certaine capacité de raisonnement au modèle de base, permettant au processus RL de commencer plus haut et d'apprendre plus rapidement dès le début, par rapport à un modèle qui ne sait générer que des réponses long-CoT avec une faible capacité de raisonnement.
Exploration de l'infrastructure de formation
Malgré la disponibilité de plusieurs cadres de formation RL open source, beaucoup ne conviennent pas à notre situation. Idéalement, nous voudrions les propriétés suivantes :
Bonne échelle avec les grandes tailles de modèles de nos modèles de production.
Bonnes optimisations de vitesse de formation.
Facile à implémenter de nouveaux algorithmes et à maintenir sans trop de dépendances externes.
Design d'architecture de cadre plus simple et extensible.
Idéalement, unifier avec le cadre de formation SFT.
Comparaison des cadres
Une comparaison des cadres que nous avons envisagés [la comparaison suivante a été faite en février 2025. Notez que de nombreux algorithmes manquants ont été implémentés plus tard.] :
Nous avons choisi Nemo Aligner comme option à court terme et avons éliminé le reste pour les raisons suivantes :
Nemo-Aligner : en raison des fonctionnalités les plus complètes déjà mises en œuvre, ainsi que du support de partenariat de Nvidia, nous avons choisi cette option comme notre principal focus à court terme. Cependant, le complexe de configuration avec des dépendances sur plusieurs dépôts ajoute un certain surcroît à l'entretien.
torchtune : il s'agit du cadre SFT que nous utilisons chez Perplexity. Le cadre est élégamment conçu et facile à étendre en général. Cependant, étant relativement nouveau, le cadre manque de nombreuses fonctionnalités à ajouter. Nous avons l'intention de nous transférer à torchtune pour RL à long terme. Une fois que nous aurons amené Nemo-aligner à un bon état, nous investirons dans le maintien d'une version interne de torchtune avec notre propre implémentation des algorithmes désirés.
VeRL : bien qu'il intègre à la fois le backend FSDP et le plus puissant Megatron-LM, le support de ce dernier est très limité en raison de la demande de la communauté étant principalement sur des modèles plus petits où FSDP est suffisant. FSDP a généralement un support plus faible pour le parallélisme de tenseur, ce qui est crucial pour les modèles plus grands, en particulier dans la formation RL. Cependant, VeRL est rapidement devenu un choix populaire pour la communauté et s'est développé de manière significative ces derniers mois. Compte tenu de ses arguments de vente sur les optimisations de débit et de plusieurs articles récents sur la formation de modèles de raisonnement/agence basés sur ce cadre (par exemple, [1], [2]), il vaut la peine de réévaluer cette option dans un avenir proche.
openRLHF : populaire dans la communauté académique. Cependant, le backend DeepSpeed le rend moins évolutif pour les grands modèles. Nous avons écarté cette option.
Développement et validation d'algorithmes
Dans cette section, nous fournissons d'abord une brève introduction à l'algorithme GRPO et discutons des améliorations techniques associées qui contribuent à la complexité de son implémentation. Ensuite, nous décrivons l'infrastructure développée pour relever ces défis.
Comparaison de PPO vs GRPO. Référence : https://arxiv.org/abs/2402.03300
PPO est un algorithme RL populaire largement utilisé pour le réglage fin des LLM en raison de sa simplicité et de son efficacité, comme illustré ci-dessus. Cependant, la dépendance de PPO sur un modèle de valeur séparé introduit une surcharge informatique et de mémoire significative.
Pour remédier à cette limitation, GRPO modifie PPO en supprimant le modèle de valeur séparé et en introduisant un calcul d'avantage basé sur des groupes, comme illustré dans la figure ci-dessus. Plus précisément, il génère plusieurs réponses candidates pour chaque question d'entrée, calcule leurs scores de récompense collectivement et détermine les avantages par rapport à ces résultats groupés. Bien qu'une telle innovation simplifie certains aspects, elle introduit de nouvelles complexités d'implémentation, telles que la génération efficace de multiples lancements de séquences longues.
