

Written by
AI 팀
게시됨
추측을 통한 소나 가속화
추측적 디코딩은 빠르고 작은 드래프트 모델을 사용하여 완료 후보를 생성하여 대형 목표 모델에 의해 검증됨으로써 대형 언어 모델(LLMs)의 생성 속도를 가속화합니다. 이 방식에서는 비싼 목표 모델을 한 번 실행하여 단일 토큰을 생성하는 대신 여러 토큰을 한 번에 생성합니다. 여기에서는 Perplexity에서 다양한 종류의 추측적 디코딩을 적용하여 Sonar 모델의 토큰 간 지연 시간을 줄이기 위해 구현 세부 사항을 제시합니다.
추측적 디코딩
추측적 디코딩은 자연 언어의 구조와 변환기의 자가 회귀적 특성을 활용하여 토큰 생성을 가속화합니다. Llama-70B와 같은 더 큰 모델이 Llama-1B와 같은 작은 모델보다 더 많은 지식을 갖지만, 일부 간단한 작업에서는 유사한 성능을 보입니다. 이러한 겹침은 특정 시퀀스가 덜 비싼 모델에 의해 더 잘 생성되고 복잡한 문제는 더 큰 모델에 맡기는 것이 좋음을 시사합니다. 도전 과제는 어떤 완성이 더 나은지와 작은 모델의 생성이 더 큰 모델의 생성과 동일한 품질인지 판단하는 것입니다.
다행히도 LLM은 자가 회귀적 변환기입니다. 토큰 시퀀스를 제공받으면, 다음 토큰의 확률 분포를 출력합니다. 또한, 입력 시퀀스의 토큰과 관련된 중간 기능에서 파생된 로짓은 모델이 해당 토큰을 발행할 가능성이 얼마나 높은지를 나타냅니다. 이 속성을 활용하여 추측이 가능합니다. 작은 모델에서 입력 접두어를 시작으로 생성된 토큰 시퀀스는 큰 모델을 통해 실행하여 목표 모델과 얼마나 잘 일치하는지 파악할 수 있습니다. 후보의 각 접두어는 확률로 점수가 매겨지고 허용 임계값 이상인 가장 긴 접두어가 선택됩니다. 추가로 목표 모델은 한 단계에서 무료로 다음 토큰을 제공합니다: 초안 모델이 n개의 토큰을 생성하면 n + 1까지 한 번에 발행할 수 있습니다.
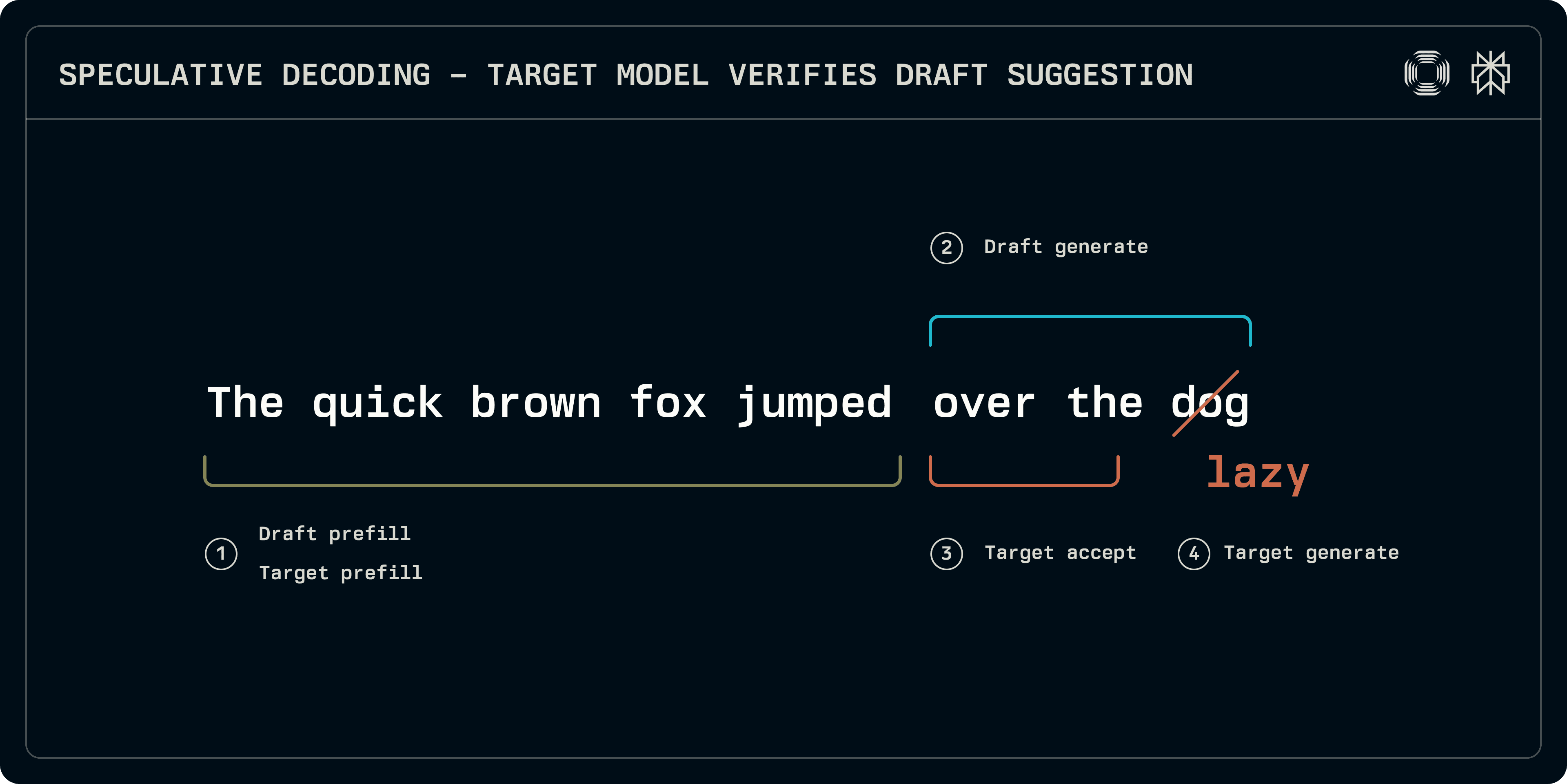
추론 시간에 추측적 샘플링 프로세스는 대략 4단계로 나눌 수 있습니다:
