

Écrit par
Équipe Perplexity
Publié le
Search API : extraction améliorée, benchmarks dynamiques
En septembre, nous avons publié une vue d'ensemble technique de l'architecture de la Search API de Perplexity et lancé search_evals, notre cadre d'évaluation open source destiné au benchmarking des API de recherche dans des workflows agentiques. Depuis, l'investissement le plus important a porté sur la qualité des extraits, optimisée selon deux dimensions : la pertinence et la taille. Renvoyer le bon contenu dans la bonne quantité détermine directement la précision des réponses en aval et l'efficacité des tokens. Pour y parvenir, il a fallu construire de nouveaux systèmes d'extraction, d'étiquetage au niveau des segments et d'évaluation, notamment un pipeline d'étiquetage des segments qui identifie quelles parties d'un document source répondent à une requête donnée.
Évaluer les extraits au niveau des segments
Pour améliorer les extraits de manière systématique, nous avons conçu un nouveau système d'évaluation. Pour une requête et un document donnés, le système identifie et étiquette des segments au sein du document selon leur relation avec la requête : les segments « essentiels » qui doivent être inclus dans l'extrait, diverses classes de segments « non pertinents » qui doivent être exclus, les doublons et d'autres catégories. Cet étiquetage au niveau des segments nous permet d'évaluer la qualité des extraits avec un degré de précision qui n'était auparavant pas possible, en mesurant à la fois ce qui a été correctement inclus et ce qui a été correctement omis.
En pratique, ces améliorations nous permettent de générer des extraits plus courts et plus pertinents pour la requête. Notre pipeline auto-améliorant de compréhension du contenu prend désormais en charge un éventail plus large de formats de données structurées, notamment les tableaux, les listes imbriquées et les contenus rendus dynamiquement que les anciens jeux de règles ne parvenaient pas à analyser de manière fiable.