Détails de l'implémentation
Bien que des algorithmes RL similaires (PPO, Reinforce) soient déjà en place dans Nemo-Aligner, il est étonnamment long de faire fonctionner GRPO correctement pour notre cas. Un résumé des améliorations que nous avons apportées comprend :
Implémentation de l'algorithme GRPO ;
Un estimateur de divergence KL plus robuste (détails) ;
Incorporer une récompense de format et des règles renforcées pour la précision mathématique (couvrant à la fois les réponses numériques et les expressions symboliques de référence) ;
Travailler avec l'équipe de support Nvidia pour intégrer le déroulement basé sur VLLM, qui a amélioré l'efficacité du déroulement de 30% et a également corrigé l'infrastructure TensorRT-LLM défaillante qui présentait un décalage des probabilités logarithmiques (voir point suivant)
Alignement des probabilités logarithmiques avec HF
Note : cet effort a été de loin le plus chronophage. Pour assurer la correction du code, nous adoptons la métrique suivante pour vérifier que les log-probabilités calculés de Nemo-Aligner sont corrects :
où L est la longueur d'un déroulement, le premier 𝓁𝑜𝑔𝓅ᵢ est la probabilité logarithmique du iᵉ token de Nemo-Aligner, et le second 𝓁𝑜𝑔𝓅'ᵢ est la probabilité logarithmique de référence que nous obtenons en exécutant manuellement model.forward sur un modèle Hugging Face directement. Cette métrique doit rester très proche de 1.0. Nous avons traversé plusieurs itérations de conversion de modèle nemo, mise à jour des dépôts et reconstruction d'image pour réduire la métrique de 1e5 à une plage normale de [1, 1.05].
Plusieurs séries de recherches d'hyper-paramètres pour optimiser la mémoire. En raison du fait que GRPO nécessite plusieurs échantillons par prompt, ainsi que les lancements de raisonnement mathématique sont généralement longs, nous rencontrons souvent des problèmes de mémoire insuffisante CUDA. Les hyper-paramètres, en particulier le paramètre de parallélisme, doivent être choisis avec soin pour assurer une formation fluide.
Problèmes mineurs liés à l'arrêt précoce de la consommation du dataloader et problèmes de forme de tenseur dans des cas limites.
Expériences
Dans cette section, nous présentons la configuration expérimentale et les résultats, en nous appuyant sur l'infrastructure précédemment décrite.
Configuration expérimentale
Nous évaluons les modèles sur le jeu de données MATH-500 en utilisant la métrique pass@1 définie comme suit, et nous rapportons spécifiquement les résultats pour pass@1. Pendant l'évaluation, nous réglons la température d'échantillonnage à 0,7 et une valeur de top-𝑝 de 0,95 pour générer k lancements.
où 𝒫𝒾 désigne la justesse de la i-ème réponse. Les prompts de formation et d'évaluation sont listés ci-dessous, respectivement. Plus précisément, nous n'utilisons pas de prompt système, c'est-à-dire que les prompts suivants sont ajoutés au message utilisateur.
# training prompt TRAINING_PROMPT = ( "A conversation between User and Assistant. The user asks a question, and the Assistant solves it. " "The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. " "The reasoning process and answer are enclosed within <think></think> and <answer></answer> tags, respectively, " "i.e., <think>reasoning process here</think> <answer>answer here</answer>. User: {question} Assistant: " )
# Evaluation prompt EVALUATION_PROMPT = ( "You will be given a problem.Please reason step by step, " "and put your final answer within \\boxed{}. " )
Les configurations expérimentales supplémentaires sont décrites ci-dessous.
SPÉCIFICATIONS DU MODÈLE
Nous avons principalement expérimenté avec des modèles Llama denses, sélectionnant nos modèles de base parmi les deux variantes suivantes en raison de leur taille appropriée et de leur adoption répandue au sein de la communauté de recherche. Ces modèles servent de références de base pour la performance en raisonnement dans nos expériences ultérieures :
Llama 3.1 8B Instruct
Llama 3.1 8B Base
DÉTAILS DES JEUX DE DONNÉES
Les jeux de données collectés et utilisés dans nos expériences sont décrits ci-dessous.
