

Geschreven door
AI-team
Gepubliceerd op
Versnelling van Sonar door Speculatie
Speculatieve decodering versnelt de generatie snelheid van Grote Taal Modellen (LLMs) door gebruik te maken van een snel en klein conceptmodel om volledige kandidaten te produceren die worden geverifieerd door het grotere doelmodel. In dit schema worden in plaats van een dure doelrun die een enkele token produceert, meerdere in één stap uitgezonden. Hier presenteren we de implementatiedetails van verschillende soorten speculatieve decodering, toegepast op Perplexity om de latentie tussen tokens te verminderen in Sonar-modellen.
Speculatieve Decodering
Speculatieve Decodering maakt gebruik van de structuur van natuurlijke talen en de auto-regressieve aard van transformatoren om de generatie van tokens te versnellen. Hoewel grotere modellen, zoals Llama-70B, meer kennis bevatten dan kleinere, zoals Llama-1B, presteren ze bij eenvoudigere taken soms vergelijkbaar. Deze overlapping suggereert dat bepaalde sequenties beter worden gegenereerd door de minder dure modellen, waardoor complexe problemen voor de grotere blijven. De uitdaging ligt in het bepalen welke voltooiingen beter zijn en of de generatie van het kleinere model van dezelfde kwaliteit is als die van het grotere.
Gelukkig zijn LLM's auto-regressieve transformatoren: wanneer ze een reeks tokens krijgen, geven ze de waarschijnlijkheidsverdeling van de volgende token. Bovendien duiden de afgeleide logits van de tussenliggende kenmerken die bij de tokens in de invoersequentie horen ook aan hoe waarschijnlijk het is dat het model die exacte tokens genereert. Deze eigenschap maakt speculatie mogelijk: als een reeks tokens door een kleiner model wordt gegenereerd te beginnen bij een invoerprefix, kan deze door het grotere model worden uitgevoerd om te bepalen hoe goed deze overeenkomt met het doelmodel. Elk prefix van de kandidaten krijgt een score met een waarschijnlijkheid en de langste boven een acceptatiedrempel wordt gekozen. Als bonus biedt het doelmodel ook een volgende token gratis: als een conceptmodel n tokens genereert, kunnen er tot n + 1 in één stap worden uitgezonden.
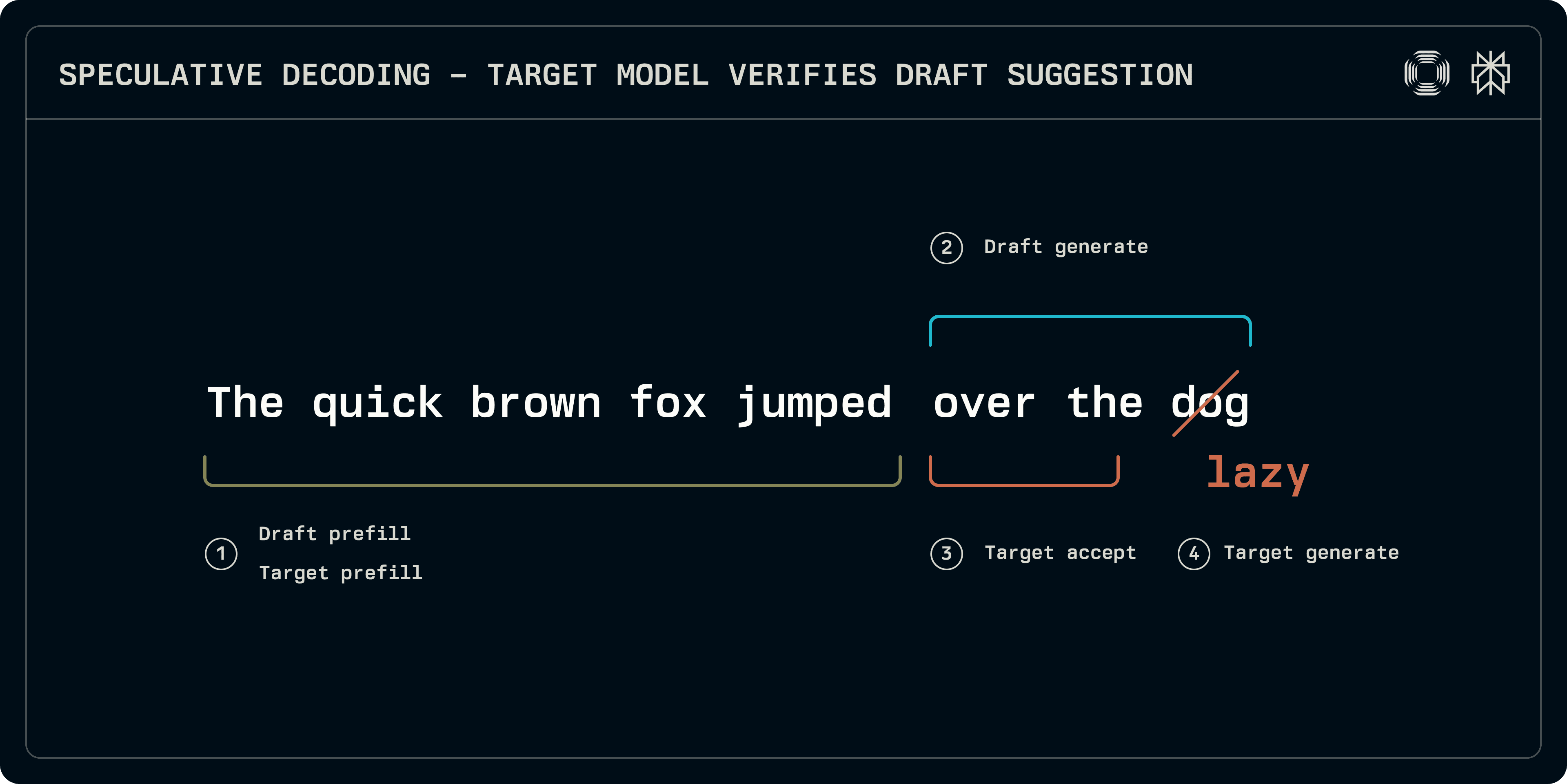
Tijdens inferentie kan het speculatieve bemonsteringsproces grofweg in vier fasen worden opgesplitst:
