

Napisao
AI tim
Objavljeno na
Ubrzavanje Sonara kroz Spekulaciju
Spekulativno dekodiranje ubrzava brzinu generacije Velikih Jezičnih Modela (LLM-ova) koristeći brzi i mali model za izradu kandidata za dovršetak koji se potvrđuju većim ciljnim modelom. Prema ovom načinu rada, umjesto da skupi skupi model proizvodi jedan token, više ih se ispušta u jednom koraku. Ovdje predstavljamo detalje implementacije različitih vrsta spekulativnog dekodiranja, primijenjenih u Perplexity za smanjenje kašnjenja između tokena na Sonar modelima.
Spekulativno Dekodiranje
Spekulativno dekodiranje koristi strukturu prirodnih jezika i automatski regresivnu prirodu transformatora za ubrzanje generacije tokena. Iako veći modeli, poput Llama-70B, posjeduju više znanja od manjih, poput Llama-1B, u nekim jednostavnijim zadacima ostvaruju slične rezultate. Ova preklapanja sugeriraju da određene sekvence bolje generiraju manje skupi modeli, prepuštajući složenije probleme većim modelima. Izazov je utvrditi koji su završeci bolji i je li generacija manjeg modela jednake kvalitete kao ona većeg.
Srećom, LLM-ovi su automatski regresivni transformatori: kada se da niz tokena, oni ispuštaju vjerojatnosnu distribuciju sljedećeg tokena. Dodatno,_logits_ izvedeni iz srednjih značajki povezanih s tokenima u ulaznom nizu također ukazuju koliko je vjerojatno da model izda te točne tokene. Ova osobina omogućava spekulaciju: ako niz tokena generira manji model počinjući od ulaznog prefiksa, može se provjeriti kroz veći model da se utvrdi koliko dobro se poklapa s ciljnim modelom. Svaki prefiks kandidata ocjenjuje se s vjerojatnošću, a najduži iznad praga prihvaćanja bira se. Kao bonus, ciljni model također osigurava sljedeći token besplatno: ako model za izradu generira n tokene, do n + 1 može se emitirati u jednom koraku.
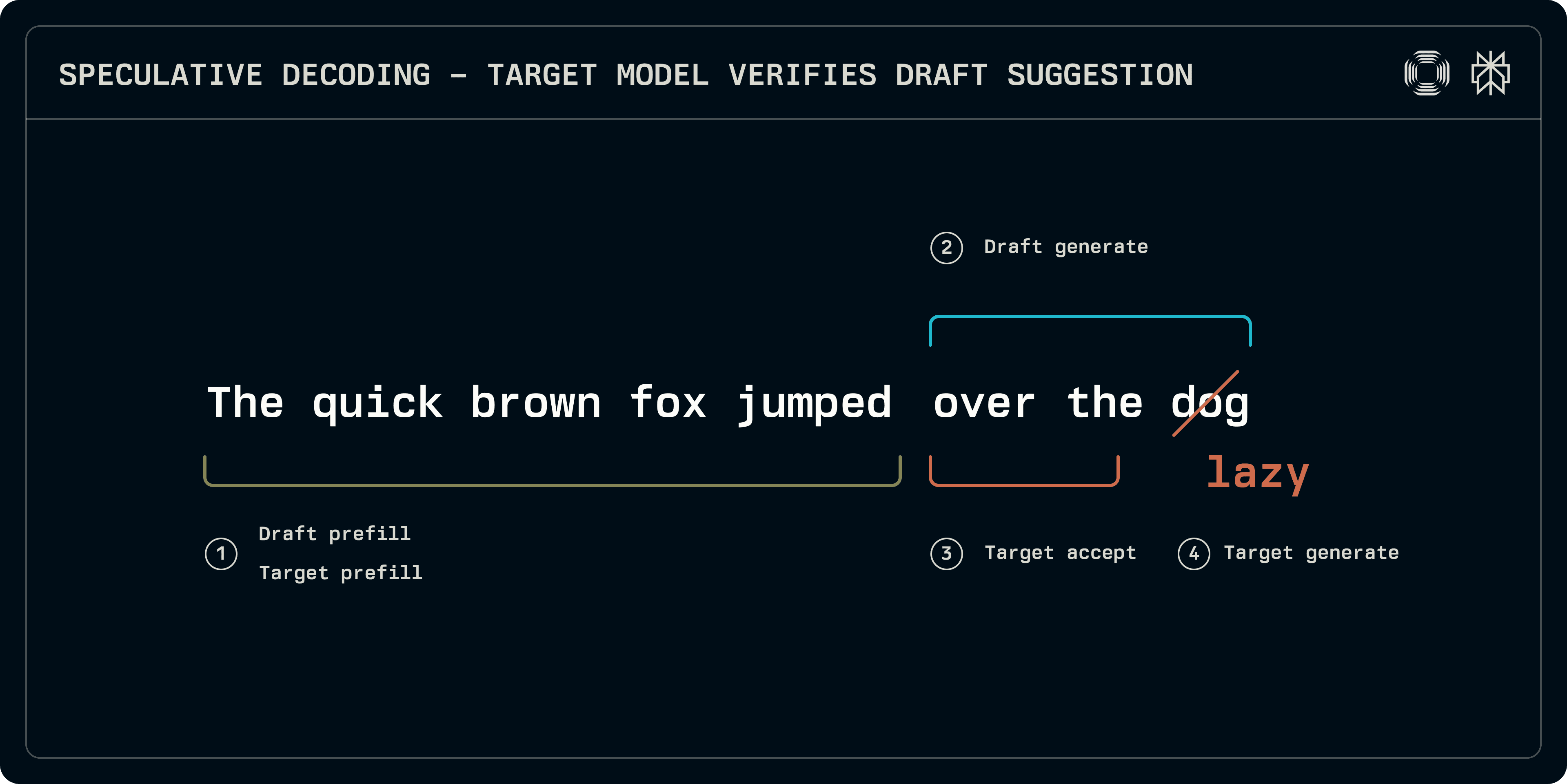
U trenutku inferencije, proces spekulativnog uzorkovanja može se podijeliti otprilike u 4 faze:
Prefill: i ciljni i modeli za izradu moraju se pokrenuti na ulaznom nizu kako bi popunili unose u KV predmemoriji. Dok neki sustavi, poput Meduse, koriste jednostavnije guste slojeve za predikciju, u ovom postu se fokusiramo na transformatorima temeljenim na nacrtima koji trebaju vlastite KV predmemorije.
Generacija nacrta: model za izradu iterira kako bi proizveo određeni broj fiksnih tokena. Niz nacrta može biti linearni ili model može istražiti strukturu nalik stablu do zadanih dubina (EAGLE, Medusa). Ovdje se fokusiramo na linearne nizove.
Prihvaćanje: ciljni model radi na nizu nacrta, stvarajući logits koji odgovaraju svakom tokenu nacrta. Duljina najdužeg prihvatljivog niza se utvrđuje.
Generacija cilja: budući da ciljni generira logits, na nepodudarnim pozicijama ili na kraju niza, logits odgovaraju sljedećem tokenu. Ovi logits mogu se uzorkovati kako bi se osigurao robusni token iz cilja, završavajući niz.
Različite metode postoje za implementaciju spekulativnog dekodiranja. U ovom postu, fokusirat ćemo se na sheme koje smo koristili za ubrzanje Sonar modela koristeći vlastiti model od 1B, kao i mehanizme predikcije koje gradimo kako bismo ubrzali modele na razini DeepSeeka.
Cilj-Nacrt
Spekulativno dekodiranje može se postići povezivanjem postojećeg malog LLM-a kao modela za izradu s ciljnim modelom za generiranje kandidat sekvenci. U produkciji, ubrzali smo Sonar koristeći Llama-1B model fino prilagođen na istom skupu podataka kao cilj. Dok ovaj pristup nije zahtijevao obuku nacrta od nule, mali model i dalje koristi značajne kapacitete KV predmemorije i unosi mali prefiltration overhead, povećavajući TTFT.
Prema ovom sustavu, dekoder samo spekulira o dekodiranim serijama, stvarajući tokena kroz standardno uzorkovanje tijekom prefiltration ili na mješovitim prefiltration-dekodiranim serijama. U fazi prefiltriranja, ciljni logits se odmah uzorkuju kako bi se također prepunila novom generiranom tokenu u KV predmemoriji nacrta. Nacrt još nije uzorkovan, ali logits koje proizvodi se prenose u fazu dekodiranja.