Sources | Taille | Modèles d'étiquetage | Difficulté | Utilisation |
|---|---|---|---|---|
Gsm8k | ~7k | QwQ 32B aperçu & R1 | Facile | Formation |
MATH | ~7k | QwQ 32B aperçu & R1 | Moyenne | Formation |
Orz (contient MATH) | ~57k | QwQ 32B aperçu & R1 | Difficile | Formation |
numinamath | ~250K (filtration) | Aucun | Difficile | Formation |
MATH-500 | 500 | Aucun | Moyenne | Évaluation |
PROCÉDURE D'ENTRAÎNEMENT
Cette sous-section décrit les méthodes d'entraînement spécifiques, notamment la sélection des hyper-paramètres, employées lors du réglage fin basé sur GRPO.
Hyperparamètres :
Nous avons utilisé le jeu de données GSM8K pour la formation dans cette sous-section.
Taux d'apprentissage (LR) et coefficient KL
Nous présentons les résultats de précision pour diverses combinaisons de taux d'apprentissage (LR) et de coefficients KL ci-dessous. (Notez que certaines expérimentations ont été interrompues prématurément en raison d'erreurs liées à l'infrastructure, entraînant de légères disparités dans le nombre total d'étapes d'entraînement.)
Taux d'apprentissage/coefficient KL | 0.1 | 0.01 | 0.001 |
|---|---|---|---|
8e-8 | 0.426 | 0.434 | 0.422 |
1e-7 | 0.432 | 0.492 | 0.414 |
3e-7 | 0.470 | 0.488 | 0.470 |
5e-7 | 0.444 | 0.48 | 0.486 |
L'analyse de ces résultats indique qu'un taux d'apprentissage de 3e-7 démontre de manière constante une performance stable à travers différents réglages KL, il a donc été adopté pour les expériences principales. De plus, les expériences ont révélé de meilleurs résultats avec des valeurs KL plus basses, ce qui nous a amenés à supprimer totalement le terme KL lors des courses d'entraînement principales. Des taux d'apprentissage plus élevés comme 5e-7 et 8e-7 avaient tendance à accélérer la convergence précoce, limitant le développement des capacités de raisonnement en longue chaîne de pensée (CoT) à un stade avancé.
Température
Températures testées : [0.7 (rouge foncé), 0.8 (rouge), 1.0 (vert), 1.1 (mauve), 1.2 (bleu), 1.3 (gris)]
Les figures ci-dessous sont la précision de formation (à gauche) contre la précision de validation (à droite).
Température | 0.7 | 0.8 | 1 | 1.1 | 1.2 | 1.3 |
|---|---|---|---|---|---|---|
Validation | 0.502 | 0.48 | 0.452 | 0.442 | 0.184 | 0.082 |
Conclusions :
Sur la base des résultats empiriques présentés ci-dessus, nous sélectionnons une température de 1,0 comme réglage par défaut, équilibrant la vitesse de convergence et la précision globale.
Les réglages de température plus élevés (par exemple, 1,2, 1,3) ont un impact négatif sur la convergence, entraînant une instabilité et l'échec à atteindre une performance satisfaisante.
Une température élevée, comme 1,2, 1,3, peut empêcher le modèle de converger
Alors que les valeurs de température plus basses (par exemple, 0,7, 0,8) facilitent une convergence initiale rapide, ces réglages conduisent généralement à une saturation prématurée, causant une amélioration limitée des performances sur le set de validation lors des étapes ultérieures de formation.
Modèles de récompense
Dans nos expériences préliminaires, nous avons évalué les deux modèles de récompense basés sur des règles proposés dans le document DeepSeek :
Récompense de précision : Cette fonction de récompense évalue la justesse de la sortie du modèle en comparant les réponses fournies par l'assistant avec les solutions de référence prédéfinies.