Ces améliorations sont issues de nos propres systèmes de production. À mesure que nos recherches internes faisaient progresser la pertinence et la taille des extraits, les évaluations internes ont montré qu'après une série d'améliorations de qualité, des budgets de contenu plus réduits produisaient en réalité des résultats plus précis. Nous avons apporté quelques modifications à nos configurations par défaut pour refléter ces constats, en réduisant la taille des charges utiles de réponse et la latence tout en fournissant un contenu plus utile par résultat. Pour les développeurs, des extraits plus courts et plus pertinents se traduisent directement par des coûts de tokens plus faibles et une meilleure gestion du contexte pour les LLM en aval.
SEAL : benchmarking de la recherche sensible au temps
Le benchmark SEAL teste si un système de recherche peut répondre à des questions dont la bonne réponse évolue dans le temps. Répondre de manière fiable exige une fraîcheur de l'index en temps réel, une extraction plus intelligente des extraits à partir de diverses sources de données mises à jour en continu, ainsi qu'une analyse capable d'identifier la valeur actuelle plutôt qu'une valeur historique.
Lorsque nous avons exécuté search_evals sur la version du 22 février de SEAL avec Claude Sonnet 4.5, les scores de Perplexity ont augmenté tandis que ceux des autres fournisseurs ont reculé sur SEAL-Hard :
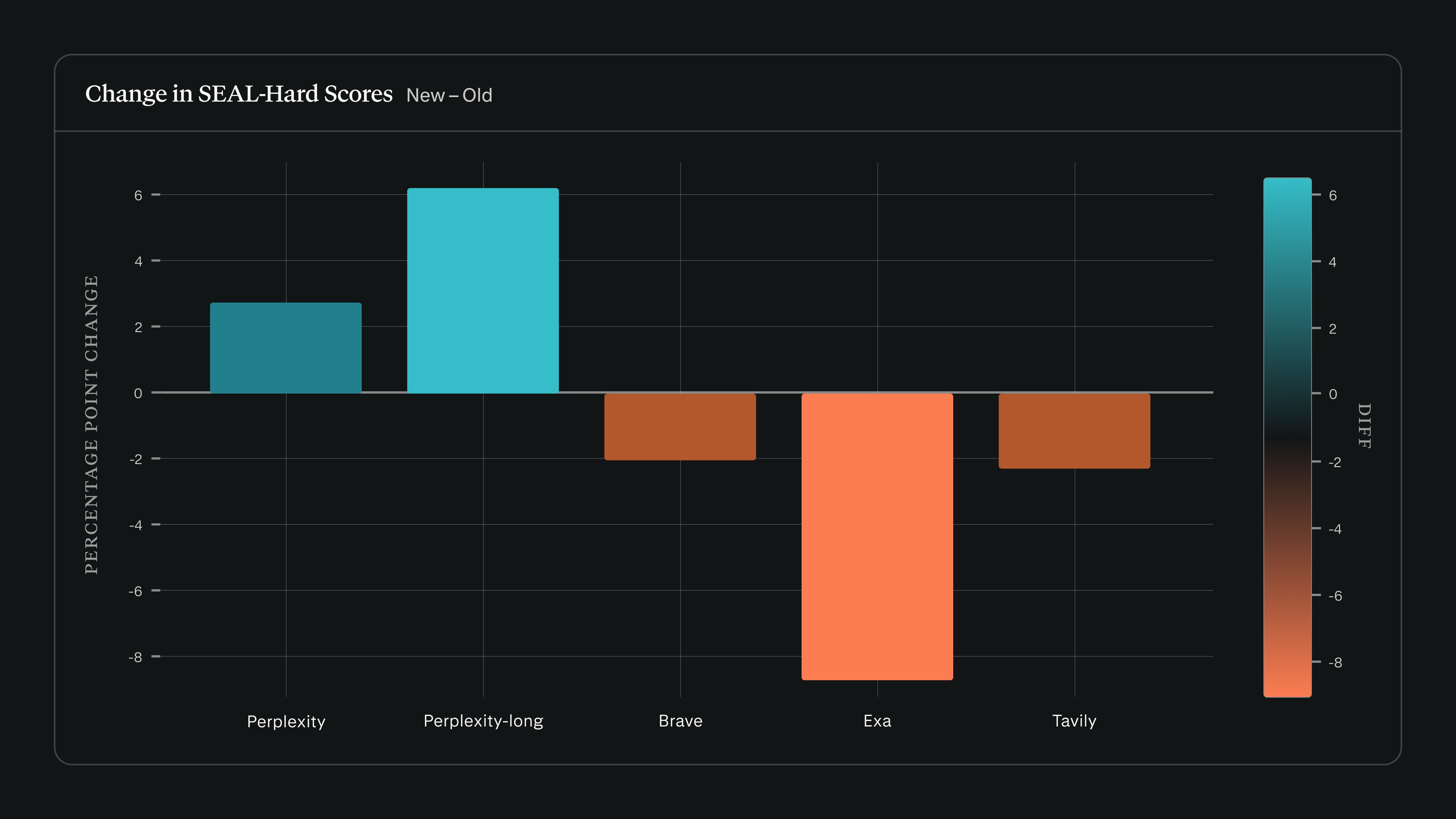
Nous avons étendu notre cadre search_evals pour y inclure SEAL, aux côtés des benchmarks présentés dans notre article de septembre. Les résultats et la méthodologie mis à jour sont disponibles dans le référentiel mis à jour sur GitHub.
Prise en charge multi-requêtes
L'API prend désormais en charge jusqu'à 5 requêtes dans une seule demande. Les résultats sont renvoyés regroupés par requête dans le même ordre que celui de leur soumission. Cela réduit les allers-retours pour les applications qui doivent lancer en parallèle des recherches liées, comme les agents qui décomposent une question complexe en plusieurs sous-tâches de recherche.
Filtrage étendu
En plus du filtrage par domaine (liste d'autorisation et liste de refus, jusqu'à 20 domaines) et du filtrage par récence, l'API prend désormais en charge le filtrage par langue via le code ISO 639-1 et la recherche régionale via le code pays ISO. Ceux-ci peuvent être combinés pour circonscrire précisément les résultats, par exemple en les limitant à des résultats en anglais provenant de domaines allemands.
SDK et disponibilité
Le SDK Python (pip install perplexityai) prend désormais nativement en charge Search API aux côtés d'Agent API et de Sonar API.