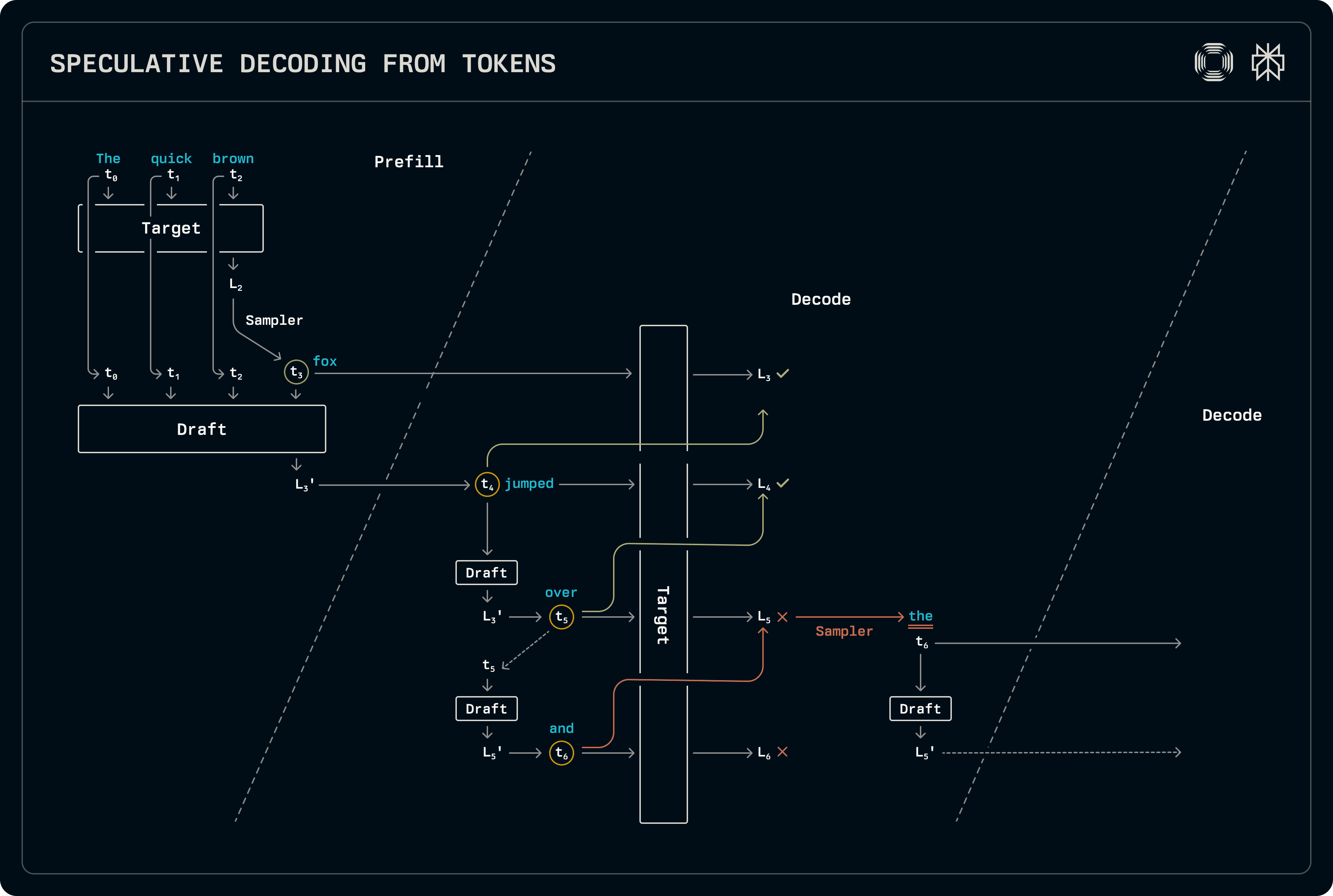
U dekodiranju, model za izradu napreduje, uzorkujući najbolji token u svakoj fazi. Nakon što se postigne željena duljina nacrta, tokeni se provode kroz ciljni model kako bi proizveli logits na temelju kojih uzorkivač identificira prihvaćenu duljinu sekvence. Prihvaćanje se određuje usporedbom cjelokupnih vjerojatnosnih distribucija iz nacrta i cilja. Budući da ciljni uvijek ispušta jedan skup logits nakon prihvaćene sekvence nacrta, to se uzorkuje za dodatni izlaz. Budući da model za izradu još nije vidio taj prihvaćeni token, ponovno se pokreće kako bi popunio odgovarajuće unose KV predmemorije u pripremi za sljedeći dekodirajući korak, ponovo prenosivši logits.