Récompense de format : Ce modèle de récompense encourage le modèle de langage à structurer ses réponses dans un format prédéfini et cohérent. Dans nos expériences, le format souhaité exige que les LLMs séparent explicitement le processus de raisonnement de la réponse finale en les incluant dans des balises XML-like spécifiques. Plus concrètement, le format attendu est montré dans
TRAINING_PROMPTlisté ci-dessus.
Résultats
Voici la configuration d'entraînement de nos expérimentations principales :
LR = 3e-7, coefficient KL = 0, Température = 1, uniquement la récompense de précision.
Résultat principal
La figure ci-dessous présente les résultats principaux de cette étude, montrant des comparaisons de précision de validation à travers trois conditions expérimentales :
Validation sur trois configurations RL: Gauche: entraînement à partir d'un modèle SFT-préchauffé ; Milieu: entraînement à partir de Llama 3.1 8B instruct ; Droite: entraînement à partir de Llama 3.1 8B Base
Les trois lignes illustrées dans la figure correspondent aux configurations suivantes
[Rouge] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle préchauffé et affiné de manière supervisée ORZ (4ème époque). Les données SFT sont étiquetées par le modèle QwQ-32B-aperçu, qui est un modèle de raisonnement CoT.
[Vert] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B instruct vanille.
[Bleu] Réglage fin RL sur le jeu de données ORZ initialisé à partir du point de contrôle Llama 3.1 8B base vanille.
Les résultats mettent en évidence deux conclusions clés :
RL a considérablement amélioré les capacités de raisonnement mathématique des modèles, comme en témoignent les améliorations de la précision de validation et des longueurs de génération accrues. (Notes : la précision de Llama 3.1 8B instruct et du modèle affiné selon ORZ est d'environ 0,38 et 0,60, respectivement. Le meilleur résultat RL, la ligne rouge dans le graphique ci-dessus, a atteint un score de 0,70 sur MATH500, ce qui correspond à des résultats similaires dans la littérature, par exemple, [1], [2])
L'exposition préalable aux données de raisonnement long-CoT lors du réglage supervisé ou de la phase de pré-entraînement a considérablement accéléré l'efficacité et l'efficacité du réglage fin RL ultérieur. D'après les courbes ci-dessus, il est clair que l'exposition long-CoT de SFT permet à la ligne rouge de commencer et de culminer beaucoup plus haut que les deux autres. (Note : Contrairement aux affirmations de certains articles, nos observations suggèrent que SFT améliore l'efficacité des étapes RL ultérieures. Bien que nous supposions que SFT peut également améliorer la performance maximale du modèle de base, nous n'avons pas encore suffisamment formé le modèle pour valider cette hypothèse de manière concluante.)
Analyse des phénomènes observés
Pendant nos expériences, nous avons observé plusieurs phénomènes remarquables que nous détaillons ici.
LE TAUX D'APPRENTISSAGE COMPTE
Nous avons constaté que le taux d'apprentissage dans GRPO contrôle généralement deux choses : 1) à quelle vitesse l'apprentissage s'amorce, et 2) à quel point la convergence est stable. Un taux d'apprentissage plus petit ralentit le progrès de l'apprentissage, ce qui est attendu. Cependant, avec un grand taux d'apprentissage, même si la courbe d'apprentissage monte rapidement lors des premières étapes, elle mène souvent à l'effondrement du modèle si elle est continuellement entraînée après convergence. Dans le graphique ci-dessous, les 3 lignes correspondent à 3 taux d'apprentissage différents :
Violet :
8e-7,Vert :
3e-7,Bleu :
1e-7.
Avec lr=8e-7, l'apprentissage plafonne très tôt, puis provoque l'effondrement du modèle (et la longueur des réponses explose) très rapidement. Avec lr=3e-7, l'apprentissage atteint le même niveau vers la fin des 15 000 étapes et est stable, tandis qu'avec lr=1e-7, l'apprentissage est trop lent, et la formation ne converge pas dans les 15 000 étapes. (Les trois courses utilisent l'optimiseur Adam, la plage de taux d'apprentissage est constante).
