

Napísané od
AI tím
Zverejnené
Urýchľovanie Sonaru prostredníctvom špekulácie
Špekulatívne dekódovanie urýchľuje rýchlosť generovania Veľkých jazykových modelov (LLMs) použitím rýchleho a malého vzorového modelu na výrobu kandidátov na dokončenie, ktoré sú overené väčším cieľovým modelom. V rámci tohto schémy, miesto nákladného behu cieľového modelu, ktorý produkuje jeden token, sa v jednom kroku vyprodukuje viac tokenov. Tu predstavujeme implementačné detaily rôznych druhov špekulatívneho dekódovania, aplikovaného na Perplexity na zníženie latencie medzi tokenmi na modeloch Sonar.
Špekulatívne dekódovanie
Špekulatívne dekódovanie využíva štruktúru prírodných jazykov a autoregresívnu povahu transformátorov na urýchlenie generovania tokenov. Hoci väčšie modely, ako Llama-70B, obsahujú viac poznatkov ako menšie, ako Llama-1B, pri niektorých jednoduchších úlohách sa správa podobne. Táto presahová podobnosť naznačuje, že niektoré sekvencie sú lepšie generované menej nákladnými modelmi, pričom zložité problémy zostávajú pre väčšie modely. Výzvou je určiť, ktoré dokončenia sú lepšie a či generovanie menšieho modelu dosahuje rovnakú kvalitu ako väčší model.
Našťastie, LLMs sú autoregresívne transformátory: keď dostanú sekvenciu tokenov, vystupujú pravdepodobnostnú distribúciu nasledujúceho tokenu. Okrem toho, logity odvodené z medzivrstiev súvisiacich s tokenmi v input sekvencii ukazujú, ako pravdepodobné je, že model vydá presne tieto tokeny. Táto vlastnosť umožňuje špekuláciu: ak je sekvencia tokenov vygenerovaná menším modelom začínajúc od input prefixu, môže byť spustená cez väčší model na určenie toho, ako dobre sa zhoduje s cieľovým modelom. Každý prefix kandidátov je ohodnotený pravdepodobnosťou a najdlhší nad akceptačným prahom je vybratý. Ako bonus, cieľový model tiež poskytuje nasledujúci token zdarma: ak vzorový model vygeneruje n tokenov, až n + 1 môže byť vyprodukovaných v jednom kroku.
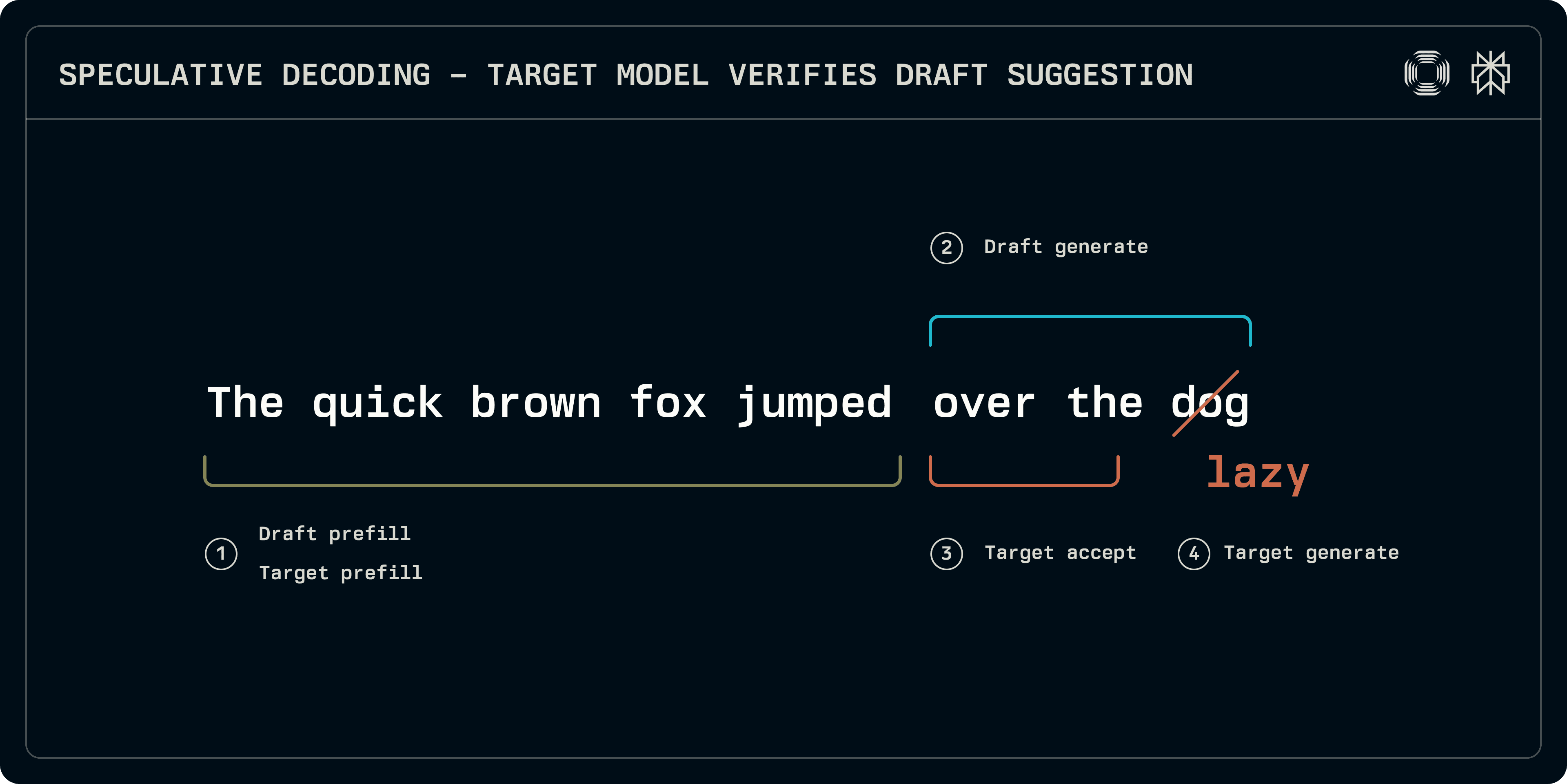
V čase inferencie je proces špekulatívneho odberu možné rozdeliť do približne 4 etáp:
Prednaplnenie: cieľový aj vzorový model musia byť spustené na vstupe sekvencie na populovanie záznamov KV cache. Zatiaľ čo niektoré schémy, ako Medusa, používajú jednoduchšie husté vrstvy na predikciu, v tomto príspevku sa zameriavame na vzory založené na transformátoroch, ktoré potrebujú svoje vlastné KV cache.
Generovanie návrhu: vzorový model iteruje na produkujúcu počet pevných tokenov. Sekvencia vzoru môže byť lineárna alebo model môže preskúmať stromovú štruktúru až do určitej hĺbky (EAGLE, Medusa). Tu sa zameriavame na lineárne sekvencie.
Akceptácia: cieľový model beží na sekvencii vzoru, budujúc logity zodpovedajúce každému vzorovému tokenu. Dĺžka najdlhšej akceptovateľnej sekvencie sa určuje.
Cieľové generovanie: keďže cieľ generoval logity, na nesúladnej pozícii alebo na konci sekvencie logity zodpovedajú nasledujúcemu tokenu. Tieto logity môžu byť odobraté na poskytnutie robustného tokenu z cieľa, čím sa uzatvára sekvencia.
Existujú rôzne metódy na implementáciu špekulatívneho dekódovania. V tomto príspevku sa zameriame na schémy, ktoré sme použili na urýchlenie modelov Sonar pomocou interného modelu 1B, ako aj na mechanizmy predikcie, ktoré budujeme na urýchlenie modelov v mierke DeepSeek.
Cieľ-Návrh
Špekulatívne dekódovanie sa dá dosiahnuť spojením existujúceho malého LLM ako vzorového modelu s cieľovým modelom na generovanie kandidátskych sekvencií. V produkcii sme urýchlili sonar pomocou modelu Llama-1B doladeného na rovnaký dataset ako cieľ. Aj keď tento prístup nevyžadoval školenie vzoru od základu, malý model stále využíva významnú kapacitu KV cache a zavádza malú preplnenosť, čo zvyšuje TTFT.
V rámci tohto schémy sa dekodér špekuluje iba na dávkach iba na dekódu, generujúc tokeny cez štandardné vzorkovanie počas preplnenia alebo na zmiešaných dávkach preplnenia-dekódovania. V etape preplnenia sú cieľové logity okamžite vzorované na preplnenie novovygenerovaného tokenu v KV cache vzoru. Vzor ešte nie je vzorovaný, ale logity, ktoré produkuje, sú prenášané do dekódovacej etapy.
