

Írta
Mesterséges Intelligencia Csapat
Közzétéve
A Sonar Felgyorsítása Spekulációval
A spekulatív dekódolás felgyorsítja a Nagy Nyelvi Modellek (LLM-ek) generálási sebességét egy gyors és kis vázlati modell segítségével, amely a nagyobb célmodell által ellenőrzött befejezési jelölteket hoz létre. Ezen eljárás keretein belül, ahelyett, hogy a drága célmodell egyetlen tokent állítana elő, többet bocsátanak ki egy lépésben. Itt bemutatjuk a spekulatív dekódolás különböző típusainak megvalósítási részleteit, amelyeket a Perplexity alkalmazott a Sonar modellek közötti késleltetés csökkentésére.
Spekulatív Dekódolás
A spekulatív dekódolás a természetes nyelvek szerkezetét és a transzformátorok auto-regresszív jellegét használja a tokenek generálásának felgyorsítására. Bár a nagyobb modellek, mint a Llama-70B, több tudást hordoznak, mint a kisebbek, mint a Llama-1B, néhány egyszerűbb feladat esetében hasonlóan teljesítenek. Ez a fedés arra utal, hogy bizonyos szekvenciákat jobban generálnak a kevésbé költséges modellek, míg a komplex problémákat a nagyobbaknak kell hagyni. A kihívás abban rejlik, hogy meghatározzuk, mely befejezések jobbak, és hogy a kisebb modell által generált végeredmény ugyanolyan minőségű-e, mint a nagyobbét.
Szerencsére az LLM-ek auto-regresszív transzformátorok: ha egy token szekvenciát kapnak, akkor a következő token valószínűségi eloszlását adják meg. Ezenkívül az input szekvenciában található tokenekhez kapcsolódó közbenső jellemzőkből származó logitok is jelzik, hogy a modell mennyire valószínű, hogy azokat a tokeneket bocsátja ki. Ez a tulajdonság