프리필: 목표와 초안 모델 모두 입력 시퀀스에서 KV 캐시 항목을 채우기 위해 실행되어야 합니다. Medusa와 같은 일부 체계는 예측을 위해 더 간단한 밀집 레이어를 사용하지만, 이 게시물에서는 자체 KV 캐시가 필요한 변환 기반 초안에 집중합니다.
초안 생성: 초안 모델은 고정된 수의 토큰을 생성하기 위해 반복합니다. 초안 시퀀스는 선형일 수 있으며 모델은 주어진 깊이까지의 트리와 같은 구조를 탐색할 수 있습니다 (EAGLE, Medusa). 여기서는 선형 시퀀스에 중점을 둡니다.
수용: 목표 모델이 초안 시퀀스에서 실행되어 각 초안 토큰에 해당하는 로짓을 구성합니다. 최대 수용 시퀀스의 길이가 결정됩니다.
목표 생성: 목표가 생성한 로짓에서, 시퀀스의 불일치 위치나 끝에 있는 로짓은 다음 토큰에 해당합니다. 이러한 로짓은 샘플링하여 시퀀스를 마무리하는 강력한 토큰을 제공합니다.
추측적 디코딩을 구현하기 위한 다양한 방법이 존재합니다. 이 게시물에서는 내부의 1B 모델을 사용하여 Sonar 모델을 가속화한 체계와 대규모의 모델을 가속화하기 위한 예측 메커니즘에 중점을 두겠습니다.
목표-초안
추측적 디코딩은 후보 시퀀스를 생성하기 위해 기존의 작은 LLM을 초안 모델로 목표 모델과 결합함으로써 가능해집니다. 프로덕션에서는 Llama-1B 모델을 사용하여 동일한 데이터세트로 미세 조정된 Sonar를 가속화했습니다. 이러한 접근 방식은 초안을 처음부터 훈련할 필요는 없었지만, 작은 모델도 여전히 상당한 KV 캐시 용량을 사용하고 약간의 프리필 오버헤드를 도입하여 TTFT를 증가시킵니다.
이 체계에서는 디코드 전용 배치에 대해서만 디코더가 추측을 수행하여 프리필 단계에서 표준 샘플링을 통해 토큰을 생성하거나 혼합 프리필-디코드 배치에서 수행합니다. 프리필 단계에서는 목표 로짓이 즉시 샘플링되고 초안의 KV 캐시에 새로 생성된 토큰을 사전 채웁니다. 초안은 아직 샘플링되지 않았지만, 생성한 로짓은 디코드 단계로 전달됩니다.