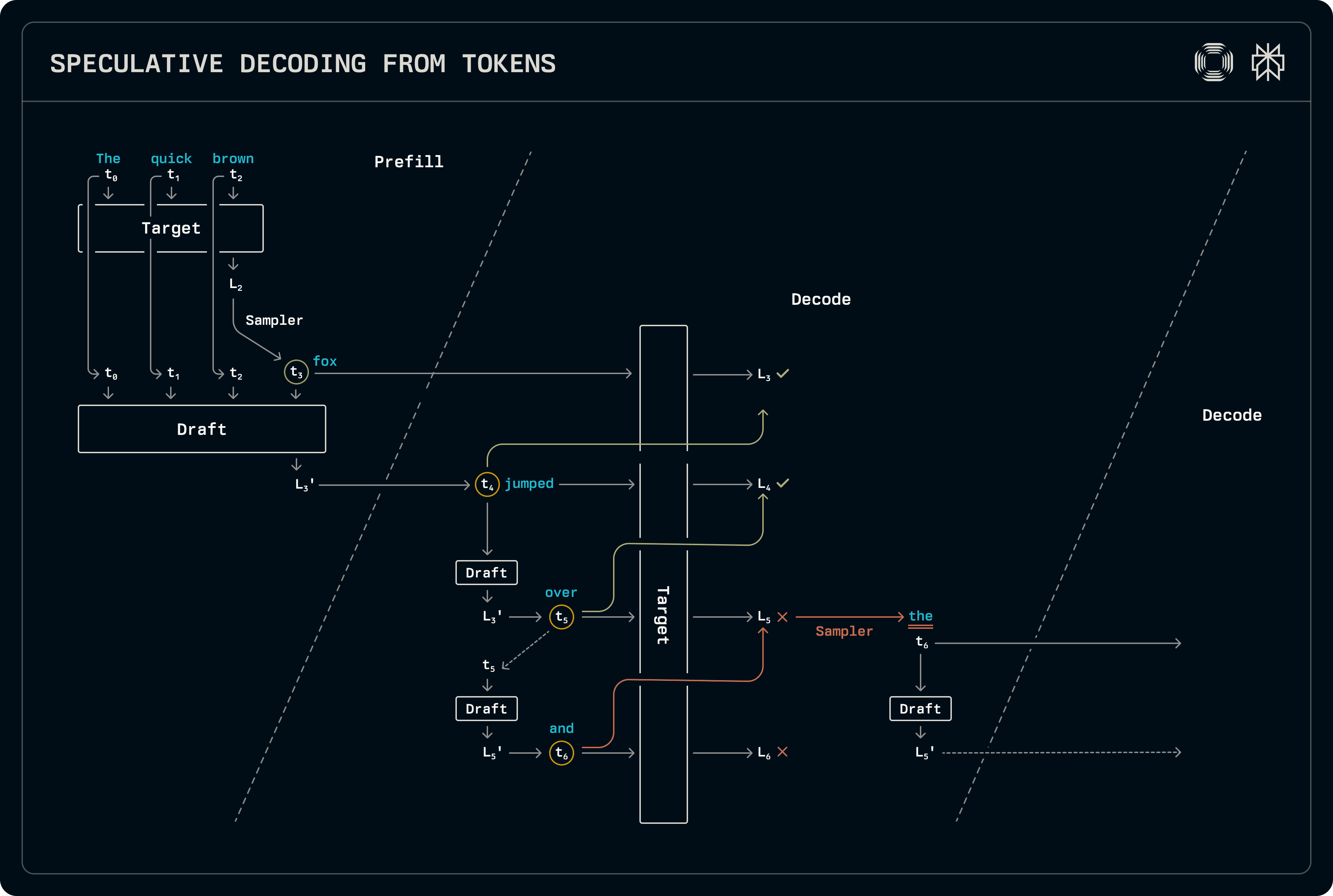
Pri dekódovaní je vzorový model pokrokový, vzorujúc najlepší token v každej etape. Po dosiahnutí požadovanej dĺžky vzoru sú tokeny vedené cez cieľový model na generovanie logitov, na základe ktorých odoberá vzorkovač akceptovanú dĺžku sekvencie. Akceptácia sa určuje porovnaním plných pravdepodobnostných distribúcií zo vzoru a cieľa. Keďže cieľ vždy vydáva jednu sadu logitov po akceptovanej sekvencii vzoru, tá je vzorovaná, aby sa vytvoril ďalší výstup. Keďže vzorový model ešte nevidel daný akceptovaný token, je spustený znova na naplnenie svojich zodpovedajúcich záznamov KV cache na prípravu na nasledujúci krok dekódovania, opäť prenášajúc logity.
