

Napisao
Tim Perplexity
Objavljeno na
Search API: Bolja ekstrakcija, dinamički benchmarkovi
U rujnu smo objavili tehnički pregled arhitekture Perplexity Search API-ja i predstavili search_evals, naš otvoreni evaluacijski okvir za benchmarkiranje API-ja za pretraživanje u agentskim radnim tokovima. Od tada je najznačajnije ulaganje bilo usmjereno na kvalitetu isječaka, optimiziranu duž dviju dimenzija: relevantnosti i veličine. Vraćanje odgovarajućeg sadržaja u odgovarajućoj količini izravno određuje točnost naknadnih odgovora i učinkovitost tokena. Rad potreban da se to postigne uključivao je izgradnju novih sustava za ekstrakciju, označavanje na razini raspona i evaluaciju, ponajprije cjevovoda za označavanje raspona koji utvrđuje koji segmenti izvornog dokumenta odgovaraju zadanom upitu.
Evaluacija isječaka na razini raspona
Kako bismo sustavno unaprijedili isječke, razvili smo novi sustav evaluacije. Za zadani upit i dokument sustav identificira i označava raspone unutar dokumenta prema njihovu odnosu s upitom: "ključne" raspone koji moraju biti uključeni u isječak, različite klase "nerelevantnih" raspona koje treba isključiti, duplikate i druge kategorije. Takvo označavanje na razini raspona omogućuje nam evaluaciju kvalitete isječaka s razinom preciznosti koja prethodno nije bila moguća, pri čemu mjerimo i ono što je ispravno uključeno i ono što je ispravno izostavljeno.
U praksi nam ta poboljšanja omogućuju generiranje manjih isječaka koji su relevantniji za upit. Naš cjevovod za razumijevanje sadržaja, koji se sam unapređuje, sada obrađuje širi raspon strukturiranih formata podataka, uključujući tablice, ugniježđene popise i dinamički prikazan sadržaj koji raniji skupovi pravila nisu mogli pouzdano parsirati.
Ta su poboljšanja proizašla iz naših vlastitih produkcijskih sustava. Kako su naša interna istraživanja unapređivala relevantnost i veličinu isječaka, interne evaluacije pokazale su da su manji proračuni sadržaja zapravo davali točnije rezultate nakon niza poboljšanja kvalitete. Unijeli smo određene izmjene u zadane konfiguracije kako bismo odražavali svoje nalaze, smanjujući veličinu odziva i latenciju te istodobno isporučujući korisniji sadržaj po rezultatu. Za programere, manji i relevantniji isječci izravno znače niže troškove tokena i bolje upravljanje kontekstom za nizvodne LLM-ove.
SEAL: benchmarkiranje vremenski osjetljivog dohvaćanja
SEAL benchmark ispituje može li sustav za dohvaćanje odgovoriti na pitanja čiji se točan odgovor mijenja tijekom vremena. Pouzdano odgovaranje zahtijeva svježinu indeksa u stvarnom vremenu, pametniju ekstrakciju isječaka iz različitih kontinuirano ažuriranih izvora podataka te parsiranje koje može prepoznati trenutačnu vrijednost umjesto povijesne.