Prefill: zowel het doel- als het conceptmodel moeten op de invoersequentie worden uitgevoerd om de KV-cachevermeldingen te vullen. Terwijl sommige schema's, zoals Medusa, eenvoudiger dense lagen gebruiken voor voorspelling, richten we ons in dit bericht op concepten op basis van transformatoren die hun eigen KV-caches nodig hebben.
Conceptgeneratie: het conceptmodel herhaalt om een aantal vaste tokens te produceren. De conceptsequentie kan lineair zijn of het model kan een boomachtige structuur verkennen tot een bepaalde diepte (EAGLE, Medusa). Hier richten we ons op lineaire sequenties.
Acceptatie: het doelmodel draait op de conceptsequentie en bouwt logits op die corresponderen met elke concept token. De lengte van de langste acceptabele sequentie wordt bepaald.
Doelgeneratie: aangezien het doel zelf logits genereert, komen de logits bij de niet-overeenkomende positie of het einde van de sequentie overeen met een volgende token. Deze logits kunnen worden bemonsterd om een robuust token van het doel te bieden, waardoor de sequentie wordt afgerond.
Er bestaan verschillende methoden om speculatieve decodering te implementeren. In dit bericht zullen we ons concentreren op de schema's die we gebruikten om Sonar-modellen te versnellen met een interne 1B-model, evenals de voorspellingsmechanismen die we bouwen om modellen op de schaal van DeepSeek te versnellen.
Doel-Concept
Speculatieve decodering kan worden bereikt door een bestaand klein LLM als een conceptmodel te koppelen aan een doelmodel om kandidaatsequenties te genereren. In de productie hebben we Sonar versneld met een Llama-1B model dat is afgestemd op dezelfde dataset als het doel. Hoewel deze benadering geen training van een concept vanaf nul vereiste, gebruikt het kleine model nog steeds aanzienlijke KV-cachecapaciteit en introduceert een lichte overhead bij prefill, wat TTFT verhoogt.
In dit schema speculeert de decoder alleen over decode-only groepen, genereren tokens door middel van standaard bemonstering tijdens prefill of op gemengde prefill-decode groepen. In de prefill fase worden de doel-logits onmiddellijk bemonsterd om ook de nieuw gegenereerde token in de KV-cache van het concept vooraf in te vullen. Het concept wordt nog niet bemonsterd, maar de logits die het produceert worden overgedragen naar de decode fase.