Récompense de validation (c'est-à-dire précision) de trois courses avec différents taux d'apprentissage : Violet : 8e-7, Vert : 3e-7 ; Bleu : 1e-7
Nous examinerons plus en avant pourquoi la courbe des récompenses s'effondre dans la section Effondrement du modèle.
EFFONDREMENT DU MODÈLE
Nous définissons l'effondrement du modèle comme la détérioration soudaine des capacités génératives d'un modèle pendant la formation RL. Cela se manifeste principalement sous deux formes au cours de nos expériences : effondrement par auto-répétition et effondrement de fin de séquence.
Effondrement par auto-répétition : Cette forme d'effondrement est apparue principalement dans les expériences incorporant une récompense de format. Initialement conçu pour guider le modèle vers la production de sorties bien structurées et interprétables, la récompense de format exige que le modèle organise ses réponses en utilisant des balises
<think></think>et<answer></answer>distinctes. Cependant, tout en promouvant la clarté structurelle, nous avons constaté que ce signal de récompense augmentait involontairement la probabilité d'effondrement par répétition.
Initialement, nous avons employé une récompense de format relativement lâche - nécessitant au moins un bloc <think> et un bloc <answer> - pour encourager l'adoption de la structure de réponse souhaitée. Dans l'exemple suivant, bien que la récompense finale converge bien, les lancements ont commencé à avoir de graves problèmes de répétition lorsque les étapes de formation dépassent 110.
Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format lâche
Un examen plus attentif des lancements révèle qu'après la convergence, le modèle génère un processus de réflexion normal (quelque chose sans les balises <think>), puis la réponse correcte, puis une répétition des blocs de format avec un contenu vide (voir l'exemple ci-dessous).
<|start_header_id|>assistant<|end_header_id|><think> Let's denote the positive integer as n. When n is expressed in base 8, it forms the number $AB_8$, which can be written as $8A + B$. When n is expressed in base 6, it forms the number $BA_6$, which can be written as $6B + A$. Since both expressions represent the same number n, we can set them equal to each other: $8A + B = 6B + A$ Subtracting A from both sides gives: $7A = 5B$ Dividing both sides by 7 gives: $A=\frac{5}{7}B$ Since A and B are digits, they must be integers. The only way for A to be an integer is if B is a multiple of 7. The smallest possible value of B that satisfies this condition is B = 7. Substituting B = 7 into the equation A = (5/7)B gives: $A=\frac{5}{7} \times 7 = 5$ Now that we have the values of A and B, we can find the decimal value of n. We know that n in base 8 is represented as 57, so the decimal value of n is: $8 \times 5 + 7 = 40 + 7 = 47$ Therefore, the positive integer in decimal is $\boxed{47}$. </think> </answer> </think> </answer> </think> </answer> </think> </answer> </think>
Pour remédier à cela, nous avons expérimenté avec une récompense de format plus stricte exigeant exactement un bloc <think> suivi d'un bloc <answer>. Cependant, cet ajustement a aggravé le problème : non seulement la répétition a persisté, mais la précision des réponses s'est également détériorée [lien].
Récompense de format de la validation (à gauche), précision mathématique (au milieu) et longueur du rollout (à droite) avec une récompense de format stricte
Un exemple illustratif est joint ci-dessous :
<|start_header_id|>assistant<|end_header_id|><think> To find the matrix $\mathbf{M}$, we can use the property of linear transformations that represents the transformation of vector $\mathbf{v}$ as $-4\mathbf{v}$. This means that the matrix $\mathbf{M}$ must be a scalar multiple of the identity matrix, where the scalar is $-4$. </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> ........ <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </think> <answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}} </answer> \boxed{\begin{pmatrix} -4 & 0 & 0 \\ 0 & -4 & 0 \\ 0 & 0 & -4 \end{pmatrix}}</answer>
Sur la base de ces observations, nous avons initialement supposé que la récompense de format elle-même était la cause principale de l'effondrement. Pour tester cela, nous avons mené des expériences de suivi avec la récompense de format entièrement supprimée, ce qui nous amène à l'effondrement de fin de séquence suivant.