lehetővé teszi a spekulációt: ha egy kisebb modell generál egy token szekvenciát egy bemeneti prefixből, azt a nagyobb modellen át lehet futtatni, hogy kiderüljön, mennyire illeszkedik a célmodellhez. A jelöltek minden egyes prefixét valószínűséggel értékelik, és a leghosszabbat, amely meghaladja az elfogadási küszöböt, választják ki. Bónuszként a célmodell ingyenesen biztosít egy következő tokent: ha egy vázlati modell n tokent generál, legfeljebb n + 1 bocsátható ki egy lépésben.
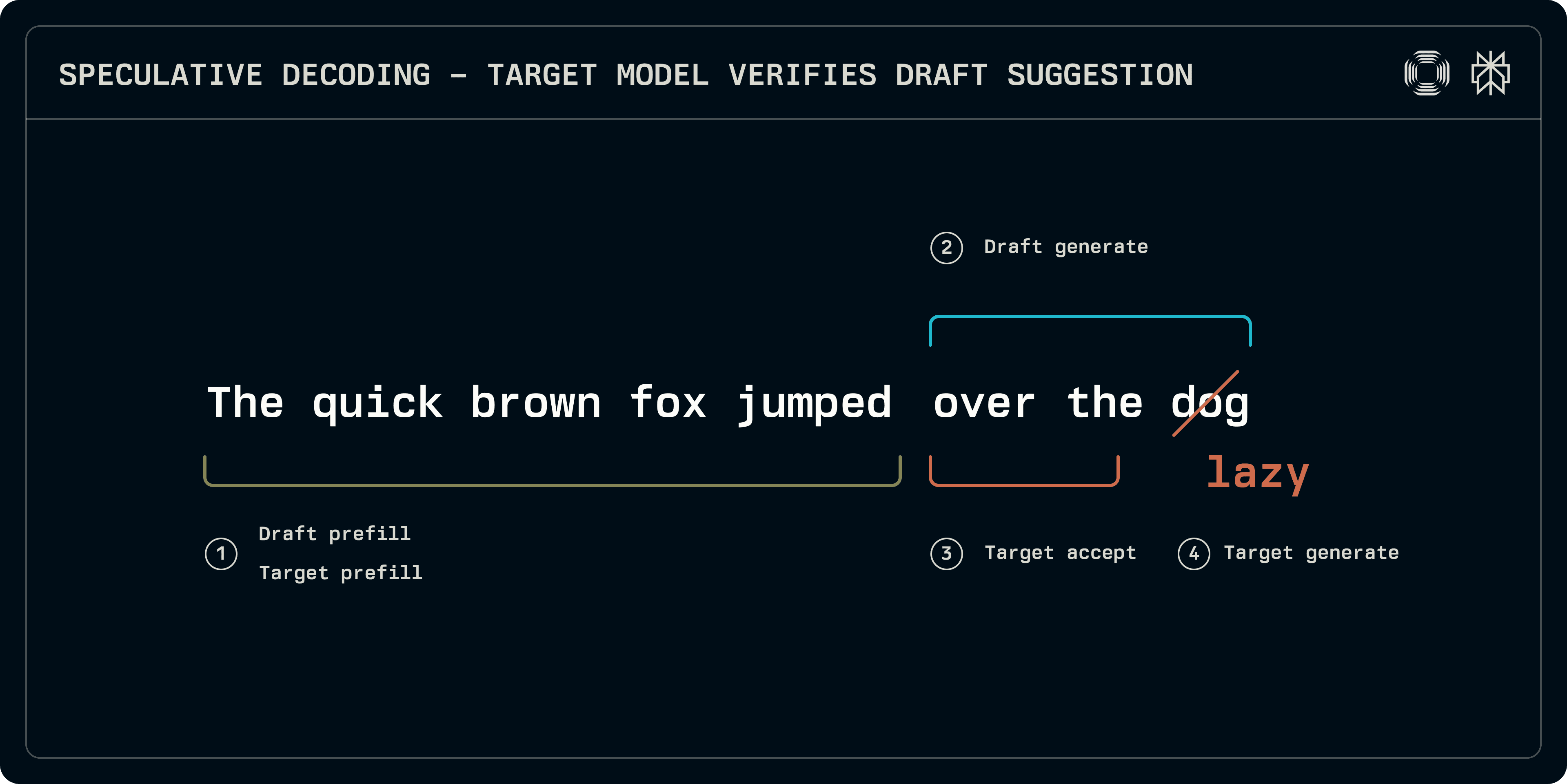
Az inferencia során a spekulatív mintavételi folyamat körülbelül 4 szakaszra osztható:
Előfeltétel: a cél- és a vázlati modelleket mindkettőt futtatni kell a bemeneti szekvencián, hogy feltöltsék a KV cache bejegyzéseit. Míg egyes rendszerek, mint a Medusa, egyszerűbb sűrű rétegeket használnak a predikcióhoz, ebben a bejegyzésben azokra a transzformátor-alapú tervezetekre összpontosítunk, amelyeknek saját KV cache-ük van.
Vázlat generálás: a vázlati modell iterálva állít elő bizonyos számú fix tokent. A vázlat szekvencia lehet lineáris, vagy a modell felfedezheti a fa-szerű struktúrát egy adott mélységig (EAGLE, Medusa). Itt a lineáris szekvenciákra összpontosítunk.
Elfogadás: a célmodell fut a vázlat szekvencián, és logitokat épít minden vázlati tokenhez. Meghatározzák a leghosszabb elfogadható szekvencia hosszát.
Cél generálás: mivel a cél generálja a logitokat, a nem egyező pozícióban vagy a szekvencia végén a logitok egy következő tokenhez tartoznak. Ezek a logitok mintavételezhetők, hogy robusztus tokent biztosítsanak a célból, ezzel lezárva a szekvenciát.