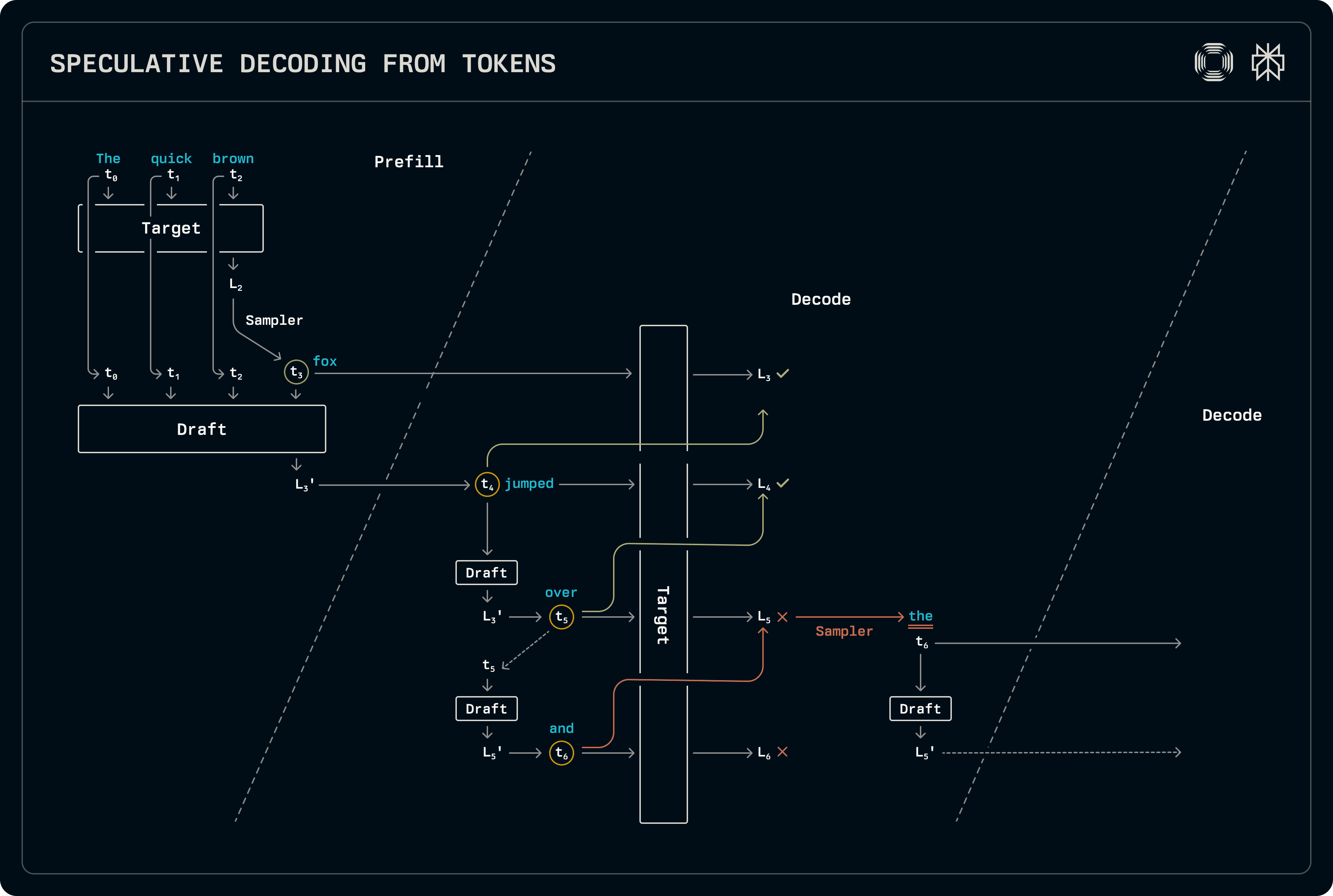
Bij decodering wordt het conceptmodel geavanceerd en bemonstert de toptoken in elke fase. Nadat de gewenste conceptlengte is bereikt, worden de tokens door het doelmodel gehaald om de logits te produceren op basis waarvan de bemonsteringssoftware de geaccepteerde sequentielengte identificeert. Acceptatie wordt bepaald door de volledige waarschijnlijkheidsverdelingen van het concept en het doel met elkaar te vergelijken. Aangezien het doel altijd een set logits uitgeeft volgend op de geaccepteerde conceptsequentie, wordt die bemonsterd om een extra output te genereren. Aangezien het conceptmodel dat geaccepteerde token nog niet heeft gezien, wordt het opnieuw uitgevoerd om de overeenkomstige KV-cachevermeldingen voor te bereiden voor de volgende decode stap, waarbij de logits opnieuw worden overgedragen.