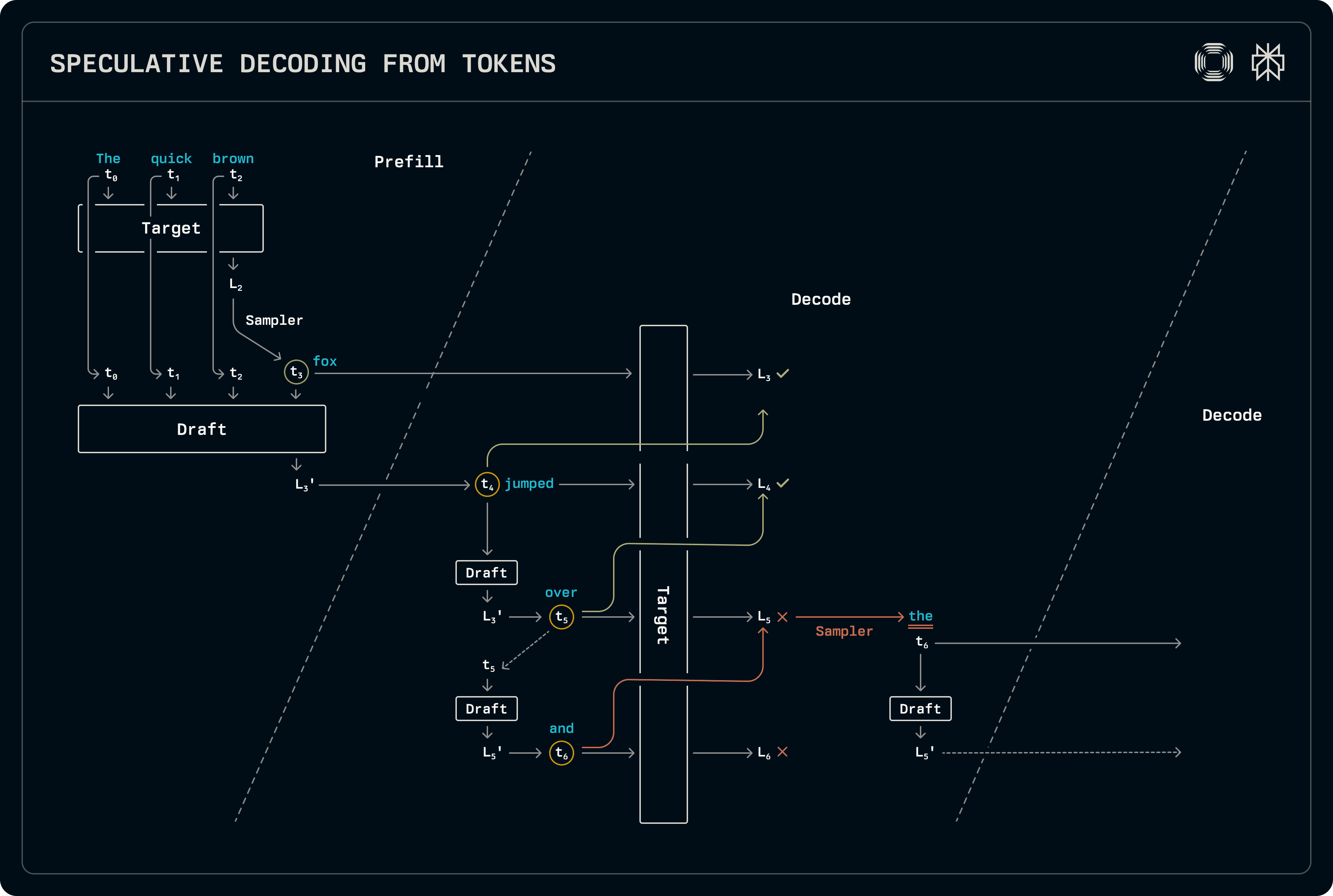
디코드에서 초안 모델은 단계를 거쳐 최고의 토큰을 샘플링하여 진행됩니다. 원하는 초안 길이에 도달하면, 토큰은 목표 모델을 통해 실행되어 샘플러가 허용된 시퀀스 길이를 식별하는 로짓을 생성합니다. 수용은 초안과 목표의 전체 확률 분포를 비교하여 결정됩니다. 목표가 항상 허용된 초안 시퀀스에 이어 단일 로짓 세트를 출력하므로, 이는 추가 출력을 생성하기 위해 샘플링됩니다. 초안 모델이 아직 해당 수용된 토큰을 보지 않았기 때문에, 다음 디코드 단계를 준비하기 위해 해당하는 KV 캐시 항목을 채우고 로짓을 다시 전송하고, 또 다시 수행합니다.