Számos módszer létezik a spekulatív dekódolás megvalósítására. Ebben a bejegyzésben arra a rendszerekre összpontosítunk, amelyeket a Sonar modellek felgyorsítására használtunk egy házon belüli 1B modell segítségével, valamint az előrejelzési mechanizmusokra, amelyeket a DeepSeek méretű modellek felgyorsítására építünk ki.
Cél-Vázlat
A spekulatív dekódolás elérhető, ha egy meglévő kis LLM-t kapcsolunk össze vázlatmodelként egy célmodellel, hogy jelölt szekvenciákat generáljunk. A gyártás során felgyorsítottuk a Sonart egy Llama-1B modellel, amelyet a céllal azonos adatállományon finomhangoltunk. Habár ez a megközelítés nem igényelt új vázlati modell képzést, a kis modell továbbra is jelentős KV cache kapacitást használ, és egy enyhe előfeltételi többletet hoz létre, ami növeli a TTFT-t.
Elnyomott rendszerben a dekóder csak a dekód-e csak kötegekről spekulál, a standard mintavétel során mikor előfeltétel van, vagy kevert előfeltétel-dekód kötegeken. Az előfeltételi szakaszban a cél logitokat azonnal mintavételezik, hogy az újonnan generált tokent is előfeltételezzék a vázlat KV cache-jében. A vázlatot még nem mintavételezik, de a közvetített logitokat továbbítják a dekód szakaszba.
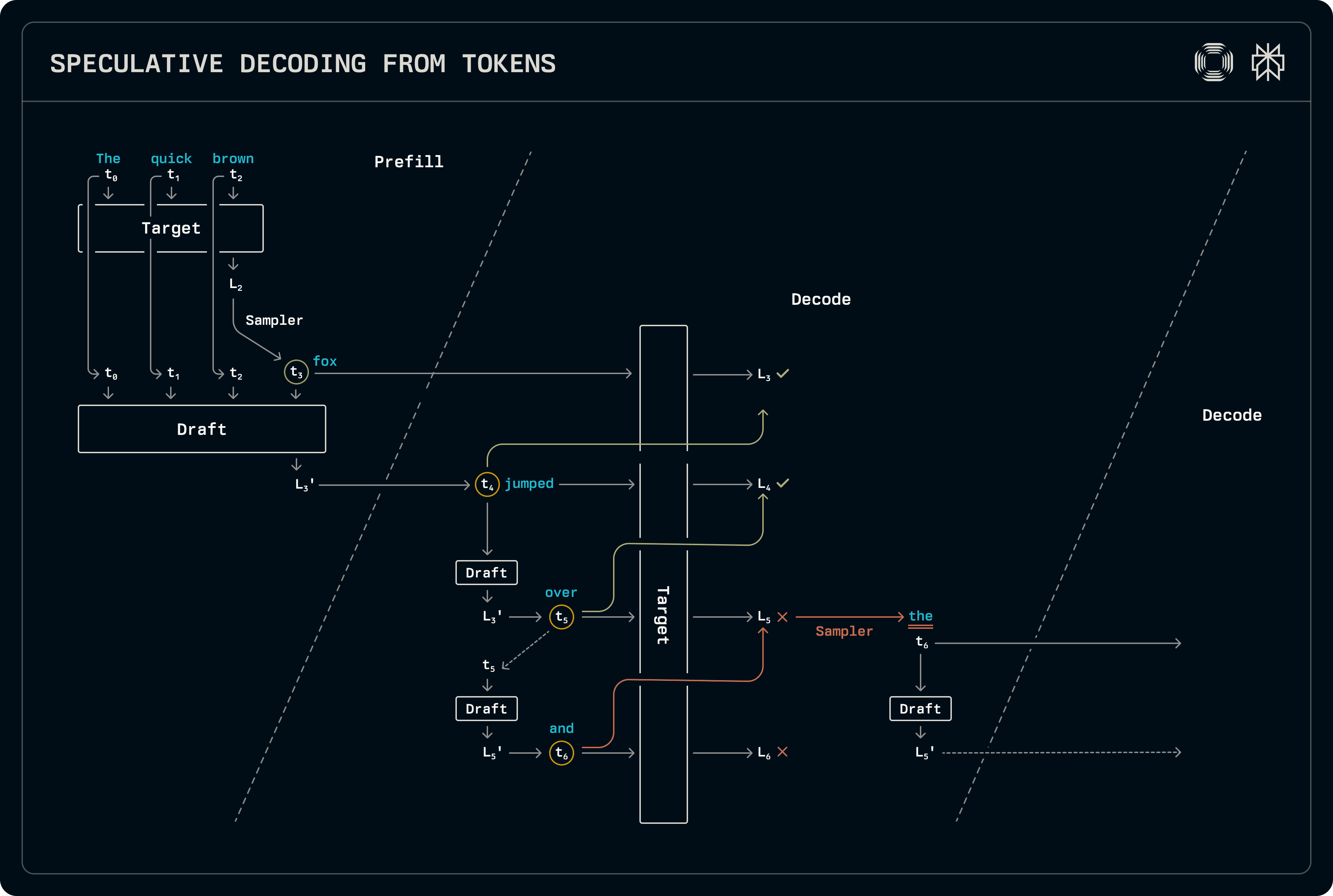
A dekód során a vázlati modellt előre mozgatják, mintavételezve a legjobb tokent minden szakaszban. Miután elértük a kívánt vázlati hosszúságot, a tokent a célmodell függvényében futtatják, hogy a logitokat előállítsák, amelyek alapján a mintavételező az elfogadott szekvencia hosszát azonosítja. Az elfogadást a vázlat és cél logitok teljes valószínűségi eloszlásának összehasonlításával határozzák meg. Mivel a cél mindig egy logitok halmazt bocsát ki az elfogadott vázlati szekvencia után, azt mintavételezik, hogy további kimenetet biztosítsanak. Mivel a vázlat modell még nem látta azt az elfogadott tokent, ismét futtatják, hogy feltöltsék a megfelelő KV cache bejegyzéseit az előkészítéshez a következő dekód lépéshez, újra átvivéve a logitokat.