EAGLE
EAGLE je spekulativna shema dekodiranja koja istražuje više sekvenci nacrta, generiranih kroz stablo nalik rasvjeti vjerojatnih tokena nacrta. Fiksno (EAGLE) ili dinamički oblikovano (EAGLE-2) stablo se istražuje korištenjem uzastopnih izvršavanja tokena nacrta, uzimajući u obzir Top-K kandidate na svakoj čvoru umjesto da slijedi najvišu ocjenu tokena u linearnoj sekvenci. Sekvence se zatim ocjenjuju, a najduža prikladna se odabire za nastavak, a također se dodaje dodatni token iz cilja.

Kako bi se postigla točnija predikcija, EAGLE model nacrta predviđa ne samo na temelju tokena, već i koristeći ciljne značajke (završne skrivene stanje) ciljnog modela. Nedostatak EAGLE-a je potreba za treniranjem prilagođenih, malih modela nacrta koji su dovoljno točni da generiraju prikladne kandidate unutar razumnog proračuna latencije. Tipično, model nacrta je jedan sloj transformatora koji je identičan sloju dekodera izvornog modela, koji je čvrsto povezan s ciljem vezujući se za svoje ugradnje i lm_head projekcije. Budući da to zahtijeva manje kapaciteta KV predmemorije, EAGLE ima manju potrošnju memorije.
Za provjeru sekvenci nalik stablu u ciljnog modela, moraju se koristiti prilagođene maske pažnje. Nažalost, korištenje prilagođene maske pažnje za cijeli niz značajno usporava pažnju za realne ulazne duljine (do 50%), poništavajući dio ubrzanja koje se može postići spekulacijom. Iz tog razloga još nismo implementirali potpuno istraživanje stabla u proizvodnji, već se fokusiramo na posebni slučaj predikcije jednog tokena putem MTP-sličnih shema predstavljenih u Tehničkom Izvještaju DeepSeek-V3.
MTP
Ova shema je slična dekodiranju nacrta-cilja, uz izuzetak da se skrivene stanja koriste zajedno s tokenima za predikciju. Malo više posla mora se obaviti u fazama prefiltriranja i dekodiranja u usporedbi s redovnim spekulacijama nacrta-cilja. Model za izradu koristi i tokene i skrivene stanja: token t_{i+1} uzorkuje se iz logits L_i koji odgovaraju tokenu t_i, koji se pak postavljaju iz skrivenih stanja H_i. Posljedično, ulazni tokeni moraju se pomaknuti jedno korak lijevo u odnosu na vektore skrivenih stanja koje odgovara cilju. Slika ispod označava odgovarajuće upotrebe za obuku, kao i pomak tijekom inferencije.