EAGLE
EAGLE is een speculatief decodering-schema dat meerdere conceptsequenties verkent, gegenereerd door een boomachtige doorloop van waarschijnlijke concepttokens. Een vaste (EAGLE) of dynamisch gevormde (EAGLE-2) boom wordt verkend met opeenvolgende uitvoeringen van de concepttokens, waarbij de Top-K kandidaten bij elk knooppunt worden overwogen in plaats van de hoogste scorende token te volgen in een lineaire sequentie. De sequenties worden vervolgens beoordeeld en de langste geschikte wordt geselecteerd om verder te gaan, waarbij ook een extra token van het doel wordt toegevoegd.

Om nauwkeurigere voorspellingen te bereiken, voorspelt een EAGLE conceptmodel niet alleen op basis van tokens, maar ook met behulp van de doelkenmerken (laatste laag verborgen toestanden) van het doelmodel. Het nadeel van EAGLE is de noodzaak om aangepaste, kleine conceptmodellen te trainen die nauwkeurig genoeg zijn om geschikte kandidaten te genereren binnen een lage latency-budget. Meestal is een conceptmodel een enkele transformerlaag identiek aan een decoderinglaag van het originele model, die nauw is gekoppeld aan het doel door zijn embeddings en lm_head projecties te binden. Omdat dit minder KV-cachecapaciteit vereist, heeft EAGLE een lagere geheugenvoetafdruk.
Om boomachtige sequenties in het doelmodel te verifiëren, moeten aangepaste aandachtmaskers worden gebruikt. Helaas vertraagt het gebruik van een aangepast aandachtmasker voor een hele sequentie de aandacht voor realistische invoerlengtes aanzienlijk (met maximaal 50%), waardoor een deel van de versnelde snelheid door speculatie teniet wordt gedaan. Om deze reden hebben we de volledige boomexploratie nog niet in productie ingezet, waarbij we ons richten op het speciale geval van single-token voorspelling via MTP-achtige schema's gepresenteerd in het DeepSeek-V3 Technisch Rapport.
MTP
Dit schema lijkt op concept-doel decodering, met uitzondering dat verborgen toestanden naast tokens worden gebruikt voor voorspelling. Er moet iets meer worden gedaan in zowel de prefill als de decode fasen in vergelijking met reguliere concept-doel speculatie. Het conceptmodel gebruikt zowel tokens als verborgen toestanden: token t_{i+1} wordt bemonsterd van de logits L_i die horen bij token t_i, die op hun beurt zijn afgeleid van de verborgen toestanden H_i. Bijgevolg moeten de invoertokenbuffers één stap naar links worden verschoven ten opzichte van de door de doel geproduceerde verborgen toestand vectoren. De onderstaande figuur markeert de correspondenties die tijdens training worden gebruikt, evenals de verschuiving tijdens inferentie.