Kada smo pokrenuli search_evals na izdanju SEAL-a od 22. veljače uz upotrebu modela Claude Sonnet 4.5, rezultati za Perplexity porasli su, dok su rezultati drugih pružatelja pali na SEAL-Hard:
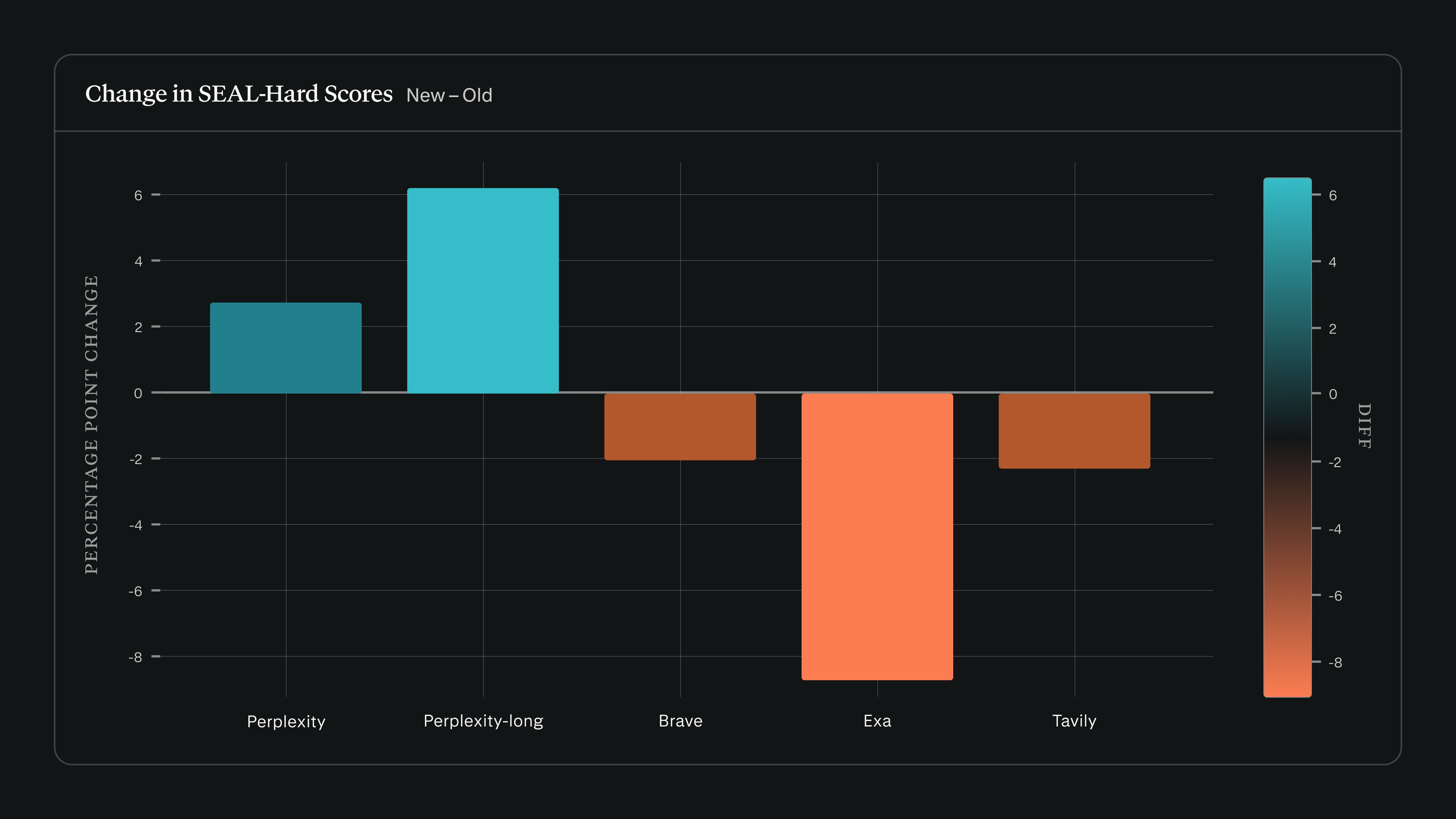
Proširili smo svoj okvir search_evals kako bi uključivao SEAL uz benchmarkove navedene u našoj objavi iz rujna. Ažurirani rezultati i metodologija dostupni su u ažuriranom repozitoriju na GitHubu.
Podrška za više upita
API sada podržava do 5 upita u jednom zahtjevu. Rezultati se vraćaju grupirani po upitu, istim redoslijedom kojim su poslani. Time se smanjuje broj povratnih komunikacija za aplikacije koje trebaju paralelno pokretati povezana pretraživanja, kao što su agenti koji raščlanjuju složeno pitanje na više podzadataka dohvaćanja.
Prošireno filtriranje
Uz filtriranje domena (allowlist i denylist, do 20 domena) i filtriranje prema aktualnosti, API sada podržava filtriranje jezika prema kodu ISO 639-1 i regionalno pretraživanje prema ISO kodu države. Te se mogućnosti mogu kombinirati radi preciznog ograničavanja rezultata, primjerice na rezultate na engleskom jeziku iz njemačkih domena.
SDK i dostupnost
Python SDK (pip install perplexityai) sada pruža nativnu podršku za Search API uz Agent API i Sonar API.