EAGLE
EAGLE은 추측적 디코딩 체계로, 트리와 같은 후보 초안 토큰 트래버설을 통해 여러 초안 시퀀스를 탐색합니다. 고정된 (EAGLE) 또는 동적으로 형성된 (EAGLE-2) 트리는 각각의 노드에서 최고 기록 토큰을 따르지 않고 Top-K 후보를 고려하여 연속적으로 초안 토큰을 실행하며 탐색됩니다. 시퀀스는 점수가 매겨지며 가장 적합한 시퀀스를 선택해 계속 진행하며, 목표에서 추가 토큰을 추가합니다.

보다 정확한 예측을 달성하기 위해, EAGLE 초안 모델은 토큰에 기반하여 예측할 뿐만 아니라 목표 모델의 특성(마지막 레이어의 숨겨진 상태)을 사용하여 예측합니다. EAGLE의 단점은 지연 시간 예산 내에 적합한 후보를 생성할 만큼 정확한 맞춤형, 작은 초안 모델을 훈련할 필요가 있다는 것입니다. 일반적으로 초안 모델은 원래 모델의 디코더 레이어와 동일한 단일 트랜스포머 레이어로, 임베딩과 lm_head 프로젝션을 연결하여 목표에 밀접하게 결합됩니다. 이 때문에 적은 KV 캐시 용량이 필요하며, EAGLE은 메모리 사용량이 적습니다.
목표 모델에서 트리와 같은 시퀀스를 확인하기 위해 맞춤형 주의를 사용해야 합니다. 불행히도 전체 시퀀스에 대해 맞춤형 주의 마스크를 사용하면 현실적인 입력 길이에 대한 주의를 크게 느리게 합니다 (최대 50% 정도 감소), 따라서 추측으로 달성할 수 있는 속도 증가를 일부 무효화합니다. 이러한 이유로 전체 트리 탐색을 프로덕션에 배포하지 않았으며, 대신 DeepSeek-V3 기술 보고서에서 제시된 MTP와 같은 스키마를 통해 생성 단일 토큰 예측의 특수한 경우에 중점을 두고 있습니다.
MTP
이 체계는 숨겨진 상태를 사용하여 토큰에 더해 예측을 수행하는 점을 제외하면 초안-목표 디코딩과 유사합니다. 정규 드래프트-목표 추측에 비해 프리필과 디코드 단계 모두에서 약간의 작업이 더 수행되어야 합니다. 초안 모델은 토큰과 숨겨진 상태를 사용합니다: 토큰 t_{i+1}는 토큰 t_i에 해당하는 숨겨진 상태 H_i에서 파생된 로짓 L_i에서 샘플링됩니다. 결과적으로 입력 토큰 버퍼는 전역 상태 벡터가 목표에 의해 출력된 상태에 비해 한 단계 왼쪽으로 이동해야 합니다. 아래 그림은 훈련 중 사용된 대응과 추론 중 이동을 표시합니다.