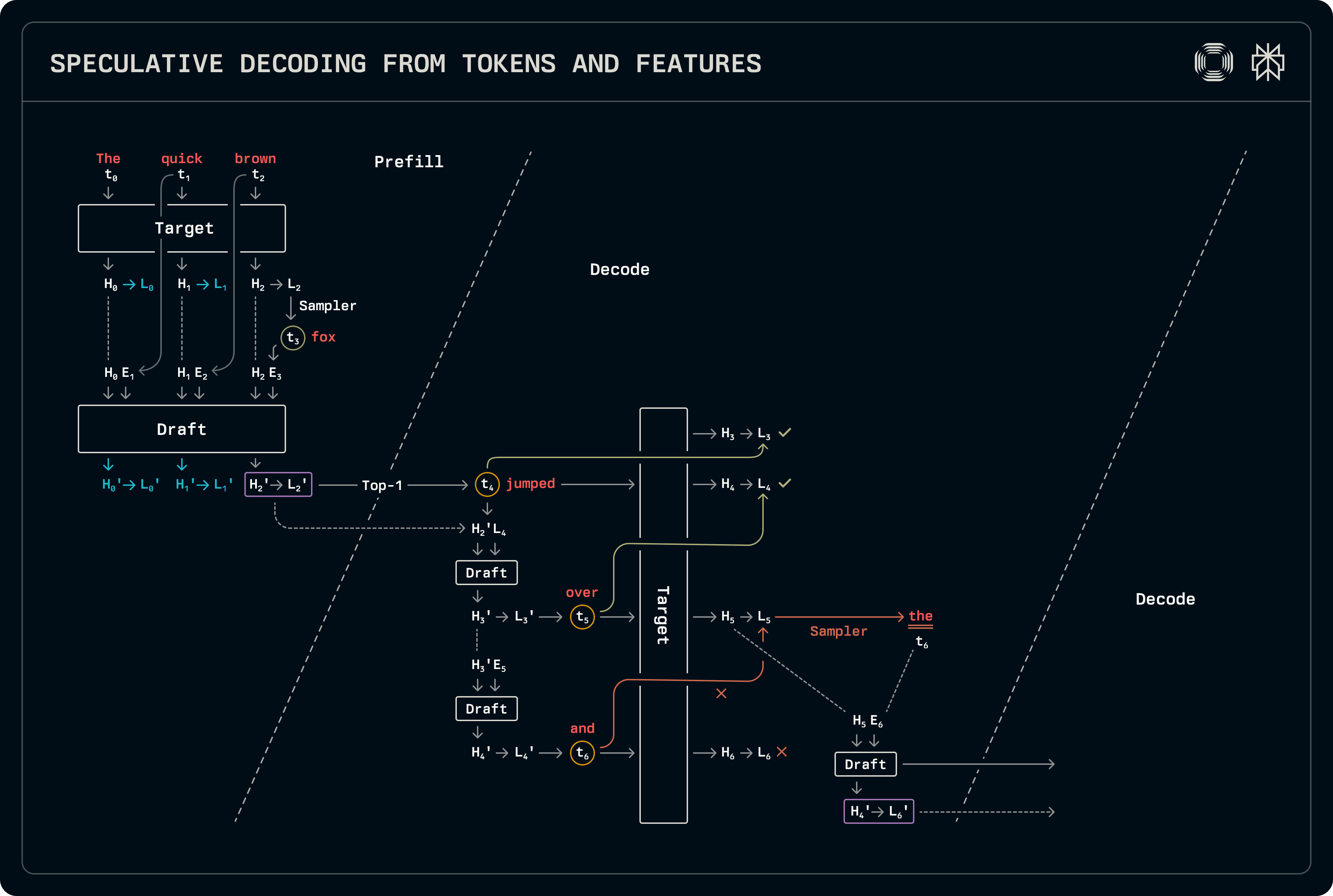
De decodering stroom is vrij gelijkaardig aan concept-doel decodering, met uitzondering dat zowel verborgen toestanden als logits worden overgedragen. Onze implementatie deelt alle bijbehorende bemonstering en logitverwerking logits, waarbij alleen de model-invocataties worden gespecialiseerd. Wanneer meerdere tokens worden voorspeld, gebruikt het conceptmodel concept-verborgen toestanden voor voorspelling, waarbij ook KV-cachevermeldingen worden gevuld op basis van zijn eigen kenmerken. Op de lange termijn kan dit de nauwkeurigheid aantasten. Vervolgens, wanneer het conceptmodel wordt uitgevoerd om de KV-cachevermelding voor de doelvoorspelling in te vullen, voeren we het uit op de hele sequentie, waarbij de nauwkeurigere verborgen toestanden van het doel als invoer worden genomen. Aangezien deze conceptmodellen klein zijn, zijn de toegevoegde kosten van het verwerken van de extra tokens verwaarloosbaar.
Training van MTP-koppen
Om van MTP te profiteren, hebben we de infrastructuur gebouwd die nodig is om MTP-koppen te trainen die zijn bevestigd aan onze fijnafgestemde modellen op de datasets van Perplexity, draaiend op één knooppunt met 8xH100-apparaten. In ongeveer een dag kunnen we koppen bouwen voor modellen variërend van Llama-1B tot Llama-70B en DeepSeek V2-Lite. Voor grotere modellen vertrouwen we op MTP-koppen die tijdens het fijnafstemmingsproces zijn gebouwd.
Het doel van MTP-training is om de concept-verborgen toestanden en de van de doel-verborgen toestanden geëxtrapoleerde logits in overeenstemming te brengen met de volgende tokenlogits en verborgen toestanden van het doel. Aangezien het inferentie voor verborgen toestanden duur is, berekenen we deze voor met behulp van onze door inferentie geoptimaliseerde implementatie van het doelmodel, om tijdens training te worden gebruikt. Om echter de inferentie MTP-implementatie te valideren en ervoor te zorgen dat numerieke verschillen door kwantisering of optimalisaties de resultaten niet beïnvloeden, gebruiken we voor validatieverlies en nauwkeurigheidschatting volledig de inferentie-implementatie van zowel de doel- als de conceptmodellen opnieuw.