Effondrement de fin de séquence : cet effondrement se produit lorsque le modèle atteint la limite maximale de génération de tokens autorisée, entraînant ensuite une défaillance des performances.
Ce phénomène résulte probablement de scénarios de perte mal définis, où plusieurs sorties d'une seule requête d'entrée reçoivent uniformément des récompenses identiques. Cela se produit lorsque tous les lancements d'un prompt sont coupés, ce qui entraîne une récompense pour tous égale à 0, donc l'avantage est également 0. Examinons de plus près l'effondrement de la courbe de récompense exemple dans la section Le taux d'apprentissage compte. Dans ce cas, le coefficient KL est réglé sur 0. Pour les prompts dont tous les lancements sont coupés, il est impossible de faire sortir la politique de cet état, car le gradient de la politique devient 0 [voir Eq 2 dans la section Limites]. La précision mathématique commence à diminuer à mesure que de plus en plus de lancements sont coupés, puis reste coincée dans cette situation. Dans les graphiques suivants, nous pouvons voir une corrélation claire entre le taux de coupure et la baisse de la récompense rollout d'entraînement.
Effondrement de fin de séquence. L'effondrement de la récompense de la formation s'aligne avec la coupure du rollout
Notez que l'effondrement de fin de séquence est également observé dans Demystifying Long Chain-of-Thought Reasoning in LLMs, même avec le terme KL ajouté. Leur article a proposé une approche de mise en forme de récompense qui tente de contrôler la longueur de la séquence de déploiement. Cependant, nos expériences montrent que bien que la mise en forme des récompenses ait réussi à supprimer l'effondrement de la longueur (collapse de longueur), elle a empêché le modèle d'apprendre le raisonnement et la réponse corrects, ce qui a entraîné une précision mathématique beaucoup plus basse tout au long de la formation :
Précision de validation et longueur de réponse avec mise en forme des récompenses
Dans la section Limites, nous proposerons de nouvelles façons de gérer cette situation. En combinant l'exemple d'auto-répétition précédent et les résultats principaux ci-dessus, il semble qu'avec un modèle de base qui n'est pas exposé à des réponses de raisonnement en longue chaîne de pensée, RL amènerait le modèle à augmenter sa longueur de réponse de manière défectueuse et finalement s'effondrer par répétition.
CAPACITÉ DU MODÈLE DE BASE
Nous avons réalisé une étude d'ablation pour examiner l'impact de SFT sur la performance RL ultérieure. Les modèles ont d'abord été ajustés à l'aide d'ensembles de données de différents niveaux de difficulté - ORZ (difficile), MATH (moyen) et GSM8K (facile) - suivis d'un réglage RL exclusivement sur le jeu de données ORZ.
Précision de validation sur différents modèles initiaux
[Bleu] : SFT sur des données ORZ (difficulté : difficile) puis RL sur ORZ
[Rouge] : SFT sur des données MATH (difficulté : moyen) puis RL sur ORZ
[Vert] : SFT sur des données GSM8K (difficulté : facile) puis RL sur ORZ
Les résultats ont clairement indiqué que l'utilisation d'un mélange diversifié de niveaux de difficulté à l'étape SFT améliorait considérablement l'efficacité de la formation RL.
Les résultats de notre étude d'ablation suggèrent des directions de recherche futures précieuses, en particulier l'exploration de stratégies d'apprentissage continu.
Une approche potentielle consiste à examiner la conception de cursus au sein d'un domaine unique vs une capacité, en augmentant progressivement la complexité ou la difficulté pour améliorer progressivement la compétence du modèle.
Une autre direction intrigante implique l'exploration de stratégies de cursus qui couvrent plusieurs capacités ou domaines - par exemple, développer initialement des capacités de suivi d'instructions avant de progresser vers des tâches de raisonnement plus complexes.
Comprendre l'efficacité et l'interaction de ces stratégies d'apprentissage pourrait optimiser de manière significative l'efficacité de la formation et finalement améliorer les performances globales du modèle. (Ce genre de stratégie a été employé par QwQ 32B, comme illustré dans leur rapport technique).