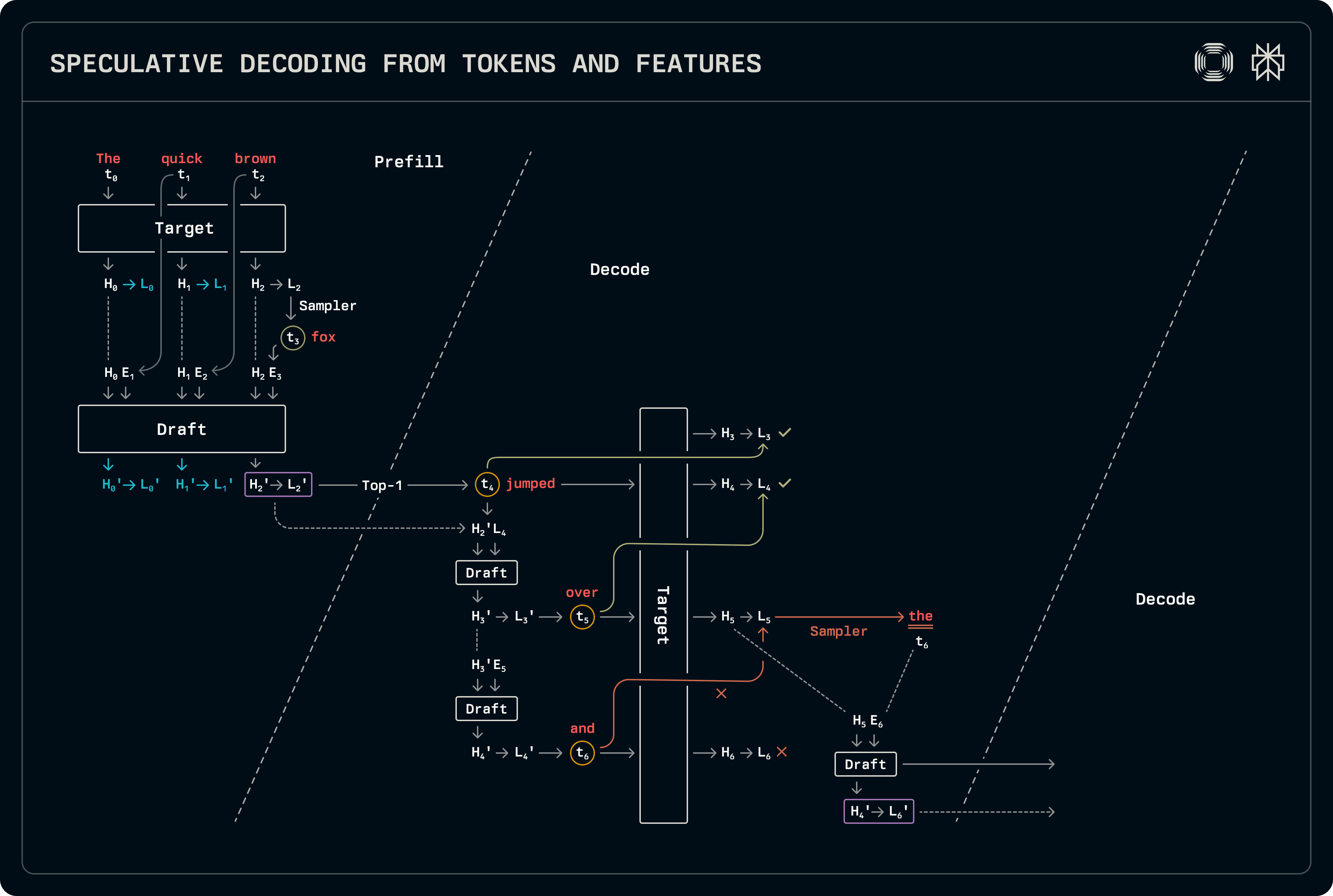
디코딩 흐름은 숨겨진 상태와 로짓이 모두 전달되는 점을 제외하면 초안-목표 디코딩과 상당히 유사합니다. 우리의 구현은 모든 관련된 샘플링과 로짓 처리를 공유하며, 모델 선행 호출만 전문화합니다. 여러 개의 토큰이 예측될 때, 초안 모델은 초안 숨겨진 상태를 사용하여 예측하며 자신의 기능에 기초하여 KV 캐시 항목도 채웁니다. 장기적으로는 이로 인해 정확도가 저하될 수 있습니다. 따라서 목표 예측을 위한 KV 캐시 항목을 채우기 위해 초안 모델을 실행할 때, 보다 정확한 목표 숨겨진 상태를 입력으로 사용하여 전체 시퀀스를 실행합니다. 이러한 초안 모델은 작기 때문에 추가 토큰을 처리하는 추가 비용은 미미합니다.
MTP 헤드 교육
MTP를 활용하기 위해, 우리는 Perplexity의 데이터세트에서 미세 조정한 모델에 부착된 MTP 헤드를 훈련하기 위한 인프라를 구축했습니다. 이 인프라는 8xH100 장치로 한 노드에서 실행됩니다. 약 하루 만에 Llama-1B에서 Llama-70B 및 DeepSeek V2-Lite 모델에 대한 헤드를 만들 수 있습니다. 더 큰 모델에 대해서는 MTP 헤드가 미세 조정 과정에서 구축됩니다.