Bij het opschalen vanaf de ShareGPT dataset die in het originele artikel werd gebruikt naar grotere monsters, merkten we op dat de MTP-hoofdarchitectuur beschreven en geïmplementeerd in het EAGLE-artikel niet kon trainen voor 70B-grote modellen. In tegenstelling tot ShareGPT, dat een groter aantal kortere sequenties bevatte, trainen we op een iets kleiner aantal aanzienlijk langere prompts. Aangezien de originele EAGLE-koppen enigszins afweken van een typische transformatorstructuur, hebben we enkele RMS-normalisatielagen die waren verwijderd opnieuw geïntroduceerd. We merkten dat dit niet alleen training liet samenkomen, maar ook de nauwkeurigheid van de hoofden met enkele procentpunten verhoogde.

Niet alleen vergemakkelijken laag-normen training, het opnieuw introduceren van de normen is ook wiskundig intuïtief. MTP-koppen hergebruiken de embeddings en de logitprojecties van het doelmodel, omdat ze omvangrijk kunnen zijn (ongeveer 2 GB voor Llama 70B). Tijdens training zijn deze bevroren en wordt verwacht dat de MTP-laag leert om voorspellingen in dezelfde vectorruimte te embedden als wat de projectielaag van het originele model tijdens training leerde. Door de normen te verwijderen, wordt verwacht dat een enkele MLP dezelfde functie leert als een MLP gevolgd door een norm, wat het overeenkomen tussen de verborgen toestanden van de concept- en doelmodellen belemmert.
Informatie met Speculatieve Decodering
In de inferentie-engine, om tokens voor invoerreeksen te genereren, moeten ze eerst worden gegroepeerd in redelijk grote batches, dan moeten pagina's worden toegewezen in de KV-cache voor de volgende tokens. De invoertokens en de informatie over de KV-pagina wordt vervolgens verpakt in een buffer die naar alle parallelle rangen die het model draaien wordt uitgezonden. Uiteindelijk worden de metadata gekopieerd naar het GPU-geheugen en wordt het model uitgevoerd om de logits te produceren waarvan de volgende token wordt bemonsterd.
In tegenstelling tot bepaalde implementaties die een concept- en doel-inferentieserver losjes aan elkaar koppelen via een wrapper die verzoeken tussen hen coördineert, zijn onze concept-doelparen nauw aan elkaar gekoppeld en doorlopen de generatie in eenheid. Batchplanning en KV-pagina toewijzing zijn gedeeld tussen de modellen voor alle vormen van speculatieve decodering: dit verenigt de logica die een model met de algehele inferentieserver verbindt, aangezien ze allemaal dezelfde interface blootstellen.
De inferentie-uitvoering bij Perplexity is opgebouwd rond FlashInfer, dat de metadata bepaalt die moet worden opgebouwd om de aandachtkernel te configureren en in te plannen. Gegeven enkele invoerreeksen die een batch vormen, moet voor prefill, decode of verificatie werk aan de CPU-zijde worden gedaan om tussenliggende buffers toe te wijzen en bepaalde constante buffers die in aandacht worden gebruikt te vullen. Dit werk komt bovenop de kosten van batchplanning en KV-pagina toewijzing, wat ook vertragingen met zich meebrengt die moeten worden verborgen om het GPU-gebruik te maximaliseren.
Hoewel we CPU-zijde en GPU-zijde werk voor inferentie zonder speculatie volledig hebben geparalleliseerd, ontdekten we dat de CPU-GPU balans voor speculatieve decodering meer ingewikkeld is. De grootste uitdaging is dat het aantal geaccepteerde tokens de sequentielengte voor een volgende run bepaalt, waardoor een moeilijk te vermijden GPU-naar-CPU synchronisatiepunt ontstaat. We hebben geëxperimenteerd met verschillende planningsschema's om de latentie van CPU-werk het beste te verbergen.
Concept-Doel Planning
Ondanks dat hij kleiner is dan een doelmodel, introduceert een heel LLM als concept nog steeds aanzienlijke latency op de GPU, wat enige ruimte biedt om dure CPU-bewerkingen te verbergen. Omdat kleinere modellen niet profiteren van tensor-parallelisme, is er een mismatch tussen het aantal rangen dat een doel en een concept worden gedeeld. In onze implementatie draait het conceptmodel alleen op de hoofd node van een TP-groep.