La documentation complète se trouve sur docs.perplexity.ai
Search API : extraction améliorée, benchmarks dynamiques
En septembre, nous avons publié une vue d'ensemble technique de l'architecture de la Search API de Perplexity et lancé search_evals, notre cadre d'évaluation open source destiné au benchmarking des API de recherche dans des workflows agentiques. Depuis, l'investissement le plus important a porté sur la qualité des extraits, optimisée selon deux dimensions : la pertinence et la taille. Renvoyer le bon contenu dans la bonne quantité détermine directement la précision des réponses en aval et l'efficacité des tokens. Pour y parvenir, il a fallu construire de nouveaux systèmes d'extraction, d'étiquetage au niveau des segments et d'évaluation, notamment un pipeline d'étiquetage des segments qui identifie quelles parties d'un document source répondent à une requête donnée.
Évaluer les extraits au niveau des segments
Pour améliorer les extraits de manière systématique, nous avons conçu un nouveau système d'évaluation. Pour une requête et un document donnés, le système identifie et étiquette des segments au sein du document selon leur relation avec la requête : les segments « essentiels » qui doivent être inclus dans l'extrait, diverses classes de segments « non pertinents » qui doivent être exclus, les doublons et d'autres catégories. Cet étiquetage au niveau des segments nous permet d'évaluer la qualité des extraits avec un degré de précision qui n'était auparavant pas possible, en mesurant à la fois ce qui a été correctement inclus et ce qui a été correctement omis.
En pratique, ces améliorations nous permettent de générer des extraits plus courts et plus pertinents pour la requête. Notre pipeline auto-améliorant de compréhension du contenu prend désormais en charge un éventail plus large de formats de données structurées, notamment les tableaux, les listes imbriquées et les contenus rendus dynamiquement que les anciens jeux de règles ne parvenaient pas à analyser de manière fiable.
Ces améliorations sont issues de nos propres systèmes de production. À mesure que nos recherches internes faisaient progresser la pertinence et la taille des extraits, les évaluations internes ont montré qu'après une série d'améliorations de qualité, des budgets de contenu plus réduits produisaient en réalité des résultats plus précis. Nous avons apporté quelques modifications à nos configurations par défaut pour refléter ces constats, en réduisant la taille des charges utiles de réponse et la latence tout en fournissant un contenu plus utile par résultat. Pour les développeurs, des extraits plus courts et plus pertinents se traduisent directement par des coûts de tokens plus faibles et une meilleure gestion du contexte pour les LLM en aval.
SEAL : benchmarking de la recherche sensible au temps
Le benchmark SEAL teste si un système de recherche peut répondre à des questions dont la bonne réponse évolue dans le temps. Répondre de manière fiable exige une fraîcheur de l'index en temps réel, une extraction plus intelligente des extraits à partir de diverses sources de données mises à jour en continu, ainsi qu'une analyse capable d'identifier la valeur actuelle plutôt qu'une valeur historique.
Lorsque nous avons exécuté search_evals sur la version du 22 février de SEAL avec Claude Sonnet 4.5, les scores de Perplexity ont augmenté tandis que ceux des autres fournisseurs ont reculé sur SEAL-Hard :
Nous avons étendu notre cadre search_evals pour y inclure SEAL, aux côtés des benchmarks présentés dans notre article de septembre. Les résultats et la méthodologie mis à jour sont disponibles dans le référentiel mis à jour sur GitHub.
Prise en charge multi-requêtes
L'API prend désormais en charge jusqu'à 5 requêtes dans une seule demande. Les résultats sont renvoyés regroupés par requête dans le même ordre que celui de leur soumission. Cela réduit les allers-retours pour les applications qui doivent lancer en parallèle des recherches liées, comme les agents qui décomposent une question complexe en plusieurs sous-tâches de recherche.
Filtrage étendu
En plus du filtrage par domaine (liste d'autorisation et liste de refus, jusqu'à 20 domaines) et du filtrage par récence, l'API prend désormais en charge le filtrage par langue via le code ISO 639-1 et la recherche régionale via le code pays ISO. Ceux-ci peuvent être combinés pour circonscrire précisément les résultats, par exemple en les limitant à des résultats en anglais provenant de domaines allemands.
SDK et disponibilité
Le SDK Python (pip install perplexityai) prend désormais nativement en charge Search API aux côtés d'Agent API et de Sonar API.
La documentation complète se trouve sur docs.perplexity.ai
Partagez cet article