MTP 교육의 목표는 초안 숨겨진 상태와 목표의 숨겨진 상태에서 추출한 로짓이 목표의 다음 토큰 로짓과 숨겨진 상태와 일치하도록 하는 것입니다. 숨겨진 상태에 대한 추론은 비용이 많이 들기 때문에 훈련 중에 사용할 목표 모델의 추론 최적화 구현을 사용하여 미리 계산합니다. 그러나 추론 MTP 구현을 검증하고 양자화나 최적화로 인한 수치적 차이가 결과를 방해하지 않도록 하기 위해, 검증 손실과 정확도 추정에서는 목표와 초안 모델 모두의 추론 구현을 완전히 재사용합니다.
원 본문에서 사용된 ShareGPT 데이터세트에서 대형 샘플로 확장할 때, EAGLE 논문에서 기술하고 구현한 MTP 헤드 아키텍처가 70B 크기의 모델에서는 훈련에 실패했다는 것을 알았습니다. 짧은 시퀀스가 더 많은 ShareGPT와 달리, 우리는 약간의 더 긴 프롬프트에 대해 적은 수의 시퀀스로 훈련합니다. 원래 EAGLE 헤드는 일반 변환기에서 구조적으로 약간 벗어났기 때문에 일부 RMS 정규화 계층을 다시 도입했습니다. 이를 통해 훈련이 수렴할 수 있을 뿐만 아니라 몇 퍼센트 포인트로 헤드의 정확도를 높일 수 있음을 발견했습니다.

레이어 정규화는 훈련을 용이하게 할 뿐만 아니라, 정규화를 다시 도입하는 것도 수학적으로 직관적입니다. MTP 헤드는 목표 모델의 임베딩 및 로짓 프로젝션을 재사용하며, 이는 Llama 70B의 경우 약 2GB로 상당한 크기일 수 있습니다. 훈련 중에는 이들이 고정된 상태로 있으며, MTP 레이어가 원래 모델의 프로젝션 레이어가 훈련 중에 배운 것과 동일한 벡터 공간에 예측을 포함시키는 것을 학습하는 것이 기대됩니다. 정규화를 삭제하면 단일 MLP가 정규화를 포함한 MLP와 같은 기능을 학습하도록 기대되기 때문에 초안과 목표 모델의 숨겨진 상태의 일치를 방해합니다.
추측적 디코딩을 통한 추론
추론 엔진에서 입력 시퀀스에 대한 토큰을 생성하기 위해, 이를 적절한 크기의 배치로 먼저 그룹화한 다음, 다음 토큰에 대한 KV 캐시의 페이지를 할당해야 합니다. 입력 토큰과 KV 페이지 정보는 모델을 실행하는 모든 평행 랭크에 브로드캐스트되도록 버퍼에 패킹됩니다. 마지막으로 메타데이터는 GPU 메모리로 복사되고, 모델은 다음 토큰을 샘플링하기 위한 로짓을 생성하도록 실행합니다.
초안 및 목표 추론 서버를 요청 간 조정하는 래퍼를 통해 느슨하게 결합하는 특정 구현과 달리, 우리의 초안-목표 쌍은 긴밀하게 결합되어 생성 과정에서 함께 연동됩니다. 배치 스케줄링과 KV 페이지 할당은 추측적 디코딩의 모든 형태에 대해 모델 사이에서 공유됩니다: 이는 모델을 전체 추론 서버와 연결하는 로직을 통일하며, 모두 동일한 인터페이스를 노출합니다.
Perplexity의 추론 런타임은 FlashInfer를 중심으로 형성되어 있으며, 이는 주의 커널을 구성하고 스케줄링하기 위해 구축해야 할 메타데이터를 결정합니다. 배치를 형성하는 일부 입력 시퀀스가 주어지면, 프리필, 디코드 또는 검증을 위해, CPU 측에서 중간 버퍼를 할당하고 주의에 사용되는 특정 상수 버퍼를 채워야 합니다. 이 작업은 배치 스케줄링과 KV 페이지 할당 간의 추가 비용뿐만 아니라 추가 대기 시간을 발생합니다.
우리는 추측 없이 추론을 위한 CPU 측과 GPU 측의 작업을 완전히 병렬화했지만, 추측적 디코딩에 대한 CPU-GPU 균형은 더 복잡하다는 것을 발견했습니다. 주요 문제는 수용된 토큰의 수가 후속 실행의 시퀀스 길이를 결정하기 때문에, 피할 수 없는 GPU에서 CPU로의 동기화 지점을 도입한다는 것입니다. CPU 작업의 대기 시간을 최대한 숨기기 위해 다양한 스케줄링 체계로 실험했습니다.