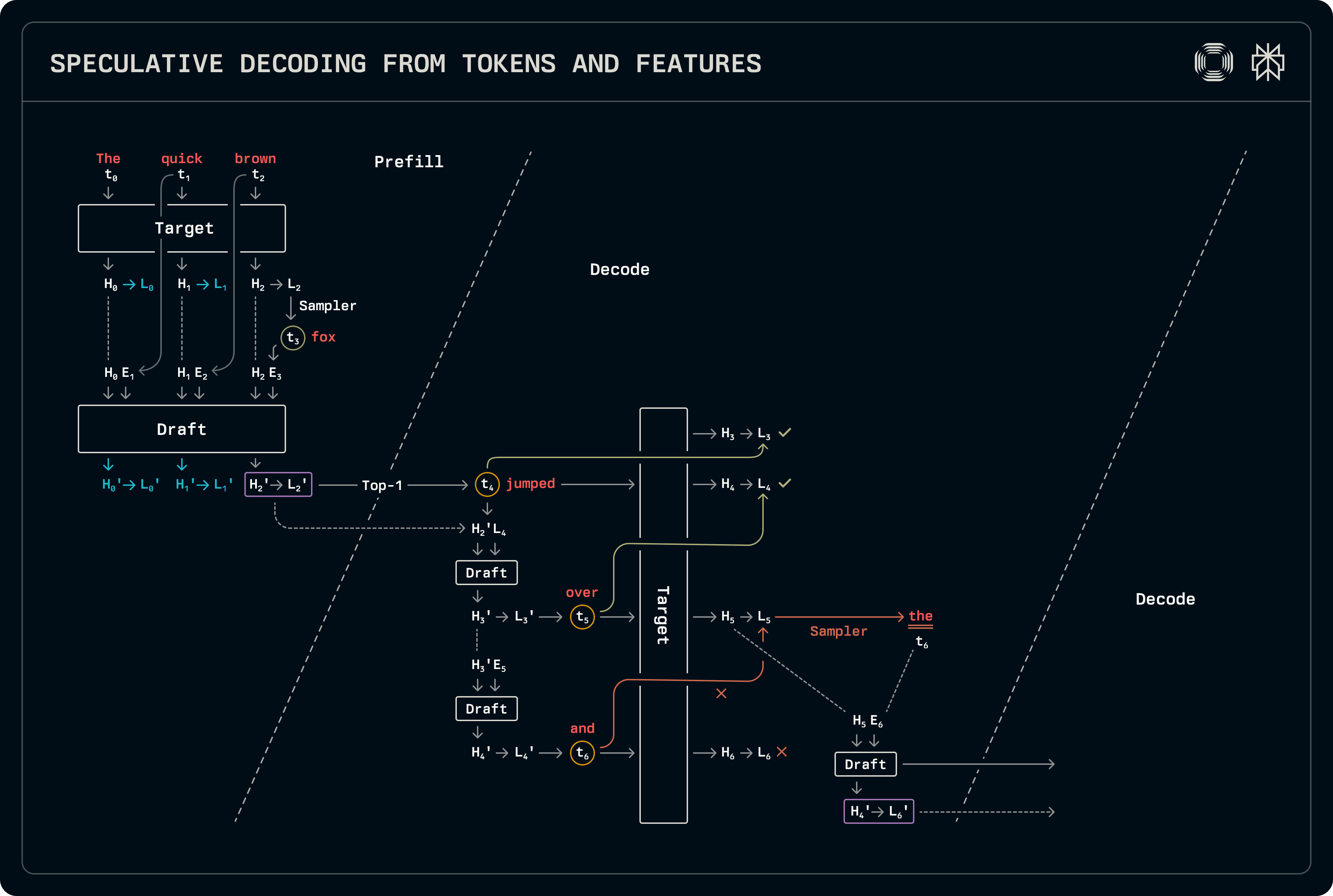
Tok dekodiranja je vrlo sličan dekodiranju nacrta-cilja, uz izuzetak da se i skrivena stanja i logits prenose. Naša implementacija dijeli sve povezane uzorke i obrada logits, specijalizirajući samo model naprijed invokacije. Kada se predviđa više tokena, model za izradu koristi skrivene stanja nacrta za predikciju, također popunjujući unose KV predmemorije na osnovu vlastitih značajki. Dugoročno, to može degradirati točnost. Nakon toga, kada se model za izradu pokrene kako bi popunio unos KV predmemorije za predikciju cilja, radimo na cijelom nizu uzimajući točnija skrivena stanja cilja kao ulaze. Budući da su ovi modeli nacrta mali, dodani trošak obrade dodatnih tokena je zanemariv.
Obuka MTP Glava
Kako bismo imali koristi od MTP, izgradili smo infrastrukturu potrebnu za treniranje MTP glava priključenih našim fino podešenim modelima na Perplexitys skupovima podataka, radi na jednom čvoru s 8xH100 uređajima. Za otprilike jedan dan možemo izgraditi glave za modele u rasponu od Llama-1B do Llama-70B i DeepSeek V2-Lite. Za veće modele se oslanjamo na MTP glave izgrađene tijekom procesa fino podešavanja.
Cilj obuke MTP-a je uskladiti skrivene stanja nacrta i logits ekstrapolirane iz skrivenih stanja ciljeva s logits i skrivenim stanjima cilja sljedećeg tokena. Budući da je inferencija za skrivene stanja skupa, pre-računavamo ih koristeći našu inferencijski optimiziranu implementaciju ciljnog modela, koja će se koristiti tijekom obuke. Međutim, kako bismo potvrdili izvedbu inferencije MTP-a i osigurali da numeričke razlike zbog kvantizacije ili optimizacija ne ometaju rezultate, za procjenu gubitka i točnosti validacije potpuno ponovno koristimo inferencijsku implementaciju kako ciljnog tako i modela za izradu.