MISE À L'ÉCHELLE DE LA LONGUEUR DE DÉPLOIEMENT
Comme observé ci-dessus ainsi que dans de nombreuses littératures (par exemple, R1), RL encourage intrinsèquement les déploiements à devenir plus longs (sauf si une récompense de contrôle de longueur spécifique est utilisée). Cependant, nous avons constaté que RL ne se contente pas d'augmenter aveuglément la longueur des déploiements - au contraire, il essaie de trouver une longueur optimale en fonction du modèle initial donné. Par exemple, le graphique vert ci-dessous montre la mise à l'échelle de la longueur en utilisant le modèle Llama 3.1 8B base, tandis que le graphique violet utilise le même modèle Llama 3.1 8B mais préchauffé sur les données ORZ étiquetées par un étiqueteur CoT (QwQ-32B-aperçu). Le premier modèle n'a pas été formé sur des données CoT du tout et à tendance à générer des réponses courtes dès le début. Pour atteindre une précision mathématique plus élevée, RL encourage le modèle à produire des réponses plus longues. D'un autre côté, le modèle suivant, en raison de l'effet SFT, a tendance à générer des réponses très longues dès le départ. RL a en fait supprimé la longueur de génération, tandis que la précision mathématique augmente également.
Mise à l'échelle de la longueur de déploiement avec un modèle initial différent: Llama 3.1 8B base (gauche) et Préchauffé SFT (droite)
Limites
La fonction de perte GRPO et les équations de mise à jour du gradient correspondantes sont fournies ci-dessous, mettant en évidence les biais potentiels introduits pendant les mises à jour de gradient.
BIAIS D'ESTIMATION DE L'AVANTAGE
Nous notons que la façon dont l'avantage Âᵢ,ₜ est estimé peut affecter de manière significative la formation du modèle. En particulier, la normalisation par l'écart-type des récompenses au niveau du groupe introduit deux problèmes clés :
Avantage diminuant pour des réponses uniformes. Lorsque toutes les réponses pour une requête donnée produisent des récompenses identiques, le gradient résultant devient zéro, causant l'échec de la mise à jour du modèle. Une solution proposée consiste à ajuster le calcul des récompenses comme suit :
Mise à l'échelle inégale du gradient entre les requêtes. Les requêtes avec une faible variance de récompense (typiquement les questions plus faciles) aboutissent à un plus grand Âᵢ,ₜ, conduisant à des estimations d'avantages disproportionnellement importantes et donc à des mises à jour de gradient plus fortes. En revanche, les requêtes plus difficiles (avec une variance élevée) contribuent moins à l'apprentissage. Cela introduit un biais dans la formation en faveur des exemples faciles.
Nous prévoyons d'essayer ces modifications supplémentaires au niveau des algorithmes dans nos prochaines étapes.
Conclusion
Dans ce travail, nous avons systématiquement exploré les approches d'apprentissage par renforcement (RL) pour améliorer le raisonnement mathématique dans les grands modèles de langage, en nous concentrant sur le développement et le déploiement de l'algorithme GRPO dans des infrastructures de formation RL modernes. Nos expériences démontrent que RL, en particulier lorsqu'il est initialisé à partir de modèles exposés à un raisonnement en longue chaîne de pensée (CoT) via un réglage fin supervisé, peut augmenter considérablement la précision du raisonnement mathématique et la qualité des réponses. Nous avons constaté que le choix du modèle de base et la diversité des données supervisées influencent de manière critique l'efficacité et la performance finale de RL. Bien que notre implémentation ait abordé des défis techniques clés — tels que l'efficacité des déploiements et l'alignement des probabilités logarithmiques — des problèmes tels que l'effondrement du modèle et le biais d'estimation des avantages restent des domaines ouverts pour une recherche plus poussée. Globalement, nos résultats fournissent une base solide pour les futurs travaux sur les stratégies de cursus et les améliorations algorithmiques, dans le but d'avancer les capacités de raisonnement mathématique à la pointe de la technologie dans les modèles de langage.
Partagez cet article