초안-목표 스케줄
목표 모델보다 작지만, 전체 LLM이 초안으로 사용되는 경우, 여전히 상당한 GPU 대기 시간을 초래하여 일부 비용이 큰 CPU 작업을 숨길 수 있는 여유를 제공합니다. 작은 모델은 텐서 병렬성의 이점을 누리지 못하기 때문에 목표와 초안 사이에 전송될 TP 그룹의 랭크 수에서 불일치가 발생합니다. 우리의 구현에서는 초안 모델이 TP 그룹의 리더 랭크에서만 실행됩니다.
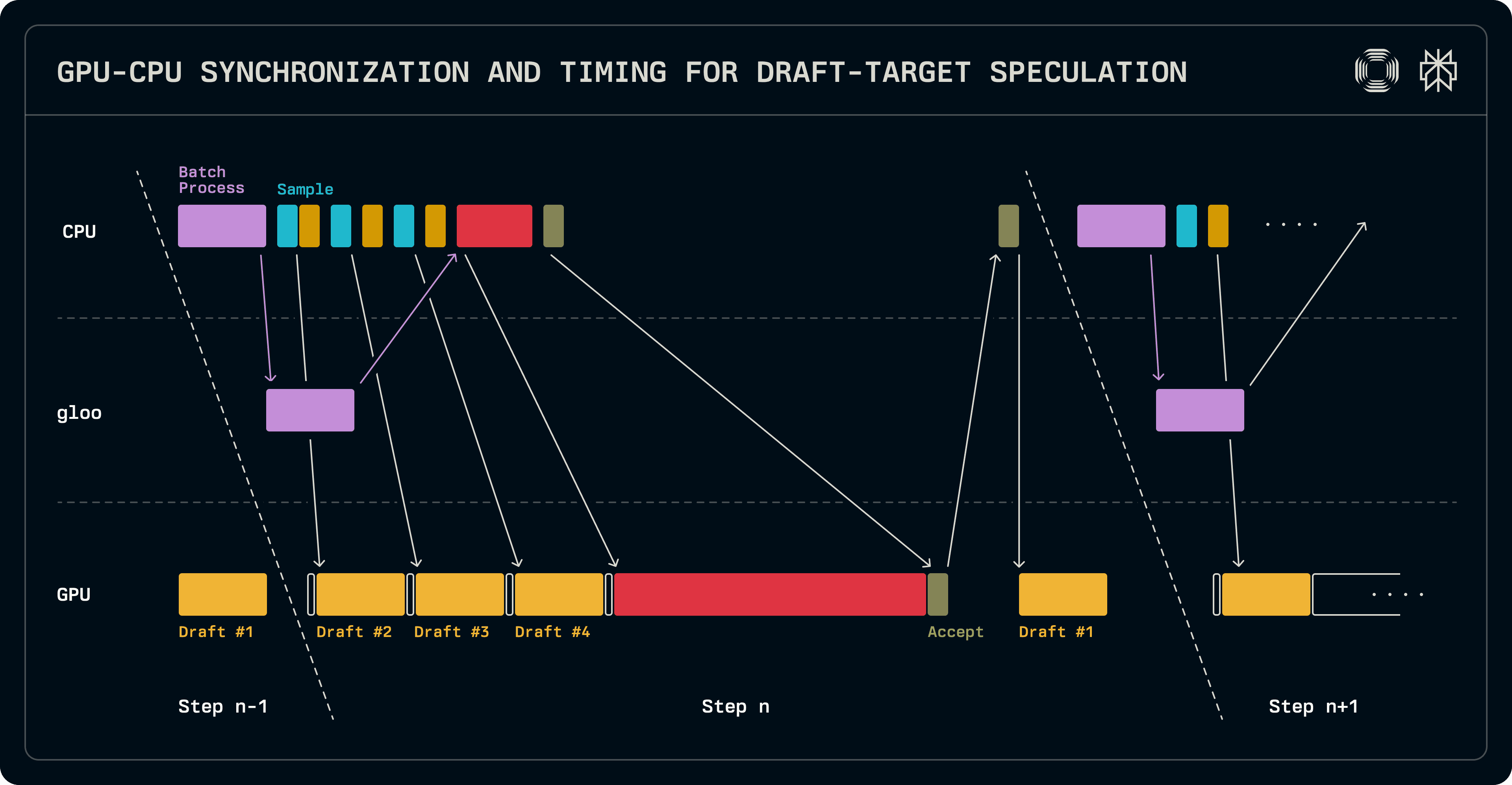
앞서 언급한 바와 같이, 디코드 단계는 다음 실행에 로짓을 전송합니다. 이는 초안 모델의 한 실행과 CPU 측 배치 스케줄링 작업을 겹치게 할 수 있습니다. 배치가 구성되면, 샘플러와 초안에서 반복 호출을 통해 초안 토큰을 생성합니다. 동시에, 목표 모델에 대한 검증용 배치가 구성되어 병렬 작업자와 동기화됩니다. 목표 로짓은 검증 및 샘플링되어 수용된 시퀀스 길이가 결정됩니다. 이 시점에서, 처리를 위한 후속 시퀀스 길이를 결정하기 위해 GPU에서 CPU로의 동기화가 필요합니다. 초안 모델은 리더 노드에서만 실행되므로, 그 배치는 순차적으로 구성되고, 실행이 시작되어 목표가 생성한 추가 토큰으로 KV 캐시 항목을 채웁니다. 현재 실행의 초안에서 생성된 로짓은 다음 실행에서 첫 번째 초안 토큰을 샘플링하는 데 사용됩니다. 무엇보다도 초안이 실행되는 동안 다음 배치를 스케줄링할 수 있습니다.