Kada smo prelazili s ShareGPT skupa podataka korištenih u izvornoj papiru na veće uzorke, primijetili smo da se arhitektura MTP glava koja je navedena i implementirana u EAGLE papiru nije uspjela obučiti za modele veličine 70B. Za razliku od ShareGPT-a koji je imao veći broj kraćih sekvenci, obučavamo na nešto manjem broju znatno dužih upita. Budući da su se izvorne EAGLE glave malo razlikovale u strukturi od tipičnog transformatora, ponovo smo uveli neke slojeve RMS normalizacije koji su prethodno uklonjeni. Utvrđeno je da to nije samo omogućilo treniranje da konvergira, već je također povećalo točnost glava za nekoliko postotnih poena.

Ne samo da slojne norme olakšavaju obuku, već je ponovno uvođenje normi također matematički intuitivno. MTP glave ponovno koriste ugradnje i projekcije logits ciljnog modela, budući da su one prilično velike (oko 2 GB za Llama 70B). Tijekom obuke, oni su zamrznuti i očekuje se da MTP sloj nauči ugraditi predikcije u istu vektorsku prostor kao što je što je projektni sloj originalnog modela naučio tijekom obuke. Odbacivanjem normi, od jedne MLP se očekuje da nauči istu funkciju kao MLP nakon kojeg slijedi norma, što ograničava usklađivanje između skrivenih stanja modela za izradu i ciljnog modela.
Inferencija sa Spekulativnim Dekodiranjem
U inferencijskom motoru, kako bi generirali tokene za ulazne nizove, prvo ih je potrebno grupirati u razmjerno veličaste serije, zatim se moraju dodijeliti stranice u KV predmemoriju za sljedeće tokene. Ulazni tokeni i informacije o KV stranici pakiraju se u međuspremnik koji se emitira svim paralelnim rangovima koji pokreću model. Na kraju, metapodaci se kopiraju u GPU memoriju i model se izvršava za proizvodnju logits iz kojih se uzorkuje sljedeći token.
Za razliku od određenih implementacija koje labavo povezuju nacrt i ciljni inferencijski server putem omotača koji usmjerava zahtjeve između njih, naši nacrt-ciljani parovi su čvrsto povezani i zajedno prolaze kroz generaciju. Raspored serija i dodjela KV stranica su zajednički između modela za sve oblike spekulativnog dekodiranja: ovo ujedinjuje logiku koja povezuje model s nadrednim inferencijskim serverom, jer svi izlažu isto sučelje.
Inferencijski runtime u Perplexity oblikovan je oko FlashInfer, koji određuje metapodatke koji se trebaju izgraditi kako bi se konfigurirali i planirali kernel pažnje. S obzirom na neke ulazne sekvence koje formiraju seriju, za prefiltriranje, dekodiranje ili provjeru, potrebno je izvršiti rad na CPU-u za dodjelu međupremnika i popunjavanje određenih konstantnih premještanja koji se koriste u pažnji. Ovaj rad dolazi uz trošak raspoređivanja serija i dodjeljivanje KV stranica, koji također dodaju latencije koje se moraju sakriti kako bi se maksimalizirala GPU utilizacija.
Dok smo u potpunosti paralelizirali rad na strani CPU-a i GPU-a za inferenciju bez spekulacije, otkrili smo da je ravnoteža CPU-GPU za spekulativno dekodiranje složenija. Glavni izazov proizlazi iz činjenice da broj prihvaćenih tokena određuje duljinu sekvence za sljedeće izvršavanje, uvodeći teško izbjegljivo sinkrono mjesto između GPU i CPU. Eksperimentirali smo s različitim rasporedima kako bismo najbolje sakrili latenciju CPU rada.
Raspored Nacrta-Cilja
Unatoč tome što je manji od modela cilja, kada se cijeli LLM koristi kao nacrt, to i dalje unosi značajnu latenciju na GPU, pružajući određeno slobodno mjesto za skrivanje skupih CPU operacija. Budući da manji modeli ne koriste prednosti tenzorske paralelnosti, dolazi do nesklada između broja rangova između cilja i nacrta koji se dijele. U našoj implementaciji, model za izradu radi samo na vodećem rangu TP grupe.