EAGLE
EAGLE je schéma špekulatívneho dekódovania, ktorá preskúmava viacero vzorových sekvencií generovaných prostredníctvom stromového prechodu pravdepodobných vzorových tokenov. Fixovaný (EAGLE) alebo dynamicky tvarovaný (EAGLE-2) strom sa skúma pomocou po sebe idúcich exekúcií vzorových tokenov, pričom na každom uzle zvažujeme Top-K kandidátov namiesto sledovania najlepšieho hodnoteného tokenu v lineárnej sekvencii. Sekvencie sú potom hodnotené a najdlhší vhodný token je vybraný na pokračovanie, pričom sa tiež pridáva ďalší token z cieľa.

Aby sa dosiahli presnejšie predikcie, vzorový model EAGLE predikuje nielen na základe tokenov, ale aj pomocou cieľových rysov (posledné skryté stavy) cieľového modelu. Nevýhodou EAGLE je potreba trénovať vlastné, malé vzorové modely, ktoré sú dostatočne presné na generovanie vhodných kandidátov v rámci nízkeho rozpočtu latencie. Typicky je vzorový model jediná transformátorová vrstva identická s dekódovacou vrstvou pôvodného modelu, ktorá je tesne spojená s cieľovým modelom viazaním na jeho embeddings a lm_head projekcie. Keďže to vyžaduje menej kapacity KV cache, EAGLE má menšiu pamäťovú stopu.
Aby sa overili stromovité sekvencie v cieľovom modeli, musia byť použité vlastné masky pozornosti. Bohužiaľ, používanie vlastnej masky pozornosti pre celú sekvenciu značne spomaľuje pozornosť pre realistické dĺžky vstupov (až o 50%), čo neguje niektoré z urýchlenia dosiahnuteľného prostredníctvom špekulácie. Z tohto dôvodu sme ešte nenasadili plné preskúmanie stromu do produkcie a namiesto toho sa zameriavame na špeciálny prípad predikcie jedného tokenu prostredníctvom schém podobných MTP, predstavených v Technickej správe DeepSeek-V3.
MTP
Toto schéma je podobné dekódovaniu návrhu-cieľa, s výnimkou, že skryté stavy sú používané spoločně s tokenmi na predikciu. O niečo viac práce je potrebné vykonať v oboch etapách preplnenia a dekódovania v porovnaní s bežnou špekuláciou predikcie návrhu-cieľa. Vzorový model používa ako tokeny, tak aj skryté stavy: token t_{i+1} je vzorovaný z logitov L_i, zodpovedajúcich tokenu t_i, ktoré sú zas odvodené z skrytých stavov H_i. Dôsledkom toho musia byť vstupné tokenové buffery posunuté o jeden krok doľava vo vzťahu k skrytým stavom vektorov, ktoré vydal cieľ. Obrázok nižšie označuje zodpovednosti použité na trénovanie, ako aj posun počas inferencie.
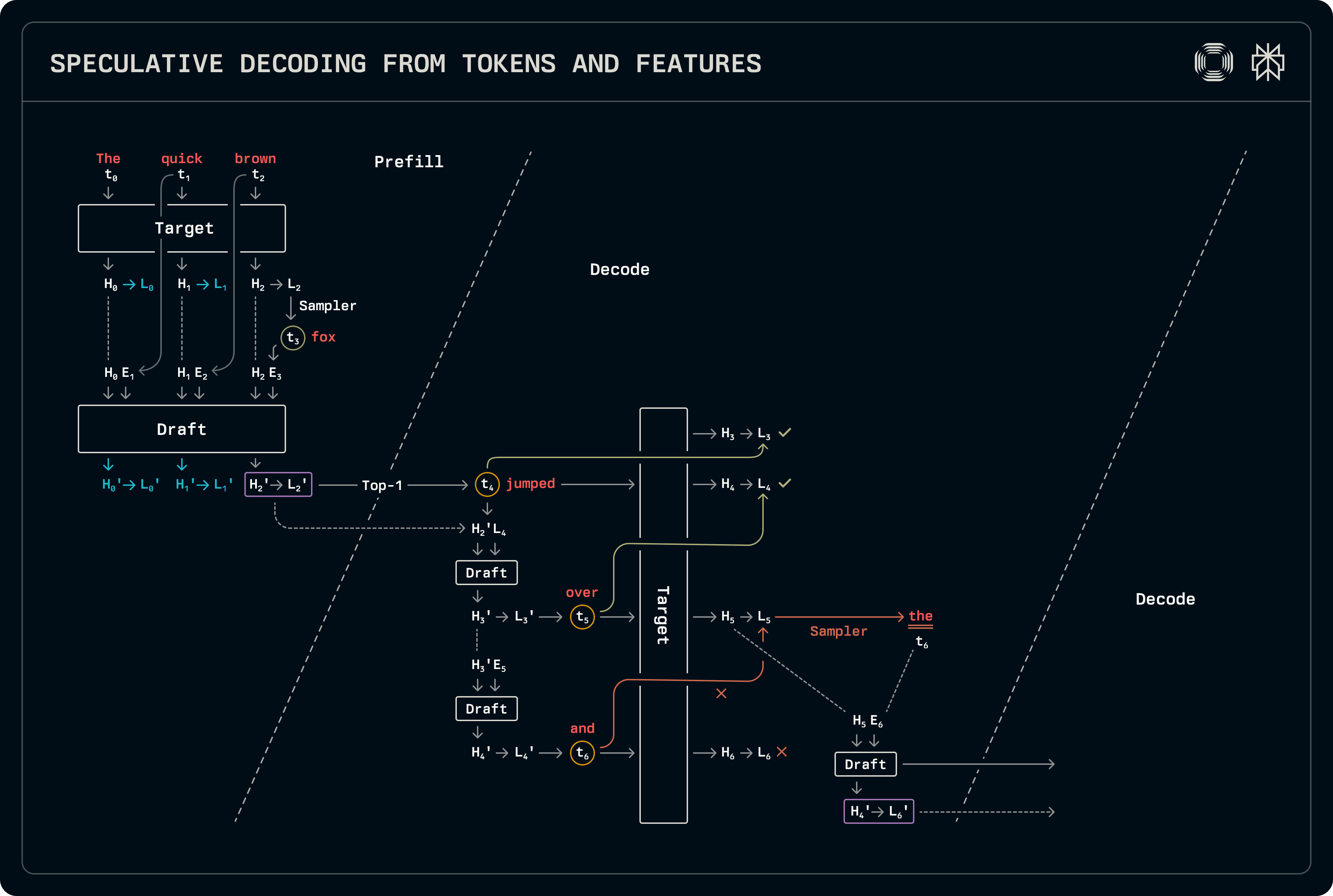
Toky dekódovania sú veľmi podobné dekódovaniu návrhu-cieľa, s výnimkou, že ako skryté stavy, tak aj logity sú prenášané. Naša implementácia zdieľa všetky súvisiace vzorkovanie a spracovanie logitov, špecializuje iba na volania dopredu modelu. Keď je predpovedaných viac tokenov, vzorový model používa skryté stavy pre vzorovanie, pričom taktiež naplňuje záznamy KV cache na základe vlastných rysov. V dlhodobom horizonte to môže znížiť presnosť. Následne, keď spúšťame vzorový model na naplnenie záznamu KV cache pre cieľovú predikciu, spúšťame ho na celej sekvencii, berúc do úvahy presnejšie skryté stavy cieľa ako vstupy. Keďže tieto vzorové modely sú malé, pridané náklady na spracovanie ďalších tokenov sú zanedbateľné.
Tréning MTP Hlav
Aby sme profitovali z MTP, vybudovali sme infraštruktúru potrebnú na trénovanie MTP hláv pripojených k našim doladeným modelom na datasetoch Perplexity, bežiacich na jednom uzle s 8xH100 zariadeniami. Za asi jeden deň môžeme vybudovať hlavy pre modely od Llama-1B po Llama-70B a DeepSeek V2-Lite. Pre väčšie modely sa spoliehame na MTP hlavy vybudované počas procesu doladenia.
Cieľom tréningu MTP je zhodnúť skryté stavy návrhu a logity extrapolované zo skrytých stavov cieľa na logity nasledujúcich tokenov a skryté stavy cieľa. Keďže inferencia pre skryté stavy je drahá, počítame ich vopred pomocou našej implementácie cieľového modelu optimalizovanej na inferenciu, aby sme ich mohli použiť počas tréningu. Avšak, na overenie implementácie inferenčného MTP a zabezpečenie toho, aby číselné rozdiely spôsobené kvantizáciou alebo optimalizáciami nebránili výsledkom, na odhadovanie validačnej straty a presnosti úplne znovu používame inferenčné implementácie cieľa aj vzorového modelu.
Pri škálovaní od datasetu ShareGPT použitých v pôvodnom článku na väčšie vzorky sme si všimli, že architektúra hláv MTP opísaná a implementovaná v EAGLE článku nebola schopná trénovať pre modely veľkosti 70B. Na rozdiel od ShareGPT, ktorý obsahoval väčší počet kratších sekvencií, trénujeme na formálne menšej, ale zásadne dlhšej výzvy. Keďže pôvodné EAGLE hlavy mierne odchyľovali v štruktúre od typického transformátora, znovu sme zaviedli niektoré vrstvy RMS Normalizácie, ktoré boli odstránené. Zistili sme, že to nielen umožnilo tréning vykonať, ale tiež to zvýšilo presnosť hláv o pár percentuálnych bodov.

Nielen vrstvy normy uľahčujú tréning, znovu zavedenie noriem je tiež matematicky intuitívne. MTP hlavy znovu používajú embeddings a logitové projekcie cieľového modelu, ako môžu byť podstatne veľké (asi 2 GB pre Llama 70B). Počas tréningu sú tieto zmrazené a očakáva sa, že MTP vrstva sa naučí zapustiť predikcie do toho istého vektorového priestoru, aký zvládol projekčný rámec pôvodného modelu počas tréningu. Odstránením noriem sa očakáva, že jeden MLP sa naučí rovnakú funkciu ako MLP nasledovaný normou, čo bráni zrovnaniu medzi skrytými stavmi vzorového a cieľového modelu.
Inferencia so špekulatívnym dekódovaním
V inferenčnom engíne, aby sa generovali tokeny pre vstupné sekvencie, musia byť najprv zoskupené do primerane veľkých dávok, potom musia byť priradené stránky v KV cache pre nasledujúce tokeny. Vstupné tokeny a informácie o stránkach KV sú potom zabalené do buffera prenášaného do všetkých paralelných úloh bežiacich model. Nakoniec je metadata skopírovaná do GPU pamäte a model je vykonaný na generovanie logitov, z ktorých je vzorovaný nasledujúci token.
Na rozdiel od niektorých implementácií, ktoré voľne spájajú vzorový a cieľový inferenčný server prostredníctvom wrapperu, ktorý orchestruje požiadavky medzi nimi, naše páry vzoru-cieľa sú tesne spojené a prechádzajú generovaním v súlade. Plánovanie dávok a priradenie strán KV je zdieľané medzi modelmi pre všetky formy špekulatívneho dekódovania: toto zjednocuje logiku, ktorá spája model s prehľadným inferenčným serverom, keďže všetky odhaľujú rovnaké rozhranie.
Runtime inferencie na Perplexity je tvarovaná okolo FlashInfer, ktorá určuje metadata, ktoré je potrebné zostaviť na nakonfigurovanie a plánovanie pozorovacieho jadra. Keď sú niektoré vstupné sekvencie utvorené dávku, pre preplnenie, dekódovanie alebo overenie, na CPU strane je potrebné vykonať roboty na pridelenie medzičlánkových buffrov a naplnenie určitých konštantných buffrov používaných v pozornosti. Táto práca je navyše ku nákladom na plánovanie dávky a priradenie strán KV, ktoré tiež spôsobujú latencie, ktoré musia byť skryté na maximálne využitie GPU.
Hoci sme plne paralelizovali roboty na CPU a GPU pri inferencii bez špekulácie, zistili sme, že vyváženie CPU-GPU pre špekulatívne dekódovanie je zložitejšie. Hlavnou výzvou je, že počet akceptovaných tokenov určuje dĺžku sekvencie pre ďalší beh, čo zavádza ťažko sa vyhnúť cebru medzi GPU a CPU. Experimentovali sme s rôznymi plánovacími schémami, aby sme skryli latenciu CPU prác.
Plánovanie Návrhu-Cieľa
Aj keď je menší ako cieľový model, keď je celý LLM použitý ako vzor, stále zavádza značnú latenciu na GPU, poskytujúc určitý priestor na skrytie nákladných operácií na CPU. Keďže menšie modely nemajú prospech z parálnej tensorovej architektúry, existuje nesúlad medzi počtom radov, na ktorých sú cielový a vzorový model rozdelené. V našej implementácii, vzorový model beží iba na vedúcom rade TP skupiny.
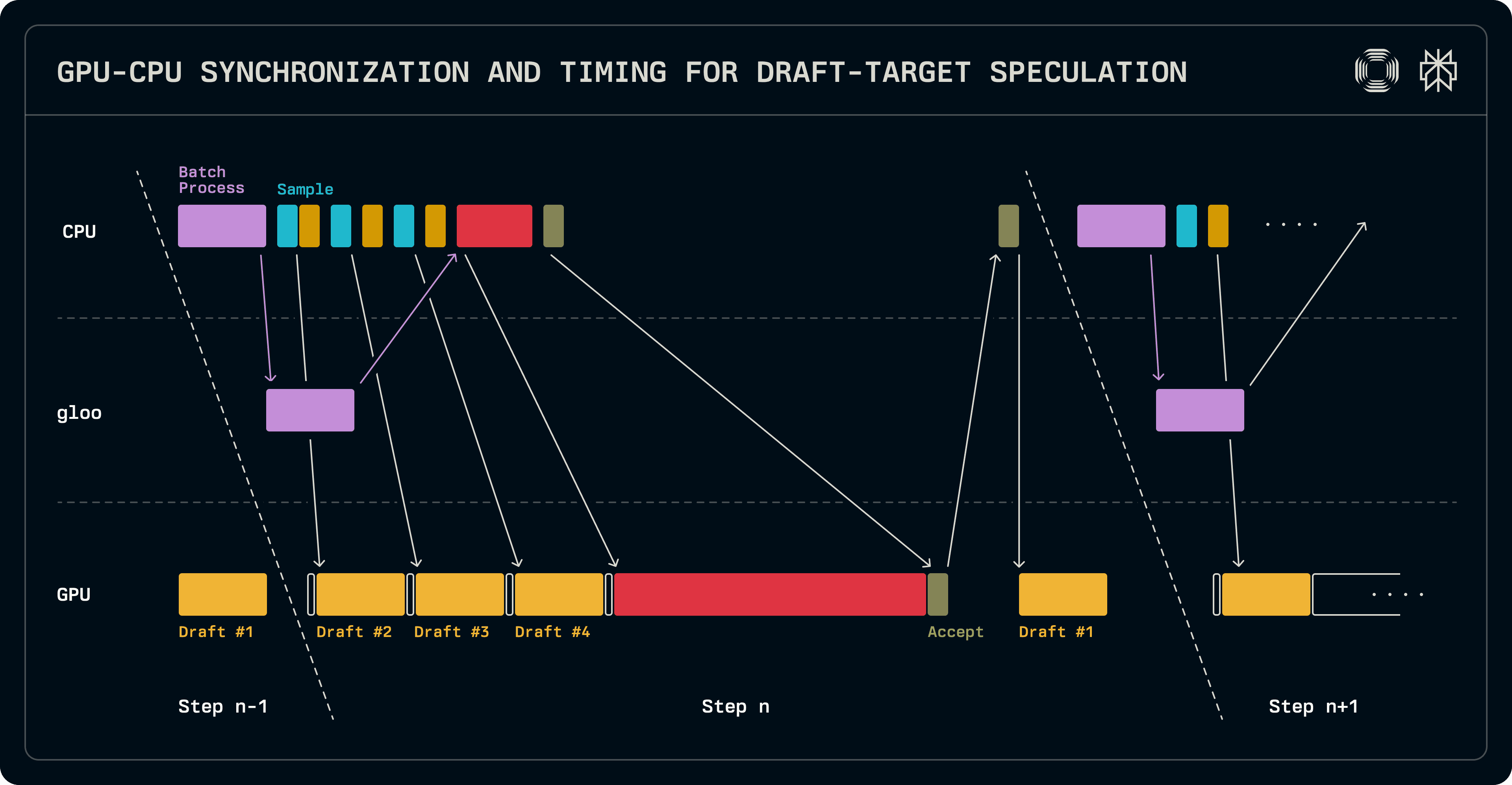
Ako bolo predtým naznačené, krok dekódovania prenáša logity do ďalšej exekúcie. Toto nám umožňuje prekrývať jeden beh vzorového modelu s prácou plánovania dávky na CPU. Po zostavení dávky opakované volania na vzorkovač a vzor produkujú vzorové tokeny. Paralelne sa zostavuje dávka na overenie cieľového modelu a synchronizuje s paralelnými pracovníkmi. Cieľové logity sú overené a vzorované na určenie akceptovaných dĺžok sekvencie. V tomto okamihu je synchronizácia medzi GPU a CPU nevyhnutná na určenie nasledujúcich dĺžok sekvencie. Keďže vzorový model sa vykonáva iba na vedúcom uzle, jeho dávka je nastavená sekvenčne a jeho exekúcia je spustená na naplnenie záznamu KV cache získať ďalší token, ktorý ciel pripravil. Logity vyrobené touto vzorovou exekúciou v súčasnom behu sa použijú na vzorovanie prvého tokenu vzoru pri nasledujúcom behu. Najdôležitejšie je, že zatiaľ čo vzor beží, môže sa naplánovať nasledujúca dávka.
Plánovanie MTP pre Jediný Token
Aj keď runtime zatiaľ neponúka preskúmanie vetvovitého stromu štýlu Eagle, implementovali sme špeciálny prípad tohto schémy, ktorý berie do úvahy lineárnu sekvenciu vzorových tokenov produkovaných modelom veľkosti jediného dekódovacieho transformátora. Toto schéma môže byť použitá na predikciu návrhu pomocou open-source váh DeepSeek R1. Sub-prípad predikcie jedného tokenu je zaujímavý, pretože veľké MTP vrstvy dosahujú dostatočne vysoké akceptačné miery, aby ospravedlnili ich overhead.
Plánovanie MTP je trochu zložitejšie, keďže vzorový model je oveľa rýchlejší, čím skryje menej latencie na CPU strane. Okrem toho, vzor je rozdelený spolu s cieľovým modelom, čo vyžaduje zdieľanie pamäte pre transféry dávkových informácií. Beh začína prenesením informácií o dávke a vzorovaním prvého tokenu z prenesených logitov, podobne ako v predchádzajúcom schéme. Následne sa cieľ spustí na overenie tokenov, spracovávajúc 2 * D tokenov, kde D je veľkosť dekódovacej dávky. Toto je ideálne pre mikro-dávkovanie v modeloch s miešaním odborníkov (MoE) cez pomalšie prepojenia, ako je InfiniBand, keďže sa dávka rozdelí na dve polovice. Skryté stavy cieľa sa prenášajú do nasledujúceho behu vzoru, zatiaľ čo logity sú predávané do vzorkovača na overenie.

Prostredníctvom vykonávania limitovaného množstva dodatočnej práce na GPU sa vyhneme synchronizácii CPU-GPU po akceptácii sekvencie vzoru. Po posunutí vstupných tokenov cieľov sa jadrá nahodia do nasledujúcich tokenov ich zodpovedajúcich miestam. Vzor je následne spustený s rovnakými informáciami o dávke ako cieľ, naplňujúc premenné KV cache a budujúc logity a skryté stavy pre ďalší beh, pričom robí niektoré nadbytočné práce na tokenoch, ktoré neboli akceptované. V týchto situáciách je latencia nezrealizovanej práce nevýznamná kvôli malej veľkosti vzoru. Paralelne s behom vzoru sú dĺžky sekvencií určované na CPU a plánovanie nasledujúcej dávky je spustené bez potreby čakať na ukončenie práce GPU.
Overhead dodatočnej práce vo vrstve vzoru nie je v pozornosti na tejto úrovni nápadný, avšak vrstvy MLP sú problematickejšie. Keďže pokyny na maticové násobenie sa zarovnávajú na hranicu 64 po dimenziách počtu tokenov, ak zdvojnásobenie nevyžaduje výrazne viac blokov, overhead je skrytý. Pri dlhších vzorových sekvenciách je overhead drahší a schéma použitá pre bežné modely vzoru-target funguje lepšie.
Odkazy
Rýchla inferencia z transformátorov prostredníctvom špekulatívneho dekódovania
EAGLE: Špekulatívne vzorkovanie si vyžaduje prehodnotiť nejasnosť rysov
EAGLE-2: Rýchlejšia inferencia jazykových modelov s dynamickými vzorovými stromami
Medusa: Jednoduchý rámec na akceleráciu inferencie LLM s viacerými dekódujúcimi hlavami
FlashInfer: Efektívny a prispôsobiteľný motor pozornosti na LLM inferenčné podávanie