Cjelovita dokumentacija dostupna je na docs.perplexity.ai
Search API: Bolja ekstrakcija, dinamički benchmarkovi
U rujnu smo objavili tehnički pregled arhitekture Perplexity Search API-ja i predstavili search_evals, naš otvoreni evaluacijski okvir za benchmarkiranje API-ja za pretraživanje u agentskim radnim tokovima. Od tada je najznačajnije ulaganje bilo usmjereno na kvalitetu isječaka, optimiziranu duž dviju dimenzija: relevantnosti i veličine. Vraćanje odgovarajućeg sadržaja u odgovarajućoj količini izravno određuje točnost naknadnih odgovora i učinkovitost tokena. Rad potreban da se to postigne uključivao je izgradnju novih sustava za ekstrakciju, označavanje na razini raspona i evaluaciju, ponajprije cjevovoda za označavanje raspona koji utvrđuje koji segmenti izvornog dokumenta odgovaraju zadanom upitu.
Evaluacija isječaka na razini raspona
Kako bismo sustavno unaprijedili isječke, razvili smo novi sustav evaluacije. Za zadani upit i dokument sustav identificira i označava raspone unutar dokumenta prema njihovu odnosu s upitom: "ključne" raspone koji moraju biti uključeni u isječak, različite klase "nerelevantnih" raspona koje treba isključiti, duplikate i druge kategorije. Takvo označavanje na razini raspona omogućuje nam evaluaciju kvalitete isječaka s razinom preciznosti koja prethodno nije bila moguća, pri čemu mjerimo i ono što je ispravno uključeno i ono što je ispravno izostavljeno.
U praksi nam ta poboljšanja omogućuju generiranje manjih isječaka koji su relevantniji za upit. Naš cjevovod za razumijevanje sadržaja, koji se sam unapređuje, sada obrađuje širi raspon strukturiranih formata podataka, uključujući tablice, ugniježđene popise i dinamički prikazan sadržaj koji raniji skupovi pravila nisu mogli pouzdano parsirati.
Ta su poboljšanja proizašla iz naših vlastitih produkcijskih sustava. Kako su naša interna istraživanja unapređivala relevantnost i veličinu isječaka, interne evaluacije pokazale su da su manji proračuni sadržaja zapravo davali točnije rezultate nakon niza poboljšanja kvalitete. Unijeli smo određene izmjene u zadane konfiguracije kako bismo odražavali svoje nalaze, smanjujući veličinu odziva i latenciju te istodobno isporučujući korisniji sadržaj po rezultatu. Za programere, manji i relevantniji isječci izravno znače niže troškove tokena i bolje upravljanje kontekstom za nizvodne LLM-ove.
SEAL: benchmarkiranje vremenski osjetljivog dohvaćanja
SEAL benchmark ispituje može li sustav za dohvaćanje odgovoriti na pitanja čiji se točan odgovor mijenja tijekom vremena. Pouzdano odgovaranje zahtijeva svježinu indeksa u stvarnom vremenu, pametniju ekstrakciju isječaka iz različitih kontinuirano ažuriranih izvora podataka te parsiranje koje može prepoznati trenutačnu vrijednost umjesto povijesne.
Kada smo pokrenuli search_evals na izdanju SEAL-a od 22. veljače uz upotrebu modela Claude Sonnet 4.5, rezultati za Perplexity porasli su, dok su rezultati drugih pružatelja pali na SEAL-Hard:
Proširili smo svoj okvir search_evals kako bi uključivao SEAL uz benchmarkove navedene u našoj objavi iz rujna. Ažurirani rezultati i metodologija dostupni su u ažuriranom repozitoriju na GitHubu.
Podrška za više upita
API sada podržava do 5 upita u jednom zahtjevu. Rezultati se vraćaju grupirani po upitu, istim redoslijedom kojim su poslani. Time se smanjuje broj povratnih komunikacija za aplikacije koje trebaju paralelno pokretati povezana pretraživanja, kao što su agenti koji raščlanjuju složeno pitanje na više podzadataka dohvaćanja.
Prošireno filtriranje
Uz filtriranje domena (allowlist i denylist, do 20 domena) i filtriranje prema aktualnosti, API sada podržava filtriranje jezika prema kodu ISO 639-1 i regionalno pretraživanje prema ISO kodu države. Te se mogućnosti mogu kombinirati radi preciznog ograničavanja rezultata, primjerice na rezultate na engleskom jeziku iz njemačkih domena.
SDK i dostupnost
Python SDK (pip install perplexityai) sada pruža nativnu podršku za Search API uz Agent API i Sonar API.
Cjelovita dokumentacija dostupna je na docs.perplexity.ai
Podijelite ovaj članak