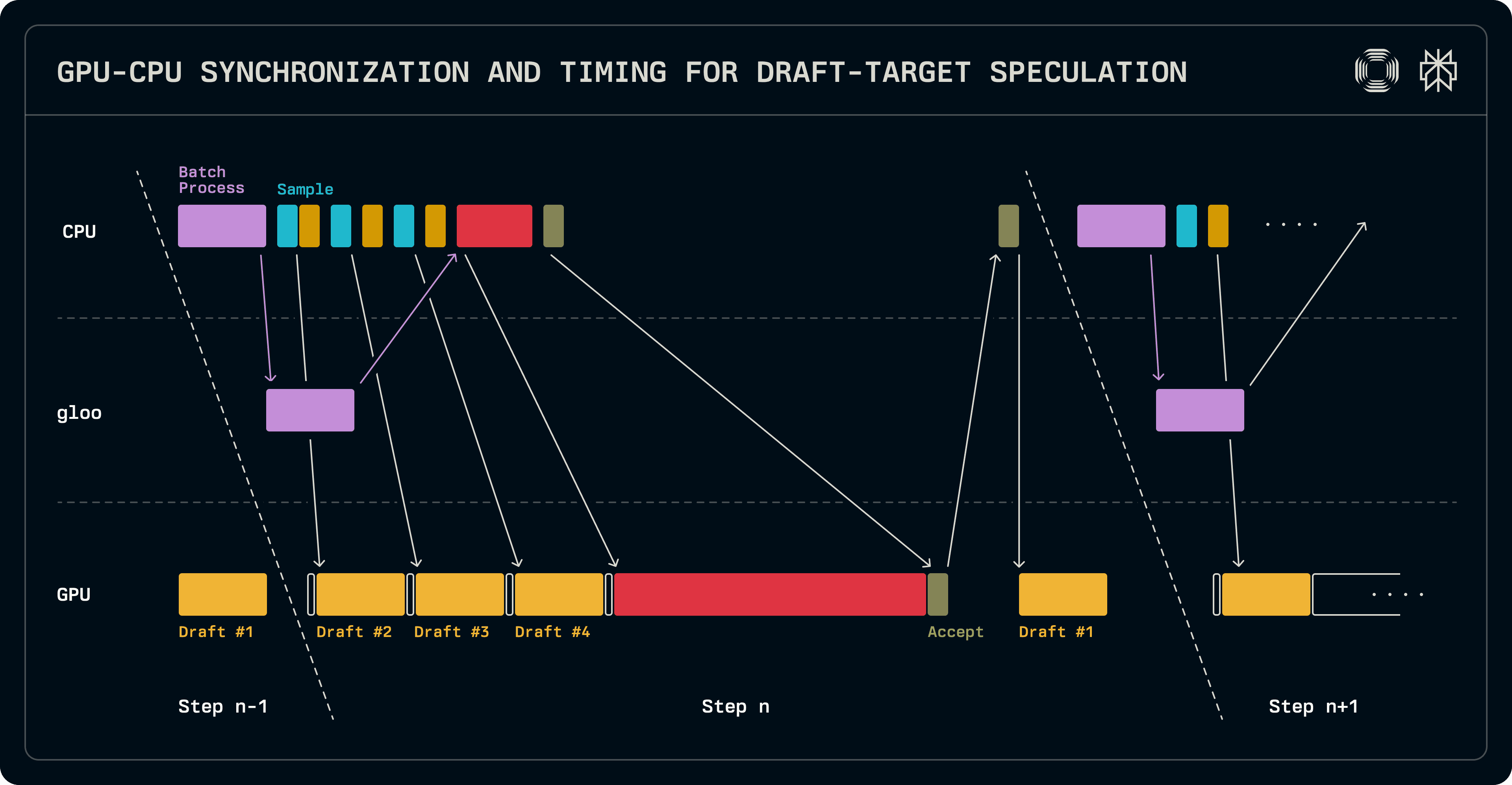
Kao što je ranije navedeno, korak dekodiranja prenosi logits u sljedeće izvršavanje. Ovo nam omogućuje da preklopimo jedno izvršavanje modela za izradu s radom raspoređivanja serija na strani CPU-a. Nakon što se serija skupi, ponovljeni pozivi uzorkivaču i modelu za izradu proizvode tokene nacrta. Paralelno se priprema serija za provjeru za ciljni model i sinkronizira s paralelnim radnicima. Ciljni logits se provjeravaju i uzorkuju kako bi se odredile prihvaćene duljine sekvence. U ovom trenutku, potrebna je sinkronizacija između GPU-a i CPU-a kako bi se odredile daljnje duljine sekvenci. Budući da se model za izradu pokreće samo na vodećem čvoru, njegova serija se postavlja sekvencijalno, a njegovo izvršavanje se pokreće kako bi napunilo unose KV predmemorije s dodatnim tokenom koji je ciljni model izdavao. Logits koje proizvodi ovo izvršavanje u trenutnom krugu će se koristiti za uzorkovanje prvog tokena nacrta u sljedećem krugu. Najvažnije, dok je nacrt u radu, sljedeća serija se može planirati.