단일 토큰에 대한 MTP 스케줄링
런타임은 아직 이글 스타일 초안 트리 탐색을 제공하지 않지만, 단일 트랜스포머 디코더 레이어 크기의 모델에 의해 생성된 초안 토큰의 선형 시퀀스를 고려하는 이 스키마의 특수한 경우를 구현했습니다. 이 스키마는 DeepSeek R1의 오픈 소스 가중치를 사용하여 초안 예측에 사용할 수 있습니다. 대형 MTP 레이어는 그들의 오버헤드를 정당화할 만큼 충분히 높은 수용률을 달성하므로, 단일 토큰을 예측하는 서브케이스는 흥미롭습니다.
MTP 스케줄링은 예측된 초안 토큰이 적기 때문에, 더 적은 CPU 측 대기 시간에 대응하기 때문에, 초안 모델이 더 빠르므로 약간 더 복잡합니다. 또한, 초안은 목표 모델과 함께 샤딩되어 배치 정보에 대해 공유 메모리 전송을 요구합니다. 실행은 배치 정보를 전송하고 전송된 로짓에서 첫 번째 토큰을 샘플링하며, 이전 체계와 유사한 스미프트 방법을 진행합니다. 다음으로, 목표는 2 * D 토큰을 처리하는 데 사용되며, 여기서 D는 디코드 배치 크기입니다. 이는 인피니밴드와 같은 느린 인터커넥트를 사용하는 전문가 혼합(MoE) 모델에서 마이크로 배칭에 이상적이며, 배치는 정확히 두 부분으로 나뉩니다. 목표의 숨겨진 상태는 초안의 다음 실행으로 전달되고, 로짓은 인증을 위해 샘플러로 전달됩니다.

GPU 상에서 한정된 추가 작업을 수행하여 초안 시퀀스 수락 후 CPU에서 GPU로의 동기화를 피할 수 있습니다. 목표의 입력 토큰이 이동된 후, 커널은 다음 목표 토큰을 해당 위치에 삽입합니다. 초안은 모집단의 경우와 동일한 배치 정보를 사용하여 다시 실행되며, KV 캐시 항목을 채우고 다음 실행을 위한 로짓과 숨겨진 상태를 구축하며, 수락되지 않은 토큰에 대해 약간의 중복 작업을 수행합니다. 이러한 상황에서, 초안 모델의 크기 때문에 사용되지 않은 작업의 대기 시간은 거의 측정할 수 없습니다. 초안 실행과 병행하여 시퀀스 길이가 CPU에서 결정되고 다음 배치의 스케줄링이 시작되며, GPU 작업이 종료될 때까지 기다리지 않아도 됩니다.
초안 레이어의 추가 작업 오버헤드는 주목할만한 것이 아니지만, MLP 레이어는 더 문제가 됩니다. 매트릭스 곱셈 명령은 토큰 수의 차원에 따라 64의 경계로 패딩되며, 두 배 증가가 많은 블록을 필요로 하지 않을 경우, 오버헤드는 숨겨질 수 있습니다. 더 긴 초안 시퀀스의 경우 오버헤드는 더 비싸며, 정규 초안-목표 모델에서 사용하는 체계가 더 잘 작동합니다.
참고문헌
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving