

Geschreven door
Perplexity Team
Gepubliceerd op
Search API: Betere extractie, dynamische benchmarks
In september publiceerden we een technisch overzicht van de architectuur van de Perplexity Search API en brachten we search_evals uit, ons open-source evaluatieframework voor het benchmarken van search APIs in agentic workflows. Sindsdien is de grootste investering gegaan naar snippetkwaliteit, geoptimaliseerd langs twee dimensies: relevantie en omvang. Het teruggeven van de juiste content in de juiste hoeveelheid bepaalt direct de nauwkeurigheid van downstream-antwoorden en de tokenefficiëntie. Om dat te bereiken hebben we nieuwe systemen gebouwd voor extractie, labeling op span-niveau en evaluatie, met als belangrijkste een span-labeling pipeline die bepaalt welke segmenten van een brondocument relevant zijn voor een bepaalde query.
Snippets evalueren op span-niveau
Om snippets systematisch te verbeteren, hebben we een nieuw evaluatiesysteem ontwikkeld. Voor een bepaalde query en een document identificeert en labelt het systeem spans binnen het document op basis van hun relatie tot de query: "vitale" spans die in de snippet moeten worden opgenomen, verschillende klassen van "irrelevante" spans die moeten worden uitgesloten, duplicaten en andere categorieën. Deze labeling op span-niveau stelt ons in staat om de kwaliteit van snippets te evalueren met een nauwkeurigheid die eerder niet mogelijk was, waarbij we zowel meten wat correct is opgenomen als wat correct is weggelaten.
In de praktijk zorgen deze verbeteringen ervoor dat we kleinere snippets kunnen genereren die relevanter zijn voor de query. Onze zelfverbeterende pipeline voor contentbegrip kan nu een breder scala aan structured data formats verwerken, waaronder tabellen, geneste lijsten en dynamisch gerenderde content die eerdere rulesets niet betrouwbaar konden parsen.
Deze verbeteringen kwamen voort uit onze eigen productiesystemen. Terwijl ons interne onderzoek de relevantie en omvang van snippets verder verbeterde, lieten interne evaluaties zien dat kleinere contentbudgets na een reeks kwaliteitsverbeteringen daadwerkelijk nauwkeurigere resultaten opleverden. We hebben enkele aanpassingen gedaan aan onze standaardconfiguraties om deze bevindingen te weerspiegelen, waardoor de grootte van de response payload en de latentie afnamen, terwijl er per resultaat nuttigere content werd geleverd. Voor developers vertalen kleinere, relevantere snippets zich direct naar lagere tokenkosten en beter contextbeheer voor downstream LLMs.
SEAL: benchmarking van tijdgevoelige retrieval
De SEAL-benchmark test of een retrieval-systeem vragen kan beantwoorden waarvan het juiste antwoord in de loop van de tijd verandert. Om dat betrouwbaar te doen, zijn realtime index freshness, slimmere snippetextractie uit verschillende continu bijgewerkte databronnen en parsing nodig die de actuele waarde kan herkennen in plaats van een historische.
Toen we search_evals uitvoerden op de SEAL-release van 22 februari met Claude Sonnet 4.5, stegen de scores van Perplexity terwijl die van andere aanbieders op SEAL-Hard daalden:
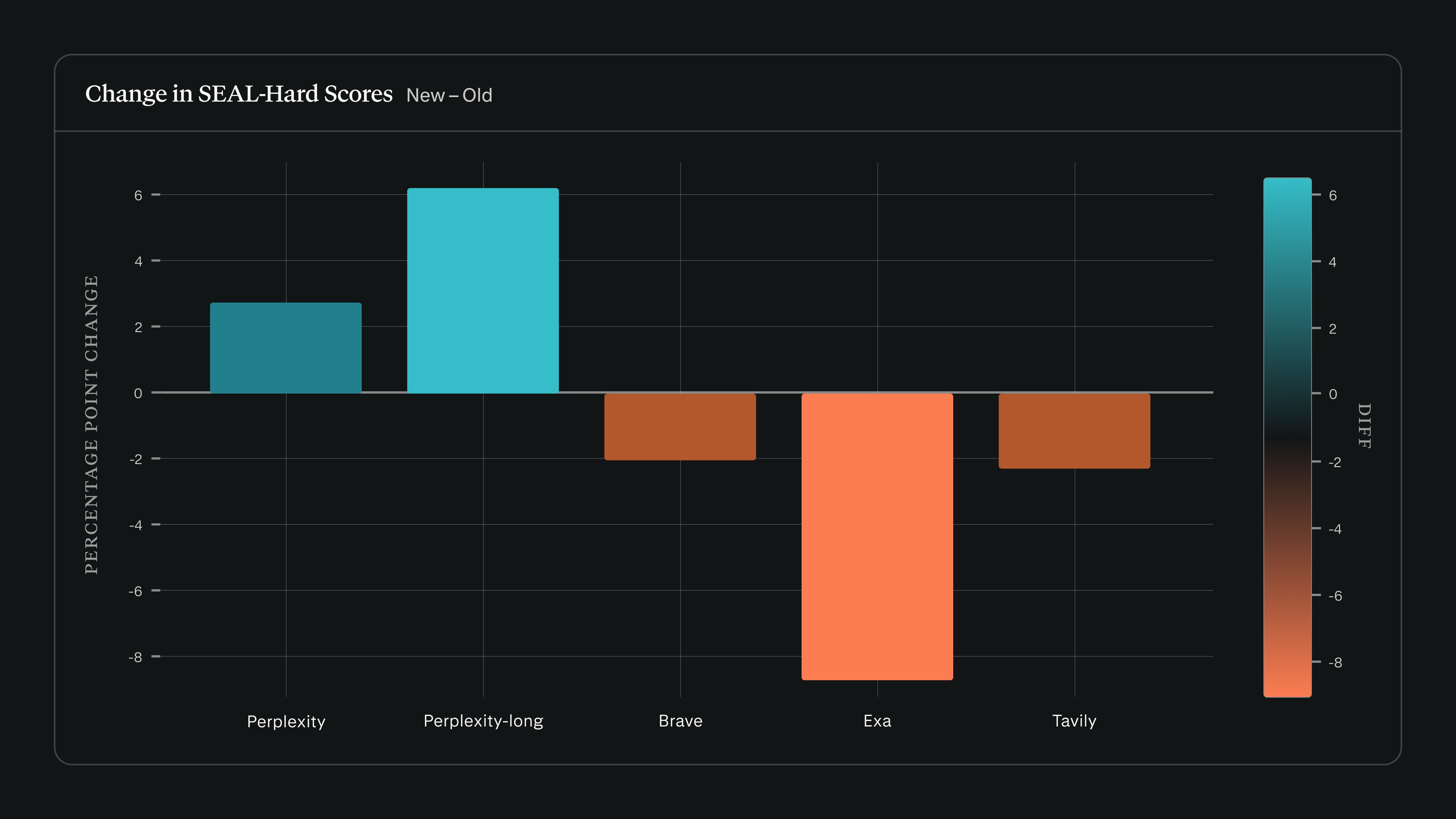
We hebben ons search_evals-framework uitgebreid met SEAL naast de benchmarks die in onze post van september zijn gerapporteerd. Bijgewerkte resultaten en methodologie zijn beschikbaar in de bijgewerkte repository op GitHub.
Ondersteuning voor meerdere queries
De API ondersteunt nu tot 5 queries in één request. Resultaten worden per query gegroepeerd teruggegeven in dezelfde volgorde als waarin ze zijn ingediend. Dit vermindert het aantal round trips voor applicaties die gerelateerde zoekopdrachten parallel moeten uitvoeren, zoals agents die een complexe vraag opdelen in meerdere retrieval-subtaken.
Uitgebreidere filtering
Naast domeinfiltering (allowlist en denylist, tot 20 domeinen) en recency filtering ondersteunt de API nu ook taalfiltering op basis van ISO 639-1-code en regionale zoekopdrachten op basis van ISO-landcode. Deze kunnen worden gecombineerd om resultaten heel precies af te bakenen, bijvoorbeeld door te beperken tot Engelstalige resultaten van Duitse domeinen.
SDK en beschikbaarheid
De Python SDK (pip install perplexityai) biedt nu native ondersteuning voor Search API naast Agent API en Sonar API.
Volledige documentatie staat op docs.perplexity.ai
Search API: Betere extractie, dynamische benchmarks
In september publiceerden we een technisch overzicht van de architectuur van de Perplexity Search API en brachten we search_evals uit, ons open-source evaluatieframework voor het benchmarken van search APIs in agentic workflows. Sindsdien is de grootste investering gegaan naar snippetkwaliteit, geoptimaliseerd langs twee dimensies: relevantie en omvang. Het teruggeven van de juiste content in de juiste hoeveelheid bepaalt direct de nauwkeurigheid van downstream-antwoorden en de tokenefficiëntie. Om dat te bereiken hebben we nieuwe systemen gebouwd voor extractie, labeling op span-niveau en evaluatie, met als belangrijkste een span-labeling pipeline die bepaalt welke segmenten van een brondocument relevant zijn voor een bepaalde query.
Snippets evalueren op span-niveau
Om snippets systematisch te verbeteren, hebben we een nieuw evaluatiesysteem ontwikkeld. Voor een bepaalde query en een document identificeert en labelt het systeem spans binnen het document op basis van hun relatie tot de query: "vitale" spans die in de snippet moeten worden opgenomen, verschillende klassen van "irrelevante" spans die moeten worden uitgesloten, duplicaten en andere categorieën. Deze labeling op span-niveau stelt ons in staat om de kwaliteit van snippets te evalueren met een nauwkeurigheid die eerder niet mogelijk was, waarbij we zowel meten wat correct is opgenomen als wat correct is weggelaten.
In de praktijk zorgen deze verbeteringen ervoor dat we kleinere snippets kunnen genereren die relevanter zijn voor de query. Onze zelfverbeterende pipeline voor contentbegrip kan nu een breder scala aan structured data formats verwerken, waaronder tabellen, geneste lijsten en dynamisch gerenderde content die eerdere rulesets niet betrouwbaar konden parsen.
Deze verbeteringen kwamen voort uit onze eigen productiesystemen. Terwijl ons interne onderzoek de relevantie en omvang van snippets verder verbeterde, lieten interne evaluaties zien dat kleinere contentbudgets na een reeks kwaliteitsverbeteringen daadwerkelijk nauwkeurigere resultaten opleverden. We hebben enkele aanpassingen gedaan aan onze standaardconfiguraties om deze bevindingen te weerspiegelen, waardoor de grootte van de response payload en de latentie afnamen, terwijl er per resultaat nuttigere content werd geleverd. Voor developers vertalen kleinere, relevantere snippets zich direct naar lagere tokenkosten en beter contextbeheer voor downstream LLMs.
SEAL: benchmarking van tijdgevoelige retrieval
De SEAL-benchmark test of een retrieval-systeem vragen kan beantwoorden waarvan het juiste antwoord in de loop van de tijd verandert. Om dat betrouwbaar te doen, zijn realtime index freshness, slimmere snippetextractie uit verschillende continu bijgewerkte databronnen en parsing nodig die de actuele waarde kan herkennen in plaats van een historische.
Toen we search_evals uitvoerden op de SEAL-release van 22 februari met Claude Sonnet 4.5, stegen de scores van Perplexity terwijl die van andere aanbieders op SEAL-Hard daalden:
We hebben ons search_evals-framework uitgebreid met SEAL naast de benchmarks die in onze post van september zijn gerapporteerd. Bijgewerkte resultaten en methodologie zijn beschikbaar in de bijgewerkte repository op GitHub.
Ondersteuning voor meerdere queries
De API ondersteunt nu tot 5 queries in één request. Resultaten worden per query gegroepeerd teruggegeven in dezelfde volgorde als waarin ze zijn ingediend. Dit vermindert het aantal round trips voor applicaties die gerelateerde zoekopdrachten parallel moeten uitvoeren, zoals agents die een complexe vraag opdelen in meerdere retrieval-subtaken.
Uitgebreidere filtering
Naast domeinfiltering (allowlist en denylist, tot 20 domeinen) en recency filtering ondersteunt de API nu ook taalfiltering op basis van ISO 639-1-code en regionale zoekopdrachten op basis van ISO-landcode. Deze kunnen worden gecombineerd om resultaten heel precies af te bakenen, bijvoorbeeld door te beperken tot Engelstalige resultaten van Duitse domeinen.
SDK en beschikbaarheid
De Python SDK (pip install perplexityai) biedt nu native ondersteuning voor Search API naast Agent API en Sonar API.
Volledige documentatie staat op docs.perplexity.ai
Deel dit artikel