MTP Raspored za Jedan Token
Dok runtime još ne pruža istraživanje stabla nacrta u stilu EAGLE, implementirali smo poseban slučaj ovog sustava, uzimajući u obzir linearni niz tokena nacrta proizvedenog od modela veličine jednog sloja dekodera transformatora. Ova shema može se koristiti za predikciju nacrta koristeći open-source težine DeepSeek R1. Pod slučaj predikcije jednog tokena vrlo je zanimljiv, budući da velike MTP slojeve postižu dovoljno visoke stope prihvaćanja kako bi opravdale svoje troškove.
MTP raspoređivanje je donekle složenije, budući da je model za izradu mnogo brži, skrivajući manje latencije na strani CPU-a. Dodatno, nacrt je podijeljen zajedno s ciljnim modelom, zahtijevajući zajedničke prijenosne memorije za informacije o serijama. Izvršavanje počinje prijenosom informacija o seriji i uzorkovanjem prvog tokena iz prenesenih logits, slično prethodnoj shemi. Sljedeće, cilj je pokrenut za validaciju tokena, obrađujući 2 * D tokena, gdje je D veličina dekodirajuće serije. Ovo je idealno za mikro-bacanje u modelima Mješavine-stručnjaka (MoE) preko sporijih međuspojnika poput InfiniBand-a, budući da se serija ravnomjerno dijeli na dva dijela. Skrivena stanja cilja prenose se u sljedeće izvršenje nacrta, dok se logits također šalju u uzorkivača za verifikaciju.

Izvodeći ograničeni dodatni rad na GPU-u, izbjegavamo sinkronizaciju između CPU-a i GPU-a nakon prihvaćanja sekvence nacrta. Nakon što se ulazni tokeni ciljeva pomaknu, kernel ubacuje sljedeće ciljne tokene u odgovarajuće lokacije. Nacrt se zatim ponovno pokreće s istim informacijama o seriji kao cilj, popunjavajući unose KV predmemorije i gradeći logits i skrivena stanja za sljedeće izvršavanje, obavljajući malo redundantnog posla na tokenima koji nisu prihvaćeni. U tim situacijama, latencija neiskorištenog rada je jedva mjerljiva zbog male veličine modela nacrta. Paralelno s izvršavanjem modela za izradu, duljine sekvenci odrede se na CPU-u, a proces raspoređivanja sljedeće serije dodatno se pokreće bez potrebe za čekanjem da GPU rad završi.
Troškovi dodatnog rada u sloju nacrta nisu primjetni u pažnji, međutim MLP slojevi su problematičniji. Budući da instrukcije za množenje matrica dodaju granicu od 64 duž dimenzije broja tokena, ako udvostručenje ne zahtijeva značajno više blokova, troškovi su prikriveni. Za duže sekvence nacrta troškovi su skuplji i shema koja se koristi za redovne modele nacrta-cilja funkcionira bolje.
Reference
Brza Inferencija iz Transformatora putem Spekulativnog Dekodiranja
EAGLE: Spekulativno Uzorkovanje zahtijeva ponovnu procjenu Neizvjesnosti Značajki
EAGLE-2: Brža Inferencija Jezičnih Modela s Dinamičkim Stablom Nacrta
EAGLE-3: Skaliranje Ubrzanja Inferencije Velikih Jezičnih Modela putem Obuke u Vrijeme Testiranja
Medusa: Jednostavan Okvir za Ubrzanje Inferencije LLM-a s Više Glava za Dekodiranje
FlashInfer: Učinkovit i Prilagodljiv Motor Pažnje za Posluživanje Inferencije LLM-a