EAGLE
Az EAGLE egy spekulatív dekódolási rendszer, amely több vázlat-szekvenciát felfedez, amelyeket a valószínű vázlati tokenek fa-szerű bejárásával generálnak. Egy rögzített (EAGLE) vagy dinamikusan alakított (EAGLE-2) fát felfedeznek a vázlati tokenek egymás utáni végrehajtásával, figyelembe véve a Top-K jelölteket minden egyes csomóponton, ahelyett, hogy a legmagasabb pontszámú tokent követnék egy lineáris szekvenciában. A szekvenciákat ezután értékelik, és a leghosszabb megfelelő szereplőt választják a folytatásra, amely szintén egy további tokent csatol a céltól.

A pontosabb predikció elérése érdekében az EAGLE vázlati modell nemcsak a tokenek alapján, hanem a célmodel megfelelő jellemzőit (utolsó réteg rejtett állapotai) is figyelembe veszi. Az EAGLE hátránya a szükséglet, hogy testreszabott, kis vázlati modelleket kell képezni, amelyek elég pontosak ahhoz, hogy megfelelő jelölteket generáljanak alacsony késleltetési kereteken belül. Általában a vázlati modell egyetlen transzformátor rétegből áll, amely megegyezik az eredeti modell dekóder rétegével, amely szorosan kapcsolódik a célhoz az embeddings és lm_head kivetítések összekapcsolásával. Mivel ez kevesebb KV cache kapacitást igényel, az EAGLE alacsonyabb memória lábnyommal bír.
A célmodellben a fa-szerű szekvenciák ellenőrzéséhez egyedi figyelőmaszkokat kell használni. Sajnos a teljes szekvenciára vonatkozó egyedi figyelőmaszk használata jelentősen lelassítja a figyelem működését a reális bemeneti hosszoknál (akár 50%-kal), semlegesítve a spekuláció révén elérhető sebességnövekedést. Ezen okok miatt még nem implementáltuk a teljes fa-felfedezést a gyártásban, hanem a DeepSeek-V3 Műszaki Jelentésében bemutatott MTP-szerű rendszerek különleges eseteire összpontosítunk.