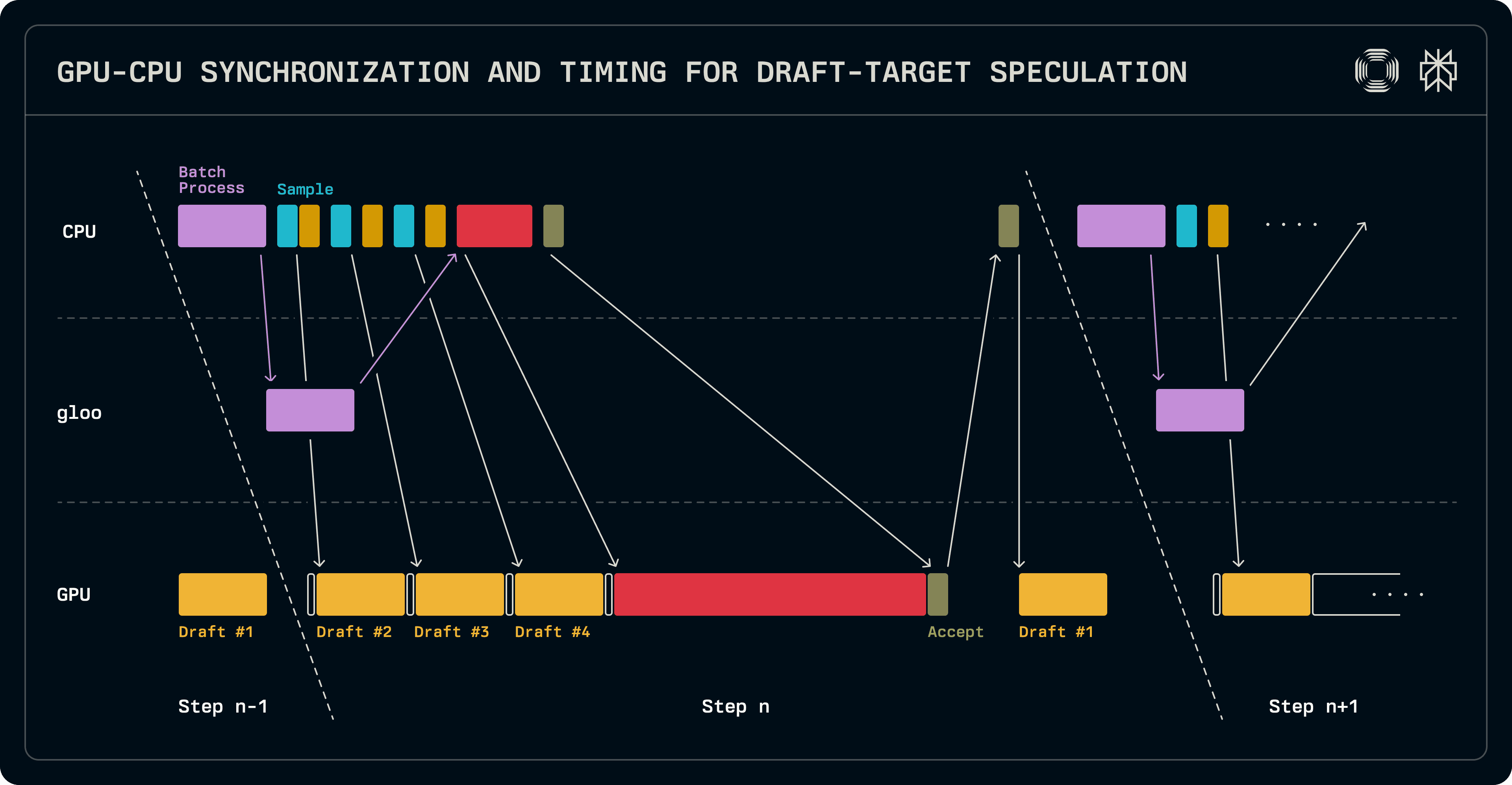
Zoals eerder aangegeven, draagt een decode stap logits over naar de volgende run. Dit stelt ons in staat om één uitvoering van het conceptmodel te overlappen met het CPU-zijde batchplanning werk. Nadat de batch is samengesteld, produceren herhaalde oproepen naar de bemonsteringssoftware en het concept de concepttokens. Parallel wordt de batch voor verificatie samengesteld voor het doelmodel en gesynchroniseerd met de parallelle werkers. De doel-logits worden geverifieerd en bemonsterd om de geaccepteerde sequentielengtes te bepalen. Op dit punt is GPU-naar-CPU synchronisatie noodzakelijk om de sequentielengten voor volgende te bepalen. Omdat het conceptmodel alleen op de hoofd node draait, wordt zijn batch sequentieel ingesteld en wordt de uitvoering gestart om zijn KV-cachevermeldingen te vullen met de extra token die het doel heeft geproduceerd. De logits die door deze concept run in de huidige run zijn geproduceerd, zullen worden gebruikt om de eerste concept token in de volgende run te bemonsteren. Het belangrijkste is dat terwijl het concept draait, de volgende batch kan worden ingepland.