MTP
Ez a rendszer hasonló a vázlat-cél dekódolásához, azzal a különbséggel, hogy a rejtett állapotokat együtt használják a tokenekkel a predikcióhoz. A vázlatmodell egyidejűleg vázlat rejtett állapotokat és a saját jellemzői alapján populálja a KV cache bejegyzéseket. Hosszú távon ez gyengítheti a pontosságot. Tehát amikor a vázlatmodellt futtatjuk a cél predikció KV cache bejegyzésének feltöltésére, akkor az egész szekvencián futtatjuk, figyelembe véve a pontosabb cél rejtett állapotokat bemenetként. Mivel ezek a vázlati modellek kicsik, az egyes további tokenek feldolgozásának költsége elhanyagolható.
MTP Fejek Képzése
Ahhoz, hogy előnyhöz jussunk az MTP által, felépítettük az MTP fejek képzéséhez szükséges infrastruktúrát, amelyek a finomhangolt modelljeinkhez kapcsolódnak a Perplexity adathalmain, egy csomóponton futva 8xH100-es eszközökkel. Körülbelül egy nap alatt képesek vagyunk fejeket építeni a Llama-1B-től a Llama-70B-ig és a DeepSeek V2-Lite-ig terjedő modellekhez. Nagyobb modellek esetén a finomhangolási folyamat során készült MTP fejekre támaszkodunk.
Az MTP képzés célja, hogy összehangolja a vázlat rejtett állapotokat és a cél rejtett állapotokból extrapolált logitokat a következő tokent logitokkal és a cél következő rejtett állapotaival. Mivel a rejtett állapotok inferenciája költséges, előzetesen kiszámítjuk őket a cél modellünk inferencia-optimalizált megvalósításával, hogy használják edzés közben. Azonban hogy érvényesítsük az inferencia MTP megvalósítást és hogy megbizonyosodjunk arról, hogy a kvantáció vagy optimalizálások miatt fellépő numerikus eltérések nem gátolják az eredményeket, a validációs veszteség és a pontosság becslése érdekében teljes mértékben újra felhasználjuk mind a cél, mind a vázlatmodellek inferencia-megvalósítását.
A ShareGPT adatállománytól a nagyobb mintákra való skálázás során észrevettük, hogy az EAGLE cikkben vázolt és megvalósított MTP fejarchitektúra nem tudta betanítani a 70B méretű modelleket. A ShareGPT-hez képest, amely egy nagyobb számú rövidebb szekvenciát tartalmazott, mi egy kicsit kevesebb számú, de lényegesen hosszabb promptokra képeztünk. Mivel az eredeti EAGLE fejek kissé eltértek egy tipikus transzformátortól, újra bevezetett néhány RMS Normalizáló réteget, amelyeket eltávolítottak. Megállapítottuk, hogy ez nemcsak lehetővé tette a betanulást, hanem néhány százalékponttal növelte a fejek pontosságát is.

Nemcsak a rétegek normái segítik a képzést, a normák újra bevezetése matematikailag is intuitív. Az MTP fejek újra felhasználják a célmodell embeddings-ját és a logit kivetítéseit, mivel ezek jelentősek lehetnek méretben (körülbelül 2 GB a Llama 70B-hez). A képzés során ezek rögzítve vannak, és az elvárás az, hogy az MTP réteg tanulja meg beágyazni a predikciókat ugyanabba a vektortérbe, mint amit az eredeti modell kivetítőrétege tanult a képzés során. A normák elhagyásával egyetlen MLP-től azt várják el, hogy ugyanazt a funkciót tanulja meg, mint egy MLP, amelyet követ egy norma, ami hátráltatja a vázlat és célmodellek rejtett állapotainak összehangolását.
Inferencia Spekulatív Dekódolással
Az inferencia motorban a bemeneti szekvenciákhoz tokenek generálásához először ésszerű méretű kötegekbe kell csoportosítani őket, majd helyet kell biztosítani a következő tokenek kv cache-jában. A bemeneti tokenek és a KV oldalinformációt ezután egy pufferbe tömörítik, amelyet minden párhuzamos rangra továbbítanak, amelyek a modellt futtatják. Végül a metaadatokat átmásolják a GPU memóriába, és a modellt végrehajtják, hogy a logitokat előállítsák, amelyekből a következő tokent mintázzák.
Ellentétben bizonyos megvalósításokkal, amelyek lazán összekapcsolják a vázlatot és a célt egy wrapper-en keresztül, amely a kéréseket közvetíti közöttük, a mi vázlat-cél párjaink szorosan kapcsolódnak, és együtt lépnek át a generáción. A batch ütemezés és KV oldalallokáció megosztott a modellek között az összes spekulatív dekódolás formához: ez egyesíti azt a logikát, amely átjárja a modellt a nagy, központi inferencia motorral, mivel mindannyian ugyanazt az interfészt használják.
A Perplexity inferencia futási ideje a FlashInfer köré épül, amely meghatározza a metaadatokat, amelyeket össze kell állítani a figyelemkernel konfigurálása és ütemezése érdekében. Bizonyos bemeneti szekvenciák alapján, amelyek egy köteget alkotnak, az előlabelzéshez, dekódoláshoz vagy ellenőrzéshez, CPU-oldali munkát kell végezni a köztes pufferek allokálására és bizonyos állandó pufferek feltöltésére, amelyeket a figyelem használ. Ez a munka a batch ütemezés költségein túl is figyelembe veszi a KV oldallocatás költségeit, amelyek szintén késleltetéseket okoznak, amelyeket el kell rejteni a GPU kihasználtsága maximalizálása érdekében.
Bár teljesen párhuzamosítottuk a CPU-oldali és GPU-oldali munkát spekuláció nélkül, úgy találtuk, hogy a CPU-GPU egyensúly a spekulatív dekódolás esetén bonyolultabb. A fő kihívás abból adódik, hogy az elfogadott tokenek száma meghatározza a szekvencia hosszát a következő futáshoz, ami egy nehezen elkerülhető GPU-CPU szinkronizálási pontot vezet be. Különböző ütemezési sémákkal kísérleteztünk, hogy a lehető legjobban elfedjük a CPU munkájának késleltetését.
Vázlat-Cél Ütemezés
Annak ellenére, hogy kisebb egy célmodellnél, amikor egy egész LLM-et használnak vázlatként, még mindig jelentős késleltetést vezet be a GPU-n, biztosítva némi helyet a drága CPU műveletek elrejtésére. Mivel a kisebb modellek nem nyernek a tenzor párhuzamosságából, eltérés van a cél és a vázlat között a számos rangban, amit a cél és a vázlat osztva osztották el. A megvalósításunkban a vázlatmodell csak a TP csoport vezető rangján fut.
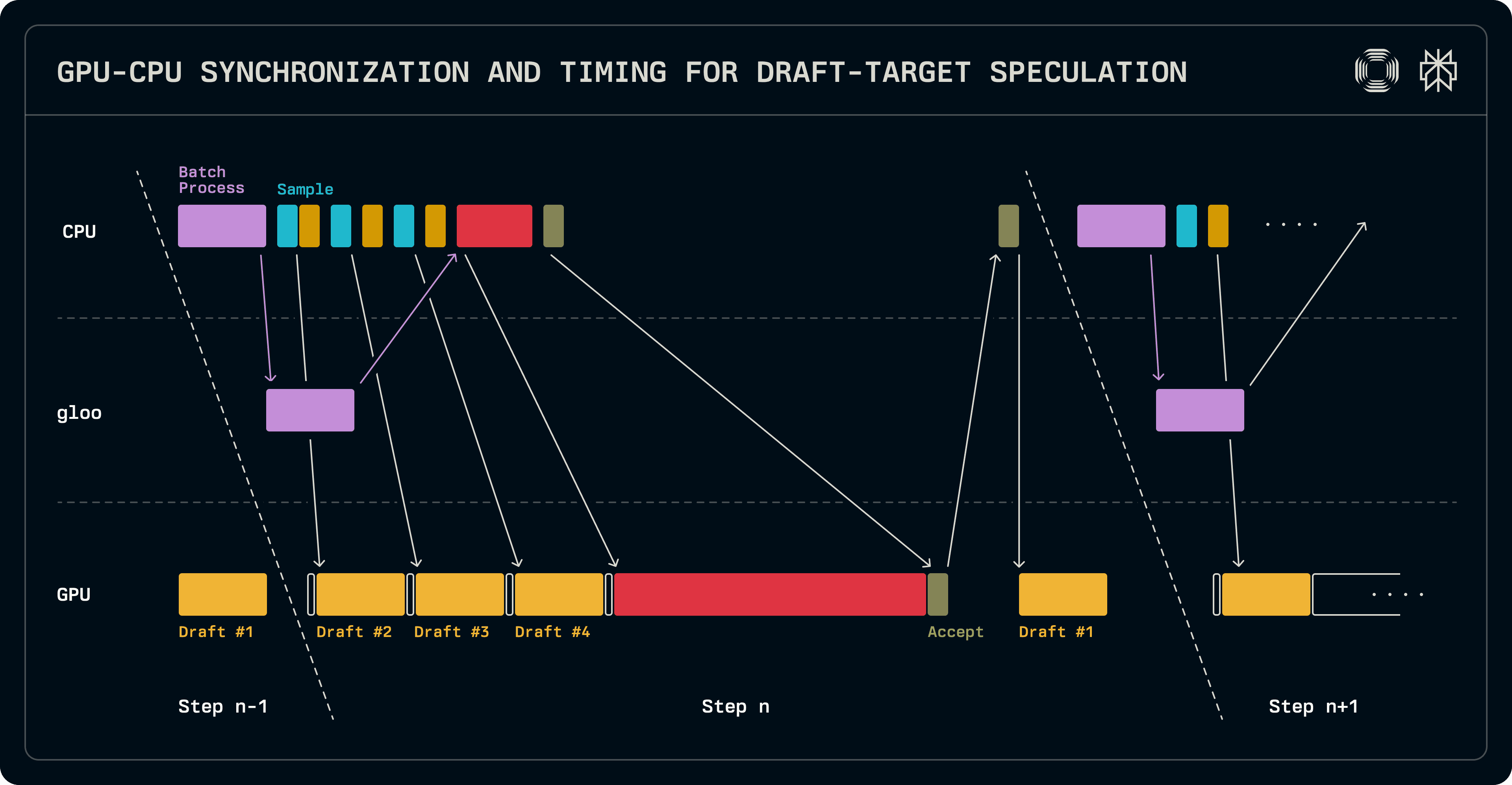
Ahogy az előbb említettük, a dekód lépés logitokat emel át a következő futásra. Ez lehetővé teszi, hogy egy vázlatmodell végrehajtását átfedjük a CPU-oldali batch ütemezés munkájával. Miután a batch összeállt, ismételt hívások a mintavételezőhez és a vázlathoz a vázlati tokeneket produkálják. Párhuzamosan a célmodellhez kerül a batch az ellenőrzéshez, és szinkronba kerül a párhuzamos munkatársakkal. A cél logitokat ellenőrzik és mintázzák, hogy meghatározzák az elfogadott szekvencia hosszát. Ekkor kötelező a GPU-CPU szinkronizálás, hogy meghatározhassuk a következő szekvencia hosszokat. Mivel a vázlatmodell csak a vezető csomóponton fut, batch-jét sorozzosan állítják be, és végrehajtására indítják, hogy feltöltsék a KV cache bejegyzéseit azzal az extra tokennel, amelyet a cél hozott létre. Az aktuális futás során ez a vázlat futás a következő futásban a vázlat token első mintavételére fog szolgálni. A legfontosabb azonban, hogy a vázlat futtatása közben a következő batch ütemezhető.
MTP Ütemezés Egyetlen Tokenre
Habár a futási idő még nem biztosít Eagle-stílusú vázlatfa-felfedezést, megvalósítottuk ennek a sémának egy különleges esetét, figyelembe véve a lineáris szekvenciát a vázlati tokenek által, amelyeket egyetlen transzformátor dekódoló réteg méretével rendelkező modell termel. Ez a sém használható vázlati predikcióra a DeepSeek R1 nyílt forráskódú súlyainak felhasználásával. A vázlatcélzási sémának, ami az egyes tokenek előrejelzése, érdekes, mivel a nagy MTP rétegek elég magas elfogadási arányokat érnek el, hogy igazolják azok költségeit.
MTP ütemezéssel a mintavétel bonyolultabb, mivel a vázlati modell gyorsabb, kevesebb CPU-oldali késleltetést elrejtve. Ezenkívül a vázlat a célmodellel együtt társalg az adatok összekötéséhez, megosztva a batch információt. A futás a batch információk átvitelével kezdődik, és az első tokent mintálják az átmeneti logitokból, hasonlóan az előző rendszerhez. Ezt követően a célt futtatják a tokenek validálására, 2 * D token feldolgozásával, ahol D a dekód batch mérete. Ez ideális a mikrobatchinghez Mixture-of-Experts (MoE) modellek esetén a lassabb hálózati összeköttetések, például az InfiniBand fölött, mivel a batch egyenlően két részre oszlik. A cél rejtett állapotai a következő vázlat futására átkerülnek, míg a logitok a mintavételezőbe kerülnek az ellenőrzéshez.

Ha a GPU-n egy kis mennyiségű kiegészítő munkát végeznek, elkerülhetjük a CPU-GPU szinkronizálást a vázlat szekvencia elfogadása után. Miután a cél bemeneti tokenjeit eltolják, egy kernel csatlakoztatja a következő cél tokeneket a megfelelő helyükhöz. Ezután a vázlat újra-fut túl, a cél batch információval ugyanazt a feltöltéseket populálva, és logitokat és rejtett állapotokat épít a következő futásra, egyes el nem fogadott tokenek esetén némi felesleges munkát végezve. Ilyen helyzetekben a felhasználatlan munka késleltetése alig mérhető a vázlati modell kis mérete miatt. A vázlat futása mellett a szekvencia hosszúságokat a CPU-on határozzák meg és a következő batch ütemezése elindul, anélkül, hogy várnunk kellene a GPU munka leállítására.
A vázlatrétegben végzett kiegészítő munkák költségei a figyelemben nem észlelhetők, azonban az MLP rétegek problémásabbak. Mivel a mátrixmultiplikációs utasítások a tokenek számának dimenzióján 64-es határra igazítanak, ha a duplázás nem igényel lényegesen több blokkot, a költség rejtve marad. Hosszabb vázlat szekvenciák esetén költségesebb a többletmunka, és a normál vázlatcél modellek rendszer jobban működik.
Küldetés
Gyors Inferencia a Transzformátoroktól a Spekulatív Dekódoláson Keresztül
EAGLE: A Spekulatív Mintavételezés Újragondolja a Jellemzők Bizonytalanságát
EAGLE-2: Gyorsabb Inferencia a Nyelvi Modellekhez Dinamikus Vázlatfákkal
EAGLE-3: A Nagy Nyelvi Modellek Inferencia Gyorsításának Skálázása Képzésalapú Teszteléssel
Medusa: Egyszerű LLM Inferencia Gyorsító Keretrendszer Több Dekódoló Fejjel
FlashInfer: Hatékony és Testreszabható Figyelem Motor a LLM Inferencia Szolgáltatáshoz