MTP Planning voor een enkele Token
Hoewel de runtime nog geen Eagle-stijl conceptboomverkenning biedt, hebben we een speciaal geval van dit schema geïmplementeerd, waarbij we een lineaire sequentie van concepttokens overwegen geproduceerd door een model ter grootte van een enkele transformator-decoderlaag. Dit schema kan worden gebruikt voor conceptvoorspelling met behulp van de open-source gewichten van DeepSeek R1. Het subgeval van de voorspelling van een enkele token is interessant, aangezien grote MTP-lagen voldoende hoge acceptatiepercentages bereiken om hun overhead te rechtvaardigen.
MTP-planning is enigszins complexer, omdat het conceptmodel veel sneller is en minder latentie aan de CPU-zijde verbergt. Bovendien is het concept naast het doelmodel gedeeld, wat gedeelde geheugentransfers voor batchinformatie vereist. Een run begint met het verplaatsen van batch info en het bemonsteren van de eerste token van carry-over logits, vergelijkbaar met het vorige schema. Vervolgens wordt het doel uitgevoerd om tokens te valideren, door 2 * D tokens te verwerken, waarbij D de decode batch-grootte is. Dit is ideaal voor micro-batching in Mixture-of-Experts (MoE) modellen over langzamere interconnects zoals InfiniBand, aangezien de batch netjes in twee helften wordt gesplitst. De verborgen toestanden van het doel worden overgedragen naar de volgende conceptrun, terwijl de logits in de bemonsteringssoftware voor verificatie worden doorgegeven.

Door een beperkte hoeveelheid extra werk op de GPU uit te voeren, vermijden we CPU-naar-GPU synchronisatie na acceptatie van conceptsequenties. Nadat de invoertokens van de doelen zijn verschoven, plaatst een kernel de volgende doeltokens in hun overeenkomstige locaties in. Het concept wordt vervolgens opnieuw uitgevoerd met dezelfde batchinformatie als het doel, waarbij KV-cachevermeldingen worden gevuld en de logits en verborgen toestanden voor de volgende run worden opgebouwd, waarbij wat redundant werk wordt verricht aan tokens die niet werden geaccepteerd. In deze situaties is de latentie van het ongebruikte werk nauwelijks meetbaar vanwege de kleine omvang van het conceptmodel. Parallel aan de conceptrun worden sequentielengen op de CPU bepaald en wordt de planning van de volgende batch gestart, zonder te hoeven wachten tot GPU werk beëindigt.
De overhead van extra werk in de conceptlaag is niet merkbaar in aandacht, maar MLP-lagen zijn problematischer. Aangezien matrices vermenigvuldigingsinstructies naar een grens van 64 langs de dimensie van het aantal tokens opvullen, als verdubbeling geen aanzienlijk aantal meer blokken vereist, wordt de overhead verborgen. Voor langere conceptsequenties is de overhead duurder en werkt het schema dat wordt gebruikt voor reguliere concept-doelmodellen beter.
Referenties
Snelle Informatie uit Transformatoren via Speculatieve Decodering
EAGLE: Speculatieve Bemonstering Vereist Herziening van Functie-Onzekerheid
EAGLE-2: Snellere Informatie van Taalmodellen met Dynamische Conceptbomen
EAGLE-3: Opschalen van Informatieversnelling van Grote Taalmodellen via Training-Tijd Test
Medusa: Eenvoudig LLM Informatieversnellingskader met Meerdere Decodering-Koppen
FlashInfer: Efficiënte en Aanpasbare Aandacht Engine voor LLM Informatie Dienend